
【FLink教育】FlinkCDC介绍&集成Hive
之前已经聊过了目前市面上常用的一些架构及技术选型。
- 传统数据入仓 - 离线方向
- MySQL→Sqoop→HDFS→Hive
- 传统数据入仓架构 1.0,主要使用 DataX 或 Sqoop 全量同步到 HDFS,再围绕 Hive 做数仓。
- 此方案存在诸多缺陷:容易影响业务稳定性,因为每天都需要从业务表里查询数据;天级别的产出导致时效性差,延迟高;如果将调度间隔调成几分钟一次,则会对源库造成非常大的压力;扩展性差,业务规模扩大后极易出现性能瓶颈。
- 传统数仓2.0 - 增加实时方向(Canal、dataX实时采集增量数据到Kafka上再Sink到HDFS上,最后增量全量做合并,最终还是围绕Hive)
- 分为实时和离线两条链路,实时链路做增量同步,比如通过 Canal 同步到 Kafka 后再做实时回流;
- 全量同步一般只做一次,与每天的增量在 HDFS 上做定时合并,最后导入到 Hive 数仓里。
- 此方式只做一次全量同步,因此基本不影响业务稳定性,但是增量同步有定时回流,一般只能保持在小时和天级别,因此它的时效性也比较低。同时,全量与增量两条链路是割裂的,意味着链路多,需要维护的组件也多,系统的可维护性会比较差。
- 传统数仓集成方案3.0
- MySQL/PostgreSQL→Canal/Debezium→Kafka→Flink/Spark→Ck/Hudi/Doris
- 通过 Debezium、Canal 等工具采集 CDC 数据后,写入消息队列,再使用计算引擎做计算清洗,最终传输到下游存储,完成实时数仓、数据湖的构建
- 传统 CDC ETL 分析里引入了很多组件比如 Debezium、Canal,都需要部署和维护, Kafka 消息队列集群也需要维护。Debezium 的缺陷在于它虽然支持全量加增量,但它的单并发模型无法很好地应对海量数据场景。而 Canal 只能读增量,需要 DataX 与 Sqoop 配合才能读取全量,相当于需要两条链路,需要维护的组件也增加。因此,传统 CDC ETL 分析的痛点是单并发性能差,全量增量割裂,依赖的组件较多。
- CDC方案比较

CDC 方案选择
传统CDC 方案
传统 CDC ETL架构。通过 Debezium、Canal 等工具采集 CDC 数据后,写入消息队列,再使用计算引擎做计算清洗,最终传输到下游存储,完成实时数仓、数据湖的构建。
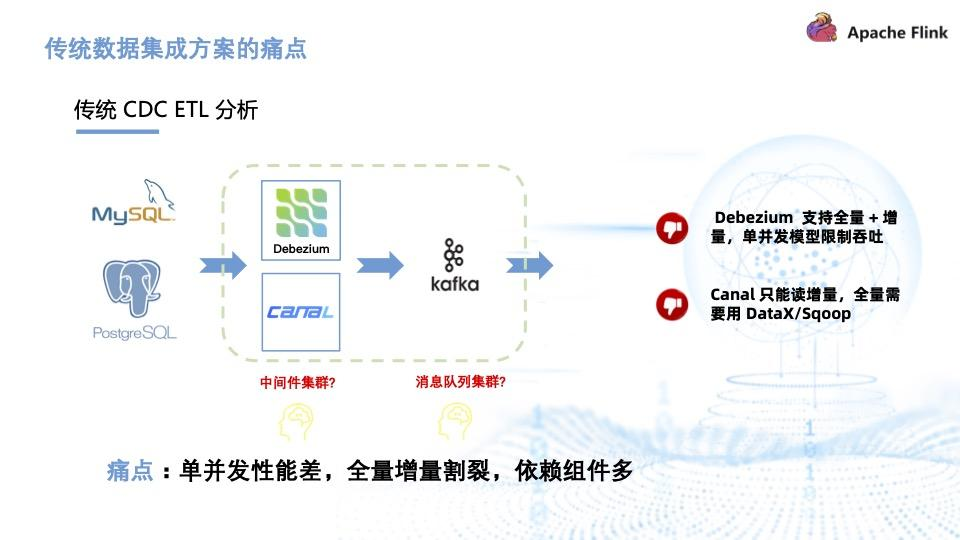
官方一直在思考是否可以使用 Flink CDC 去替换上图中虚线框内的采集组件和消息队列,从而简化分析链路,降低维护成本。同时更少的组件也意味着数据时效性能够进一步提高。答案是可以的,于是就有了基于 Flink CDC 的 ETL 分析流程。
FlinkCDC 方案

FlinkCDC 是一个纯SQL的方案,使用CDC实时读取业务数据库中的binlog日志,实现增量数据捕获。但是需要主要FlinkCDC并不能捕获到表的Schema信息发生变化的情况。表的Schema变化后,相对应的SQL也需要变更。与此同时,用户也可以利用 Flink SQL 提供的丰富语法进行数据清洗、分析和聚合。此外,利用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法可以非常容易地完成数据打宽,以及各种业务逻辑加工。
FlinkCDC 介绍
FlinkCDC概述
Flink社区开发了
flink-cdc-connectors组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。目前也已开源,开源地址:https://github.com/ververica/flink-cdc-connectorsFlink CDC 基于数据库日志的 Change Data Caputre 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。
FlinkCDC原理※
Flink SQL CDC 内置了
Debezium引擎,利用其抽取日志获取变更的能力,将changelog转换为 Flink SQL 认识的RowData数据。
主要是通过Debezium采集BinLog日志,得到类似于Json格式的字符串,JSON字符串里面有before,after,Source,op跟FlinkCDC维护的元数据信息RowKind包含的enum对象的属性刚好对应。Flink CDC 技术的核心是支持将表中的全量数据和增量数据做实时一致性的同步与加工,让用户可以方便地获每张表的
实时一致性快照。
1 | mysql> show binlog events in 'mysql-bin.000001'; |
官方解释
在Flink中RowData 代表了一行的数据,在 RowData 上面会有一个元数据的信息 RowKind,RowKind里面包括了插入(+I)、更新前(-U)、更新后(+U)、删除(-D),这样和数据库里面的 binlog 概念十分类似。
通过 Debezium 采集的数据,也有一个类似的元数据 op 字段, op 字段的取值也有四种,分别是 c、u、d、r,各自对应 create、update、delete、read。对于代表更新操作的 u,其数据部分同时包含了前镜像 (before) 和后镜像 (after)。
FlinkCDC特性
- 支持数据库级别的快照,读取全量数据,2.0版本可以支持不加锁的方式读取
- 支持 binlog,捕获增量数据
- 支持Exactly-Once
- 支持 Flink DataStream API
- 支持 Flink Table/SQL API,可使用 SQL DDL 来创建 CDC Source 表,并对表中的数据进行查询。
FlinkCDC部署及练习
开始前准备
了解与 Flink 版本的对应关系
不同的Flink版本支持的FlinkCDC版本也不一样,最好是2.0以后的版本,2.2都行。
| Flink CDC 版本 | Flink 版本 |
|---|---|
| 1.0.0 | 1.11.* |
| 1.1.0 | 1.11.* |
| 1.2.0 | 1.12.* |
| 1.3.0 | 1.12.* |
| 1.4.0 | 1.13.* |
| 2.0.* | 1.13.* |
| 2.1.* | 1.13.* |
| 2.2.* | 1.13.* , 1.14.* |
| 2.3.* | 1.13.*, 1.14.*, 1.15.*, 1.16.0 |
编译源码
一般来说,源码编译是不需要的,用户可以直接在 Flink CDC 官网下载官方编译好的二进制包或者在 pom.xml 文件中添加相关依赖即可。
以下几种情况需要进行源码编译:
➢ 用户对 Flink CDC 源码进行了修改
➢ Flink CDC 某依赖项的版本与运行环境不一致
➢ 官方未提供最新版本 Flink CDC 二进制安装包
比如,官方最新的 Flink CDC 二进制安装包是2.2版本的,而源代码已经到2.3版本了,如果想要使用2.3版本的 Flink CDC, 那么就需要自行编译了。
下面将介绍 Flink CDC 2.2 版本的编译。
下载源码
在Linux上是有yum安装Git,非常简单,只需要一行命令
1 | yum -y install git |
输入 git –version查看Git是否安装完成以及查看其版本号
1 | git --version |
下载flink cdc源码
1 | git clone https://gitee.com/zoomake/flink-cdc-connectors-master.git |
修改 pom.xml
在 pom.xml 中找到这一项:flink.version。修改 flink 版本号为:
1 | <flink.version>1.14.5</flink.version> |
编译
1 | cd /root/flink-cdc-connectors |
如果 maven 下载速度慢,可以在 pom.xml 文件加入这一段
1 | <repositories> |
DataStream 方式的应用
Mysq准备工作
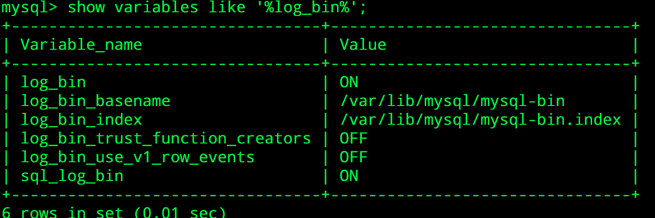
在 node1 下开启 binlog 日志,操作步骤如下:
- 登录mysql之后使用下面的命令查看是否开启binlog,代码如下:
1 | show variables like '%log_bin%'; |
- 编辑配置文件:
1 | vi /etc/my.cnf |
- 重启mysql服务
1 | systemctl restart mysqld |
- 进入mysql使用1)中的命令验证结果如图:
- 准备测试数据,执行如下代码:
1 | Drop database if exists test; |
导入依赖
1 | <properties> |
编写代码
1 | import com.ververica.cdc.connectors.mysql.source.MySqlSource; |
观察程序捕获数据的变更
在mysql的test数据库对Student表的数据,分别增删改,会观察到终端打印数据的实时变动:
增删改
1 | -- 新增数据 |
FlinkSQL 方式的应用
向3台服务器(测试节点)的Flink的lib目标下添加jar包(参见flink的 flink-lib的jar包目录)
- 将涉及Flink CDC的相关jar包(flink-sql-connector-mysql-cdc-2.2.1.jar、commons-cli-1.4)放到Flink的lib目录下.

- 启动 Flink-Cluster
1 | /export/server/flink/bin/start-cluster.sh |
- 启动HDFS
因为 flink 集群配置的 checkpoint 存储地址在 hdfs 上,所以需要启动HDFS
1 | start-dfs.sh |
- 启动 FlinkSQL-Client
1 | cd /export/server/flink/ |
- 设置表格模式(table mode),在内存中实体化结果,并将结果用规则的分页表格可视化展示出来。执行如下命令启用:
1 | SET sql-client.execution.result-mode = tableau; |
- 在FlinkSQL-Client,执行创建表 mysql_cdc_to_test_Student,代码:
1 | CREATE TABLE if not exists mysql_cdc_to_test_Student ( |
- 查询数据,实时同步mysql的对应表的数据:
1 | select * from mysql_cdc_to_test_Student; |
- 在mysql的test数据库对Student表的数据,分别增删改,会观察到FlinkSQL-Client数据的实时变动:
观察控制台捕获数据的变更
1 | -- Student表增加一行数据,在FlinkSQL-Client会看到迅速更新1条数据: |
- 查询学习 01 课程的学生及考试情况。
先创建mysql_cdc_to_test_Score表如下:
Flink CDC MySQL Connector 可通过参数 scan.startup.mode 配置启动模式。启动模式有两种:initial 和 latest-offset
- initial: 在首次启动时,对数据库的表执行初始快照,快照数据读取完成后继续读取 binlog 数据。这个模式可以得到历史到现在的所有数据。initial 是默认的启动模式。
- latest-offset: 首次启动时不执行快照,只读取 binlog 的最新数据。
- 使用场景:
- 如果需要读取全量的数据,包括历史数据和 binlog 数据则选用 initial 模式。
- 如果只需要最新的 binlog 数据,则选用 latest-offset。
1 | CREATE TABLE if not exists mysql_cdc_to_test_Score ( |
- 计算结果(Flink SQL):
查询学习 01 课程的学生及考试情况。
1 | -- 尝试自行修改 Mysql test 数据库中的 Score 表或 Student 表的数据,会在 FlinkSQL-Client 观察到查询结果的动态变化。 |
Flink CDC MySQL Connector 常用参数
参数名及含义
| 参数名 | 必填 | 默认值 | 类型 | 参数描述 |
|---|---|---|---|---|
| connector | 是 | 无 | String | 指定connector,这里填 mysql-cdc |
| hostname | 是 | 无 | String | MySql server 的主机名或者 IP 地址 |
| username | 是 | 无 | String | 连接 MySQL 数据库的用户名 |
| password | 是 | 无 | String | 连接 MySQL 数据库的密码 |
| database-name | 是 | 无 | String | 需要监控的数据库名,支持正则表达式 |
| table-name | 是 | 无 | String | 需要监控的表名,支持正则表达式 |
| port | 是 | 3306 | Integer | MySQL 服务的端口号 |
| server-id | 否 | 无 | Integer | 当开启scan.incremental.snapshot.enabled时,建议指定server-id;server-id 可以是单个值,如5400; 也可以提供数值范围,如5400-5408 |
| scan.incremental.snapshot.enabled | 否 | true | Boolean | 增量快照是读取表快照的新机制;和旧的快照读相比有以下优点:1. 并行读取 2. 支持checkpoint 3. 不需要锁表;当需要并行读取时,server-id需要设置数值范围,如5400-5408 |
| scan.incremental.snapshot.chunk.size | 否 | 8096 | Integer | 当读取表的快照时,表快照捕获的表的块大小(行数) |
| scan.snapshot.fetch.size | 否 | 1024 | Integer | 每次读表时最多拉取的记录数 |
| scan.startup.mode | 否 | initial | String | MySQL CDC 启动模式,有效值:initial 和 latest-offset |
| connect.timeout | 否 | 30s | Duration | connector 连接 MySQL 服务的最长等待超时时间 |
| connect.max-retries | 否 | 3 | Integer | connector 创建 MySQL 连接的重试次数 |
| connection.pool.size | 否 | 20 | Integer | 连接池的大小 |
Flink CDC 2.0 详解
Flink CDC 1.X 痛点
MySQL CDC 是 Flink CDC 中使用最多也是最重要的 Connector,本文下述章节描述 Flink CDC Connector 均为 MySQL CDC Connector。
总结一下 FlinkCDC1.X痛点:
- 一致性通过加锁来保证
- 不支持水平拓展, 只支持单并发
- 全量阶段不支持断点续传(没有CheckPoint机制)
全量 + 增量读取的过程需要保证所有数据的一致性,因此需要通过全局锁保证,但是加锁容易对在线业务造成影响,且 DBA 一般不给锁权限。
不支持水平扩展,因为 Flink CDC 底层是基于 Debezium,其架构是单节点,所以 Flink CDC 的数据源只支持单并发。在全量阶段读取阶段,如果表非常大 (亿级别),读取时间在小时甚至天 级别,用户无法通过增加资源去提升作业速度。
全量读取阶段不支持 checkpoint:CDC 读取分为两个阶段,全量读取和增量读取,目前全量读取阶段是不支持 checkpoint 的,因此会存在一个问题:当我们同步全量数据时,假设需要 5 个小时,当同步了 4 小时的时候作业失败,这时候就需要重新开始,再读取 5 个小时。
Debezium 锁分析
由于Flink CDC 底层封装了 Debezium, 想要深入了解FlinkCDC的痛点, 就必须知道Debezium的锁的机制.
Debezium 同步一张表分为两个阶段:
- 全量阶段:查询当前表中所有记录;
- 增量阶段:从 binlog 消费变更数据。

以全局锁为例,首先是获取一个锁,然后再去开启可重复读的事务。这里加锁范围是读取binlog 的当前位点和当前表的 schema。这样做的目的是保证 binlog 的起始位置和读取到的当前schema 是可以对应上的,因为表的 schema 是会改变的,比如删除列或者增加列。在读取这两个信息后,SnapshotReader 会在可重复读事务里读取全量数据,在全量数据读取完成后,会启动binlogReader从读取的 binlog 起始位置开始增量读取,从而保证全量数据 + 增量数据的无缝衔接。
表锁是全局锁的退化版,因为全局锁的权限会比较高,因此在某些场景,用户可能没有全局锁的权限,但是有表锁的权限。不过表锁的加锁时间会更长,因为表锁有个特征:锁提前释放了可重复读的事务默认会提交,所以锁需要等到全量数据读完后才能释放。

Flink CDC 1.x 可以不加锁,能够满足大部分场景,但牺牲了一定的数据准确性。Flink CDC 1.x 默认加全局锁,虽然能保证数据一致性,但存在上述数据库无响应(hang住)故障的风险。
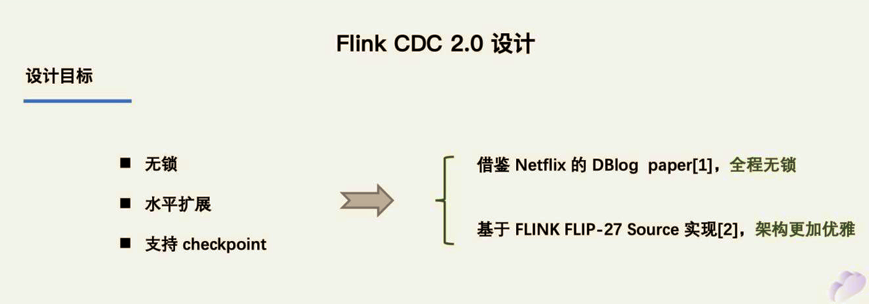
Flink CDC 2.X 设计目标 (以 MySQL 为例)
通过上面的分析,可以知道 2.0 的设计方案核心要解决上述的三个问题,即支持无锁读取、水平扩展、checkpoint。
左边是 Chunk 的切分算法描述,Chunk 的切分算法其实和很多数据库的分库分表原理类似,通过表的主键对表中的数据进行分片。假设每个 Chunk 的步长为 10,按照这个规则进行切分,只需要把这些 Chunk 的区间做成左开右闭或者左闭右开的区间,保证衔接后的区间能够等于表的主键区间即可。
右边是每个 Chunk 的无锁读算法描述,该算法的核心思想是在划分了 Chunk 后,对于每个 Chunk 的全量读取和增量读取,在不用锁的条件下完成一致性的合并。
Flink CDC 2.X设计实现
对于大部分用户来讲,其实无需过于关注如何无锁算法和分片的细节,了解整体的流程就好。
在对于有主键的表做初始化模式,整体的流程主要分为 5 个阶段:
Chunk 切分;
Chunk 分配; (实现并行读取数据&CheckPoint)
Chunk 读取; (实现无锁读取)
Chunk 汇报;
Chunk 分配。
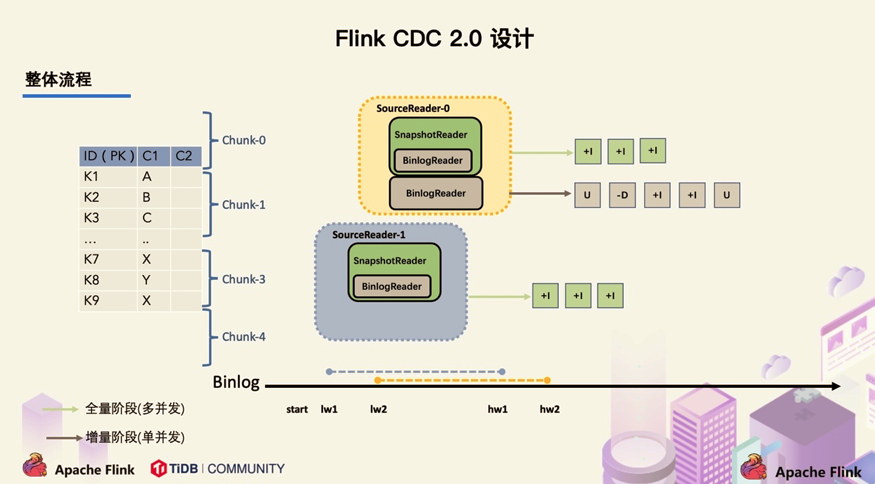
整体流程可以概括为:首先通过主键对表进行 Snapshot Chunk 划分(第一步:Chunk 切分),再将 Snapshot Chunk 分发给多个 SourceReader(第二步:Chunk 分配),每个 Snapshot Chunk 读取时通过算法实现无锁条件下的一致性读(第三步:Chunk 读取), SourceReader 读取时支持 chunk 粒度的 checkpoint, 在 Snapshot Chunk 读取完成之后,有一个汇报的流程,即 SourceReader 需要将 Snapshot Chunk 完成信息汇报给 SourceEnumerator(第四步:Chunk 汇报),在所有 Snapshot Chunk 读取完成后, 下发一个 binlog chunk 进行增量部分的 binlog 读取(第五步:Chunk 分配),这便是 Flink CDC 2.0 的整体流程。
官方测试效果:
用 TPC-DS 数据集中的 customer 表进行了测试,Flink 版本是 1.13.1,customer 表的数据量是 6500 万条,Source 并发为 8,全量读取阶段:Flink CDC 2.0 用时 13 分钟;Flink CDC 1.4 用时 89 分钟;读取性能提升 6.8 倍
使用JDBC注意事项
● 在mysql-cdc 2.x中默认开启了scan.incremental.snapshot.enabled, 如果表没有主键,则会导致增量快照读( incremental snapshot reading)失败,则需要将scan.incremental.snapshot.enabled设置为false
● 快照数据块分割采用的算法是:chunk reading algorithm ,块切分采用固定的步长,由参数scan.incremental.snapshot.chunk.size确定,默认值是:8096(行数)
针对自增的数字,则按主键从小到大进行切换
针对其它主键,则按SELECT MAX(STR_ID) AS chunk_high FROM (SELECT * FROM TestTable WHERE STR_ID > ‘uuid-001’ limit 25) 获取切换的范围
每个chunk reader执行Offset Signal Algorithm以获得快照块的最终一致输出
● 如果需要并行运行,每个并行Reader应该有一个唯一的服务器id,所以’ server-id ‘必须是’ 5400-6400 ‘这样的范围,并且范围必须大于并行度 (并行度通过 SET ‘parallelism.default’ = 8; 设置)。
Flink集成Hive
Flink集成Hive
Flink 与 Hive 的集成主要体现在以下两个方面:
- 持久化元数据
Flink利用Hive的MetaStore作为持久化的Catalog,可通过Hive Catalog将不同会话中的 Flink元数据存储到Hive MetaStore 中。
- 读写 Hive 的表
Flink与Hive的集成,如同使用SparkSQL或者Impala操作Hive中的数据一样,我们可以使用Flink直接读写Hive中的表。
支持的Hive版本
对于不同的Hive版本,可能在功能方面有所差异,这些差异取决于你使用的Hive版本,而不取决于Flink,一些版本的功能差异如下:
- Hive 内置函数在使用 Hive-1.2.0 及更高版本时支持。
- 列约束,也就是 PRIMARY KEY 和 NOT NULL,在使用 Hive-3.1.0 及更高版本时支持。
- 更改表的统计信息,在使用 Hive-1.2.0 及更高版本时支持。
- DATE列统计信息,在使用 Hive-1.2.0 及更高版时支持。
- 使用 Hive-2.0.x 版本时不支持写入 ORC 表。
集成Hive的方式
要与 Hive 集成,您需要在
Flink 下的/lib/目录中添加一些额外的依赖包, 以便通过 TableAPI 或 SQL Client 与 Hive 进行交互。 或者,您可以将这些依赖项放在专用文件夹中,并分别使用 Table API 程序或 SQL Client 的-C或-l选项将它们添加到 classpath 中。
- Apache Hive 是基于 Hadoop 之上构建的, 首先您需要 Hadoop 的依赖,进行如下配置:
2
export HADOOP_CLASSPATH=`hadoop classpath`
- 使用 Flink 提供的 Hive jar:
Flink1.14.5集成Hive只需要添加如下三个jar包,以Hive3.12为例,分别为:
2
3
flink-connector-hive_2.12-1.14.5.jar (2.12为scala版本)
hive-exec-3.1.2.jar (存在于Hive安装路径下的lib文件夹)
Hive Catalog
Hive Catalog的主要作用是使用Hive MetaStore去管理Flink的元数据。Hive Catalog可以将元数据进行持久化,这样后续的操作就可以反复使用这些表的元数据,而不用每次使用时都要重新注册。
配置Hive Catalog
为了避免每次打开客户端后,手动创建Hive Catalog,可以将配置写到文件中,每次启动时直接指定配置文件即可。
- 配置sql-conf.sql
创建sql-conf.sql文件,该文件是Flink SQL Cli启动时使用的配置文件,将该文件放到Flink安装目录flink/conf/下,具体的配置如下,主要是配置catalog:
1 | CREATE CATALOG myhive WITH ( |
使用Hive Catalog
Hive Catalog可以处理两种类型的表:一种是Hive兼容的表,另一种是普通表(generic table)。
Hive兼容表是以兼容Hive的方式来存储的,所以,对于Hive兼容表而言,既可以使用Flink去操作该表,又可以使用Hive去操作该表。
普通表是对Flink而言的,当使用Hive Catalog创建一张普通表,仅仅是使用Hive MetaStore将其元数据进行了持久化,所以可以通过Hive查看这些表的元数据信息(通过DESCRIBE FORMATTED命令),但是不能通过Hive去处理这些表,因为语法不兼容。
Hive Dialect
Flink 目前支持两种 SQL 方言:
default和hive。从 1.11.0 开始,在使用Hive方言时,Flink允许用户用Hive语法来编写SQL语句。通过提供与Hive 语法的兼容性,旨在改善与 Hive 的互操作性,并减少用户需要在 Flink 和 Hive 之间切换来执行不同语句的情况。
Flink读写Hive
写入Hive表
Flink支持以批处理(Batch)和流处理(Streaming)的方式写入Hive表。
当以批处理的方式写入Hive表时,只有当写入作业结束时,才可以看到写入的数据。
- 批处理模式写入
支持append追加数据和overwrite覆盖数据
1 | 使用批处理模式 |
- 流处理模式写入
流式写入Hive表,不支持Insert overwrite方式
1 | 使用流处理模式 |
流处理写入涉及的相关参数:
- partition.time-extractor.timestamp-pattern
默认值:(none)
解释:分区时间抽取器,与 DDL 中的分区字段保持一致,如果是按天分区,则可以是$dt,如果是按年(year)月(month)日(day)时(hour)进行分区,则该属性值为:$year-$month-$day $hour:00:00,如果是按天时进行分区,则该属性值为:$day $hour:00:00。
- sink.partition-commit.trigger
默认值:process-time
解释:分区触发器类型,可选 process-time 或partition-time。
process-time:不需要时间提取器和水位线,当当前时间大于分区创建时间 +sink.partition-commit.delay 中定义的时间,提交分区;
partition-time:需要 Source 表中定义 watermark,当 watermark > 提取到的分区时间 +sink.partition-commit.delay 中定义的时间,提交分区;
- sink.partition-commit.delay
默认值:0S
解释:分区提交的延时时间,如果是按天分区,则该属性的值为:1d,如果是按小时分区,则该属性值为1h。默认值是0s,即一旦分区中有数据,它将立即提交。注意:该分区可能被提交多次。
- sink.partition-commit.policy.kind
默认值:(none)
解释:提交分区的策略,用于通知下游的应用该分区已经完成了写入,也就是说该分区的数据可以被访问读取。可选的值如下:可以同时配置上面的两个值,比如metastore,success-file。
metastore:添加分区的元数据信息,仅Hive表支持该值配置。
success-file:在表的存储路径下添加一个_SUCCESS文件。
读取Hive表
Flink支持以批处理(Batch)和流处理(Streaming)的方式读取Hive中的表。批处理的方式与Hive的本身查询类似,即只在提交查询的时刻查询一次Hive表。流处理的方式将会持续地监控Hive表,并且会增量地提取新的数据。默认情况下,Flink是以批处理的方式读取Hive表。
关于流式读取Hive表,Flink既支持分区表又支持非分区表。对于分区表而言,Flink将会监控新产生的分区数据,并以增量的方式读取这些数据。对于非分区表,Flink会监控Hive表存储路径文件夹里面的新文件,并以增量的方式读取新的数据。
Flink读取Hive表可以配置一下参数:
- streaming-source.enable
默认值:false
解释:是否开启流式读取 Hive 表,默认不开启。- streaming-source.partition.include
默认值:all
解释:配置读取Hive的分区,包括两种方式:all和latest。all意味着读取所有分区的数据,latest表示只读取最新的分区数据。值得注意的是,latest方式只能用于开启了流式读取Hive表,并用于维表JOIN的场景。- streaming-source.monitor-interval
默认值:None
解释:持续监控Hive表分区或者文件的时间间隔。值得注意的是,当以流的方式读取Hive表时,该参数的默认值是1m,即1分钟。当temporal join时,默认的值是60m,即1小时。另外,该参数配置不宜过短 ,最短是1 个小时,因为目前的实现是每个 task 都会查询metastore,高频的查可能会对metastore 产生过大的压力。- streaming-source.partition-order
默认值:partition-name
解释:streaming source的分区顺序。分区表默认的是partition-name,表示使用默认分区名称顺序加载最新分区,也是推荐使用的方式。除此之外还有两种方式,分别为:create-time和partition-time。其中create-time表示使用分区文件创建时间顺序。partition-time表示使用分区时间顺序。指的注意的是,对于非分区表,该参数默认值为:create-time。- partition.time-extractor.kind
默认值:default
分区时间提取器类型。用于从分区中提取时间,支持default和自定义。如果使用default,则需要通过参数partition.time-extractor.timestamp-pattern配置时间戳提取的正则表达式。对于自定义,应该配置提取器类- streaming-source.consume-start-offset
默认值:None
解释:流式读取Hive表的起始偏移量。
Hive维表Join
Flink支持的是processing-time的temporal join,Flink既支持非分区表的temporal join,又支持分区表的temporal join。对于分区表而言,Flink会监听Hive表的最新分区数据。值得注意的是,Flink尚不支持 event-time temporal join。
- Temporal Join最新分区
如果Hive分区表的每个分区都包含全量的数据,那么每个分区将做为一个时态表的版本数据,即将最新的分区数据作为一个全量维表数据。该功能仅支持Flink的streaming模式。
1 | 注意:使用 Hive 最新分区作为Tempmoral table之前,需要设置必要的参数 |
- Temporal Join最新表
对于Hive的非分区表或者全量的分区表,当使用temporal join时,整个Hive表会被缓存到Slot内存中,然后根据流中的数据对应的key与其进行匹配。
对于有界表:streaming-source.enable = false
lookup.join.cache.ttl
默认值:60min
解释:表示缓存时间。由于 Hive 维表会把维表所有数据缓存在 TM 的内存中,当维表数据量很大时,很容易造成 OOM。当然TTL的时间也不能太短,因为会频繁地加载数据,从而影响性能。当使用此种方式时,Hive表必须是有界表,即非Streaming Source的时态表,换句话说,该表的属性streaming-source.enable = false。
对于无界表:streaming-source.enable = true
需要设置streaming-source.monitor-interval的值,即数据更新的时间间隔。
对于分区表,还需要设置streaming-source.partition.include为 all。
 微信
微信 支付宝
支付宝