
【Flink】FlinkSQL| 状态编程| 自定义函数
Flink 中的状态编程
在 Flink 中,算子任务可以分为无状态和有状态两种情况。
在传统的事务型处理架构中,这种额外的状态数据是保存在数据库中的。而对于实时流处理来说,这样做需要频繁读写外部数据库,如果数据规模非常大肯定就达不到性能要求了。所以 Flink 的解决方案是,将状态直接保存在内存中来保证性能,并通过分布式扩展来提高吞吐量。
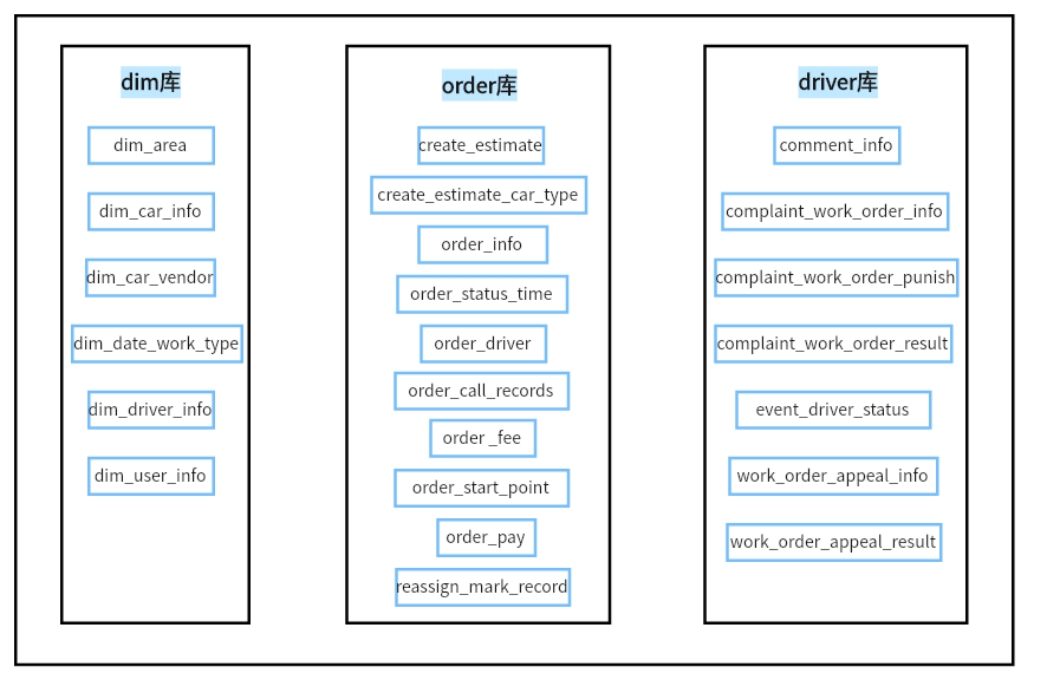
有状态算子的一般处理流程:
- 算子任务接收到上游发来的数据;
- 获取当前状态;
- 根据业务逻辑进行计算,更新状态;
- 得到计算结果,输出发送到下游任务。
状态分类
按照由 Flink 管理还是用户自行管理,状态可以分为原始状态 ( Raw State ) 和托管状态 (Managed State)。
原始状态:即用户自定义的 State。Flink 在做快照的时候,把整个 State 当做一个整体,需要开发者自己管理,使用 byte 数组来读写状态内容。
托管状态:是由 Flink 框架管理的 State,如 ValueState、ListState 等,其序列化和反序列化由 Flink 框架提供支持,无需用户感知、干预。通常在 DataStream 上的状态,推荐使用托管状态,一般情况下,在实现自定义算子时,才会使用到原始状态。
- 算子状态(Operator State):Operator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。
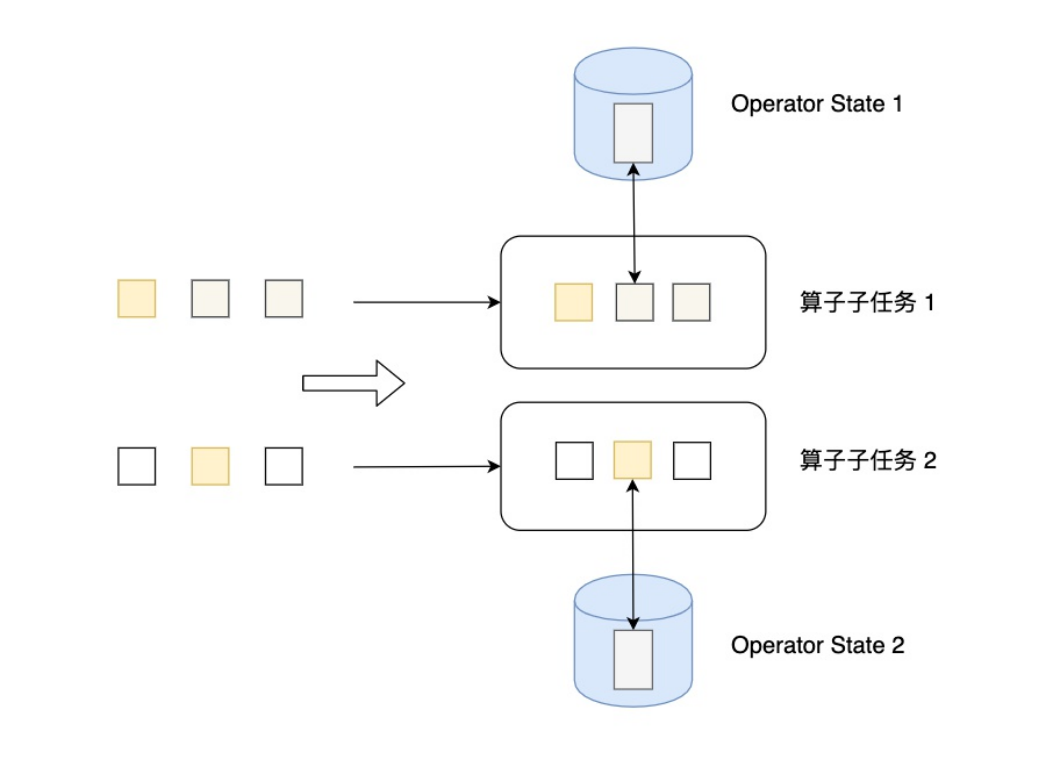
- 按键分区状态(Keyed State):Keyed State是KeyedStream上的状态。假如输入流按照id为Key进行了keyBy分组,形成一个KeyedStream,数据流中所有id为1的数据共享一个状态,可以访问和更新这个状态,以此类推,每个Key对应一个自己的状态。
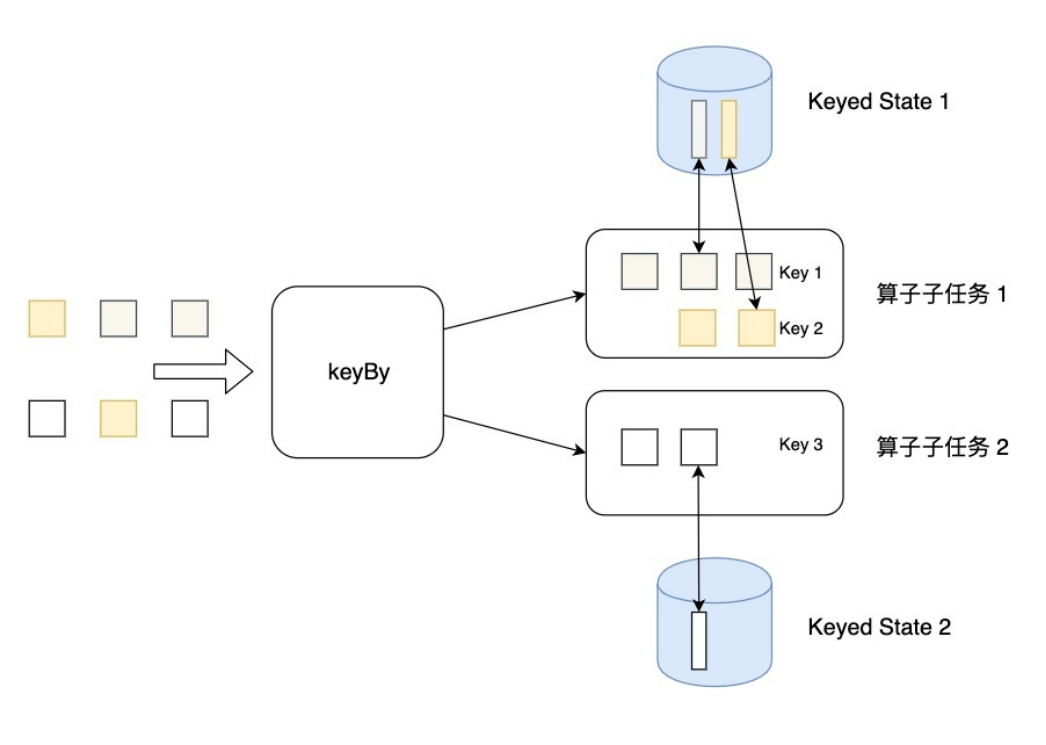
无论是Keyed State还是Operator State,Flink的状态都是基于本地的,即每个算子子任务维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。
分区状态
State主要有三种实现,分别为ValueState、MapState和AppendingState,AppendingState又可以细分为ListState、ReducingState和AggregatingState。
分区状态划分
- 值状态(ValueState):状态中只保存一个“值”(value)。
1 | // ValueState<T>本身是一个接口,源码中定义如下: |
- 列表状态(ListState):将需要保存的数据,以列表(List)的形式组织起来。在 ListState
接口中同样有一个类型参数T,表示列表中数据的类型。
1 | // ListState 提供了一系列的方法来操作状态,使用方式与一般的List 非常相似。 |
- 映射状态(MapState):把一些键值对(key-value)作为状态整体保存起来,可以认为就是一组 key-value 映射的列表。对应的 MapState<UK, UV>接口中,就会有 UK、UV 两个泛型,分别表示保存的 key 和 value 的类型。
1 | // MapState 提供了操作映射状态的方法,与 Map 的使用非常类似。 |
- 归约状态(ReducingState):类似于值状态(Value),不过需要对添加进来的所有数据进行归约,将归约聚合之后的值作为状态保存下来。ReducintState
这个接口调用的方法类似于 ListState,只不过它保存的只是一个聚合值,所以调用.add()方法时,不是在状态列表里添加元素,而是直接把新数据和之前的状态进行归约,并用得到的结果更新状态。
1 | // 归约逻辑的定义,是在归约状态描述器(ReducingStateDescriptor)中,通过传入一个归约函数(ReduceFunction)来实现的。这里的归约函数,就是之前介绍 reduce 聚合算子时讲到的 ReduceFunction,所以状态类型跟输入的数据类型是一样的。 |
- 聚合状态(AggregatingState):与归约状态非常类似,聚合状态也是一个值,用来保存添加进来的所有数据的聚合结果。与 ReducingState 不同的是,它的聚合逻辑是由在描述器中传入一个更加一般化的聚合函数(AggregateFunction)来定义的;里面通过一个累加器(Accumulator)来表示状态,所以聚合的状态类型可以跟添加进来的数据类型完全不同,使用更加灵活。
1 | // AggregatingState 接口调用方法也与ReducingState 相同,调用.add()方法添加元素时,会直接使用指定的AggregateFunction 进行聚合并更新状态。 |
状态生存时间
在某些场景下 Flink 用户状态一直在无限增长,一些用例需要能够自动清理旧的状态。例如,作业中定义了超长的时间窗口,或者在动态表上应用了无限范围的 GROUP BY 语句。此外,目前开发人员需要自己完成 TTL 的临时实现,例如使用可能不节省存储空间的计时器服务。
1 | // 要使用 State TTL 功能,首先要定义一个 StateTtlConfig 对象。StateTtlConfig 对象可以通过构造器模式来创建,典型地用法是传入一个 Time 对象作为 TTL 时间,然后可以设置时间处理语义(TtlTimeCharacteristic)、更新类型(UpdateType)以及状态可见性(StateVisibility)。当创建完 StateTtlConfig 对象,可以在状态描述符中启用 State TTL 功能。 |
- 时间处理语义
1 | // TtlTimeCharacteristic 表示 State TTL 功能可以使用的时间处理语义: |
- 更新类型
1 | // UpdateType 表示状态时间戳(上次访问时间戳)的更新时机: |
- 状态可见性
1 | // StateVisibility 表示状态可见性,在读取状态时是否返回过期值: |
过期清理策略
- 全量快照清理策略
1
2
3
4
5
6
7
8// 全量快照清理策略,这种策略可以在生成全量快照(Snapshot/Checkpoint)时清理过期状态,这样可以大大减小快照存储,但需要注意的是本地状态中过期数据并不会被清理。唯有当作业重启并从上一个快照恢复后,本地状态才会实际减小。如果要在 DataStream 中使用该过期请策略,请参考如下所示代码:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build();这种过期清理策略对开启了增量检查点的 RocksDB 状态后端无效。- 增量清理策略
1
2
3
4
5
6
7// 对 Heap StateBackend 的增量清理策略。这种策略下存储后端会为所有状态条目维护一个惰性全局迭代器。每次触发增量清理时,迭代器都会向前迭代删除已遍历的过期数据。如果要在 DataStream 中使用该过期请策略,请参考如下所示代码:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(5, false)
.build();
// 该策略有两个参数:第一个参数表示每次触发清理时需要检查的状态条目数,总是在状态访问时触发。第二个参数定义了在每次处理记录时是否额外触发清理。堆状态后端的默认后台清理每次触发检查 5 个条目,处理记录时不会额外进行过期数据清理。- 如果该状态没有被访问或者没有记录需要处理,那么过期状态会一直存在。
- 增量清理所花费的时间会增加记录处理延迟。
- 目前仅堆状态后端实现了增量清理。为 RocksDB 状态后端设置增量清理不会有任何效果。
- 如果堆状态后端与同步快照一起使用,全局迭代器在迭代时保留所有 Key 的副本,因为它的特定实现不支持并发修改。启用此功能将增加内存消耗。异步快照没有这个问题。
- 对于现有作业,可以随时在 StateTtlConfig 中启用或者停用此清理策略。
- RocksDB 压缩清理策略
1
2
3
4
5
6
7
8// 如果使用 RocksDB StateBackend,则会调用 Flink 指定的压缩过滤器进行后台清理。RocksDB 周期性运行异步压缩来合并状态更新并减少存储。Flink 压缩过滤器使用 TTL 检查状态条目的过期时间戳并删除过期状态值。如果要在 DataStream 中使用该过期请策略,请参考如下所示代码:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build();
// RocksDB 压缩过滤器在每次处理一定状态条目后,查询当前的时间戳并检查是否过期。频繁地更新时间戳可以提高清理速度,但同样也会降低压缩性能。RocksDB 状态后端的默认每处理 1000 个条目就查询当前时间戳。
算子状态
算子状态(Operator State)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务,与Key无关,不同Key的数据只要分发到同一个并行子任务,就会访问到同一个算子状态。
使用场景
算子状态一般用在 Source 或 Sink 等与外部系统连接的算子上,或者完全没有 key 定义的场景。比如 Flink 的 Kafka 连接器中,就用到了算子状态。在给 Source 算子设置并行度后,Kafka 消费者的每一个并行实例,都会为对应的主题(topic)分区维护一个偏移量, 作为算子状态保存起来。这在保证 Flink 应用“精确一次”(exactly-once)状态一致性时非常有用。
状态类型
算子状态也支持不同的结构类型,主要有三种:ListState、UnionListState 和 BroadcastState。
- 列表状态(ListState):与 Keyed State 中的 ListState 一样,将状态表示为一组数据的列表。与 Keyed State 中的列表状态的区别是:在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”(list),也就是当前并行子任务上所有状态项的集合。列表中的状态项就是可以重新分配的最细粒度,彼此之间完全独立。
- 当算子并行度进行缩放调整时,算子的列表状态中的所有元素项会被统一收集起来,相当于把多个分区的列表合并成了一个“大列表”,然后再均匀地分配给所有并行任务。这种“均匀分配”的具体方法就是“轮询”(round-robin),与之前介绍的 rebanlance 数据传输方式类似,是通过逐一“发牌”的方式将状态项平均分配的。这种方式也叫作“平均分割重组”(even-splitredistribution)。
- 算子状态中不会存在“键组”(key group)这样的结构,所以为了方便重组分配,就把它直接定义成了“列表”(list)。这也就解释了,为什么算子状态中没有最简单的值状态(ValueState)。
- 总结:ListState的快照存储数据,在系统重启后,list数据的重分配模式为: round-robin; 轮询平均分配
- 联合列表状态(UnionListState):与 ListState 类似,联合列表状态也会将状态表示为一个列表。它与常规列表状态的区别在于:算子并行度进行缩放调整时对于状态的分配方式不同。
- UnionListState 的重点就在于“联合”(union)。在并行度调整时,常规列表状态是轮询分配状态项,而联合列表状态的算子则会直接广播状态的完整列表。这样,并行度缩放之后的并行子任务就获取到了联合后完整的“大列表”,可以自行选择要使用的状态项和要丢弃的状态项。这种分配也叫作“联合重组”(union redistribution)。如果列表中状态项数量太多,为资源和效率考虑一般不建议使用联合重组的方式。
- 总结:unionListState的快照存储数据,在系统重启后,list数据的重分配模式为: 广播模式; 在每个subtask上都拥有一份完整的数据
- 广播状态(BroadcastState):有时希望算子并行子任务都保持同一份“全局”状态,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)。
- 因为广播状态在每个并行子任务上的实例都一样,所以在并行度调整的时候就比较简单, 只要复制一份到新的并行任务就可以实现扩展;而对于并行度缩小的情况,可以将多余的并行子任务连同状态直接砍掉——因为状态都是复制出来的,并不会丢失。
- 在底层,广播状态是以类似映射结构(map)的键值对(key-value)来保存的,必须基于一个“广播流”(BroadcastStream)来创建。
Flink SQL常用语法
主要分为DDL和DML语句
DDL
DDL: Create 子句
目前 Flink SQL 支持下列 CREATE 语句
● CREATE TABLE
● CREATE DATABASE
● CREATE VIEW
● CREATE FUNCTION
建表语句
DML
DML: With 子句
DML: WHERE 子句
DML: DISTINCT 子句
DML: 窗口聚合
DML: Group 聚合
DML: Joins 语法
Flink 也支持了非常多的数据 Join 方式,主要包括以下三种:
- 动态表(流)与动态表(流)的 Join
- 动态表(流)与外部维表(比如 Redis)的 Join
- 动态表字段的列转行(一种特殊的 Join)
细分 Flink SQL 支持的 Join:
- Regular Join:流与流的 Join,包括 Inner Equal Join、Outer Equal Join
- 实时 Regular Join 可以不是 等值 join。等值 join 和 非等值 join 区别在于,等值 join 数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游;非等值 join 数据 shuffle 策略是 Global,所有数据发往一个并发,按照非等值条件进行关联
- Join 的流程是左流新来一条数据之后,会和右流中符合条件的所有数据做 Join,然后输出。
- 流的上游是无限的数据,所以要做到关联的话,Flink 会将两条流的所有数据都存储在 State 中,所以 Flink 任务的 State 会无限增大,因此你需要为 State 配置合适的 TTL,以防止 State 过大
- Interval Join:流与流的 Join,两条流一段时间区间内的 Join
实时 Interval Join 可以不是 等值 join。等值 join 和 非等值 join 区别在于,等值 join 数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游;非等值 join 数据 shuffle 策略是 Global,所有数据发往一个并发,然后将满足条件的数据进行关联输出
当左Join时如果左流中有数据没有被Join到,当这些数据之后(时间语义上的之后)的数据被Join到后,这些数据就过期了输出NUll
- Temporal Join:流与流的 Join,包括事件时间,处理时间的 Temporal Join,类似于离线中的快照 Join
- Lookup Join:流与外部维表的 Join
- Array Expansion:表字段的列转行,类似于 Hive 的 explode 数据炸开的列转行
- Table Function:自定义函数的表字段的列转行,支持 Inner Join 和 Left Outer Join
DML: 集合操作
DML: TopN
Flink SQL 自定义函数UDF
函数归类
Flink 中的函数有两个维度的归类标准。
- 一个归类标准是:系统(内置)函数和 Catalog 函数。系统函数没有命名空间,只能通过其名称来进行引用。Catalog 函数属于 Catalog 和数据库,因此它们拥有 Catalog 和数据库的命名空间。用户可以通过全/部分限定名(catalog.db.func 或 db.func)或者函数来对 Catalog 函数进行引用。
- 另一个归类标准是:临时函数和持久化函数。临时函数由用户创建,它仅在会话的生命周期(也就是一个 Flink 任务的一次运行生命周期内)内有效。持久化函数不是由系统提供的,是存储在 Catalog 中,它在不同会话的生命周期内都有效。
这两个维度归类标准组合下,Flink SQL 总共提供了 4 种函数:
- 临时性系统内置函数
- 系统内置函数
- 临时性 Catalog 函数(例如:Create Temporary Function)
- Catalog 函数(例如:Create Function)
请注意,在用户使用函数时,系统函数始终优先于 Catalog 函数解析,临时函数始终优先于持久化函数解析。
自定义函数
当前 Flink 提供了一下几种 UDF 能力:
- 标量函数(Scalar functions 或 UDAF):输入一条输出一条,将标量值转换成一个新标量值,对标 Hive 中的 UDF;
- 表值函数(Table functions 或 UDTF):输入一条条输出多条,对标 Hive 中的 UDTF;
- 聚合函数(Aggregate functions 或 UDAF):输入多条输出一条,对标 Hive 中的 UDAF;
- 表值聚合函数(Table aggregate functions 或 UDTAF):仅仅支持 Table API,不支持 SQL API,其可以将多行转为多行;
- 异步表值函数(Async table functions):这是一种特殊的 UDF,支持异步查询外部数据系统,用在前文介绍到的 lookup join 中作为查询外部系统的函数。
标量函数
继承ScalarFunction类,实现eval()方法
自定义标量函数
1 | package com.itheima.flink.udf; |
表值函数
TableFuntion 可以有0个、一个、多个输入参数,他的返回值可以是任意行,每行可以有多列数据。
实现自定义TableFunction需要继承TableFunction类,实现eval方法。
- TableFunction是一个泛型类,需要指定返回值类型
- 不同于标量函数,eval方法没有返回值,使用collect方法来收集对象。
自定义表值函数
1 | import org.apache.flink.api.java.tuple.Tuple2; |
聚合函数
Flink 的AggregateFunction是一个基于中间计算结果状态进行增量计算的函数。由于是迭代计算方式,所以,在窗口处理过程中,不用缓存整个窗口的数据,所以效率执行比较高。
该函数会将给定的聚合函数应用于每个窗口和键。 对每个元素调用聚合函数,以递增方式聚合值,并将每个键和窗口的状态保持在一个累加器中。
AggregateFunction需要重写的方法有:
- createAccumulator:创建一个新的累加器,开始一个新的聚合。累加器是正在运行的聚合的状态。
- add:将给定的输入添加到给定的累加器,并返回新的累加器值。
- getResult:从累加器获取聚合结果。
- merge:合并两个累加器,返回合并后的累加器的状态。
自定义聚合函数
1 | package com.itheima.flink.udf; |
表值聚合函数
表聚合,多对多,多行输入多行输出,用户定义的表聚合函数(User-Defined Table Aggregate Functions,UDTAF),可以把一个表中数据,聚合为具有多行和多列的结果表
用户定义表聚合函数,是通过继承 TableAggregateFunction 抽象类来实现的,TableAggregateFunction 要求必须实现的方法:
- createAccumulator()
- accumulate()
- emitValue()
- merge()
表值聚合函数
1 | package com.itheima.flink.udf; |
 微信
微信 支付宝
支付宝