Flink 中的水印操作 问题引入 流处理中的乱序问题 当 flink 以 EventTime 模式处理流数据时,它会根据数据里的时间戳来处理基于时间的算子。
但是由于网络、分布式等原因,会导致数据乱序的情况。
watermark解决乱序问题 不以事件时间作为触发计算的条件,而是根据Watermark判断是否触发。
当Watermark的时间戳等于Event中携带的EventTime时候,上面场景(Watermark=EventTime)的计算结果如下:
Watermark=EventTime
Watermark = EventTime -5s 如果想正确处理迟来的数据可以定义Watermark生成策略为 Watermark = EventTime -5s, 如下:
基于SQL的水印 实现场景:
使用Socket模拟接收数据
设置WaterMark,设置的逻辑:在第一条数据进来时,设置WaterMark为0,指定第一条数据的时间戳后,获取该时间戳与当前 WaterMark的最大值,并将最大值设置为下一条数据的WaterMark,以此类推
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 CREATE TABLE MyTable (item STRING, ts TIMESTAMP (3 ), WATERMARK FOR ts AS ts - INTERVAL '0' SECOND ) WITH ( 'connector' = 'socket' ,'hostname' = 'node1' ,'port' = '9999' ,'format' = 'csv' ); SELECT TUMBLE_START(ts, INTERVAL '5' SECOND ) AS window_start, TUMBLE_END(ts, INTERVAL '5' SECOND ) AS window_end, TUMBLE_ROWTIME(ts, INTERVAL '5' SECOND ) as window_rowtime, item,count (item) as total_item FROM MyTableGROUP BY TUMBLE(ts, INTERVAL '5' SECOND ), item;
数据有序的场景 测试数据:
1 2 3 4 5 6 hello,2022-03-25 16:39:45 hello,2022-03-25 16:39:46 hello,2022-03-25 16:39:47 hello,2022-03-25 16:39:48 hello,2022-03-25 16:39:49 hello,2022-03-25 16:39:50
数据无序的场景 测试数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 hello,2022-03-25 16:39:45 hello,2022-03-25 16:39:46 hello,2022-03-25 16:39:47 hello,2022-03-25 16:39:48 hello,2022-03-25 16:39:49 hello,2022-03-25 16:39:50 hello,2022-03-25 16:39:47 hello,2022-03-25 16:39:46 hello,2022-03-25 16:39:51 hello,2022-03-25 16:39:52 hello,2022-03-25 16:39:53 hello,2022-03-25 16:39:54 hello,2022-03-25 16:39:55
设置迟到时间:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 drop table MyTable;CREATE TABLE MyTable (item STRING, ts TIMESTAMP (3 ), WATERMARK FOR ts AS ts - INTERVAL '5' SECOND ) WITH ( 'connector' = 'socket' ,'hostname' = 'node1' ,'port' = '9999' ,'format' = 'csv' ); SELECT TUMBLE_START(ts, INTERVAL '5' SECOND ) AS window_start, TUMBLE_END(ts, INTERVAL '5' SECOND ) AS window_end, TUMBLE_ROWTIME(ts, INTERVAL '5' SECOND ) as window_rowtime, item,count (item) as total_item FROM MyTableGROUP BY TUMBLE(ts, INTERVAL '5' SECOND ), item;
基于DataStream的水印 水印策略设置 WatermarkStrategy 可以在 Flink 应用程序中的两处使用:
第一种是直接在数据源上使用
第二种是直接在非数据源的操作之后使用
第一种方式相比会更好,因为数据源可以利用 watermark 生成逻辑中有关分片/分区(shards/partitions/splits)的信息。使用这种方式,数据源通常可以更精准地跟踪 watermark,整体 watermark 生成将更精确。直接在源上指定 WatermarkStrategy意味着你必须使用特定数据源接口,例如与kafka链接,使用kafka Connerctor。
仅当无法直接在数据源上设置策略时,才应该使用第二种方式(在任意转换操作之后设置 WatermarkStrategy)
1 2 3 4 5 6 7 8 9 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();KafkaSource<String> source = KafkaSource.<String>builder() .setBootstrapServers(brokers) .setTopics("input-topic" ) .setGroupId("my-group" ) .setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema ()).build(); env.fromSource(source, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(20 )), "Kafka Source" );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<MyEvent> stream = env.readFile( myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100 , FilePathFilter.createDefaultFilter(), typeInfo); DataStream<MyEvent> withTimestampsAndWatermarks = stream .filter( event -> event.severity() == WARNING ) .assignTimestampsAndWatermarks(<watermark strategy>); withTimestampsAndWatermarks .keyBy( (event) -> event.getGroup() ) .window(TumblingEventTimeWindows.of(Time.seconds(10 ))) .reduce( (a, b) -> a.add(b) ) .addSink(...);
使用去获取流并生成带有时间戳的元素和 watermark 的新流时,如果原始流已经具有时间戳或 watermark,则新指定的时间戳分配器将覆盖原有的时间戳和 watermark。WatermarkStrategy。
水印策略案例 单调递增生成水印 周期性 watermark 生成方式的一个最简单特例就是你给定的数据源中数据的时间戳升序出现。在这种情况下,当前时间戳就可以充当 watermark,因为后续到达数据的时间戳不会比当前的小。
1 WatermarkStrategy.forMonotonousTimestamps();
这个也就是相当于上述的延迟策略去掉了延迟时间,以event中的时间戳充当了水印。
在程序中可以这样使用:
1 2 3 DataStream dataStream = ...... ;dataStream.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps());
案例演示:
对有序的数据流添加水印,底层调用的是固定延迟生成水印,只是传递的水印等待时间是0,意味着不考虑乱序问题
使用单点递增水印,解决的是数据有序的场景
需求:从socket接受数据,进行转换,然后应用窗口,每隔5s生成一个窗口(非系统时间驱动窗口计算,数据中携带的事件时间),使用水印时间触发窗口计算
eventTime一定是一个毫秒值的时间戳,否则无法参与计算
固定延迟生成水印 通过静态方法forBoundedOutOfOrderness提供,入参接收一个Duration类型的时间间隔,也就是我们可以接受的最大的延迟时间。使用这种延迟策略的时候需要我们对数据的延迟时间有一个大概的预估判断。
1 WatermarkStrategy.forBoundedOutOfOrderness(Duration maxOutOfOrderness)
我们实现一个延迟3秒的固定延迟水印:
1 2 DataStream dataStream = ...... ;dataStream.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3 )));
他的底层是使用的WatermarkGenerator接口的一个实现类BoundedOutOfOrdernessWatermarks。重写实现了两个方法:
onEvent :每个元素都会调用这个方法,如果我们想依赖每个元素生成一个水印,然后发射到下游。
onPeriodicEmit : 如果数据量比较大的时候,我们每条数据都生成一个水印的话,会影响性能,所以这里还有一个周期性生成水印的方法。这个水印的生成周期可以这样设置:
1 env.getConfig().setAutoWatermarkInterval(5000L );
固定延迟水印策略 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 package com.itheima.flink.watermark;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;import org.apache.flink.api.common.eventtime.WatermarkStrategy;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;import org.apache.flink.streaming.api.windowing.time.Time;import org.apache.flink.streaming.api.windowing.windows.TimeWindow;import org.apache.flink.util.Collector;import java.time.Duration;public class WaterMarkStrategyDemo { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> streamSource = env.socketTextStream("node1" , 9999 ); streamSource.assignTimestampsAndWatermarks( WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(5 )) .withTimestampAssigner(new SerializableTimestampAssigner <String>() { @Override public long extractTimestamp (String element, long recordTimestamp) { return Long.parseLong(element.split("," )[1 ]) * 1000 ; } }) ).keyBy(str -> str.split("," )[0 ]) .window(TumblingEventTimeWindows.of(Time.seconds(5 ))) .process(new ProcessWindowFunction <String, String, String, TimeWindow>() { @Override public void process (String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) throws Exception { elements.forEach(System.out::println); } }); env.execute(); } }
多并行度设置水印 两个基本原则:
多并行度水印策略 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 package com.itheima.flink.watermark;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;import org.apache.flink.api.common.eventtime.WatermarkStrategy;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;import org.apache.flink.streaming.api.windowing.time.Time;import org.apache.flink.streaming.api.windowing.windows.TimeWindow;import org.apache.flink.util.Collector;import java.time.Duration;public class ParallelWaterMarkStrategy { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(2 ); DataStreamSource<String> streamSource = env.socketTextStream("node1" , 9999 ); streamSource .map(new MapFunction <String, Tuple2<String, String>>() { @Override public Tuple2<String, String> map (String value) throws Exception { return Tuple2.of(value.split("," )[0 ], value.split("," )[1 ]); } }) .assignTimestampsAndWatermarks( WatermarkStrategy.<Tuple2<String, String>>forBoundedOutOfOrderness(Duration.ofSeconds(5 )) .withTimestampAssigner(new SerializableTimestampAssigner <Tuple2<String, String>>() { @Override public long extractTimestamp (Tuple2<String, String> element, long recordTimestamp) { return Long.parseLong(element.f1) * 1000 ; } }) ).keyBy(t -> t.f0) .window(TumblingEventTimeWindows.of(Time.seconds(5 ))) .process(new ProcessWindowFunction <Tuple2<String, String>, Tuple2<String, String>, String, TimeWindow>() { @Override public void process (String s, ProcessWindowFunction<Tuple2<String, String>, Tuple2<String, String>, String, TimeWindow>.Context context, Iterable<Tuple2<String, String>> elements, Collector<Tuple2<String, String>> out) throws Exception { System.out.println("当前窗口为:" + context.window().toString()); elements.forEach(out::collect); } }).print(); env.execute(); } }
处理空闲数据案例 在某些情况下,由于数据产生的比较少,导致一段时间内没有数据产生,进而就没有水印的生成,导致下游依赖水印的一些操作就会出现问题,比如某一个算子的上游有多个算子,这种情况下,水印是取其上游两个算子的较小值,如果上游某一个算子因为缺少数据迟迟没有生成水印,就会出现eventtime倾斜问题,导致下游没法触发计算。
所以filnk通过WatermarkStrategy.withIdleness()方法允许用户在配置的时间内(即超时时间内)没有记录到达时将一个流标记为空闲。这样就意味着下游的数据不需要等待水印的到来。
当下次有水印生成并发射到下游的时候,这个数据流重新变成活跃状态。
通过下面的代码来实现对于空闲数据流的处理
1 2 3 WatermarkStrategy .<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20 )) .withIdleness(Duration.ofMinutes(1 ));
设置最大空闲时间水印策略 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 package com.itheima.flink.watermark;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;import org.apache.flink.api.common.eventtime.WatermarkStrategy;import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;import org.apache.flink.streaming.api.windowing.time.Time;import org.apache.flink.streaming.api.windowing.windows.TimeWindow;import org.apache.flink.util.Collector;import java.time.Duration;public class WithIdlenessWaterMarkStrategy { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(10 ); DataStreamSource<String> streamSource = env.socketTextStream("node1" , 9999 ); SingleOutputStreamOperator<Tuple2<String, String>> watermarks = streamSource .map(line -> Tuple2.of(line.split("," )[0 ], line.split("," )[1 ])) .returns(Types.TUPLE(Types.STRING, Types.STRING)) .assignTimestampsAndWatermarks( WatermarkStrategy.<Tuple2<String, String>>forBoundedOutOfOrderness(Duration.ofSeconds(5 )) .withTimestampAssigner(new SerializableTimestampAssigner <Tuple2<String, String>>() { @Override public long extractTimestamp (Tuple2<String, String> element, long recordTimestamp) { return Long.parseLong(element.f1) * 1000 ; } }) .withIdleness(Duration.ofSeconds(30 )) ); watermarks.keyBy(t -> t.f0) .window(TumblingEventTimeWindows.of(Time.seconds(5 ))) .process(new ProcessWindowFunction <Tuple2<String, String>, Tuple2<String, String>, String, TimeWindow>() { @Override public void process (String s, ProcessWindowFunction<Tuple2<String, String>, Tuple2<String, String>, String, TimeWindow>.Context context, Iterable<Tuple2<String, String>> elements, Collector<Tuple2<String, String>> out) throws Exception { System.out.println("当前窗口信息:" + context.window().toString()); elements.forEach(out::collect); } }).print(); env.execute(); } }
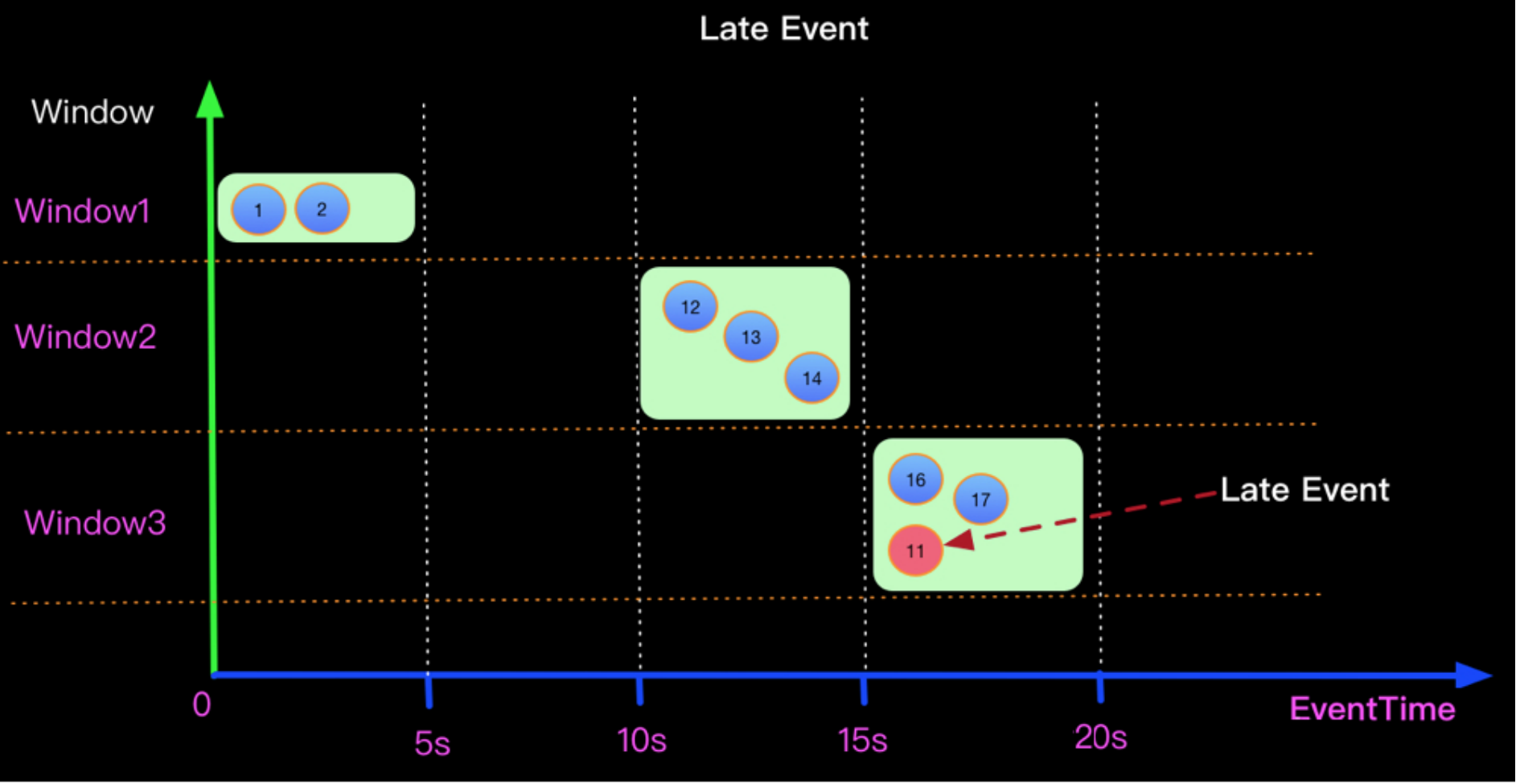
长期延迟数据处理 水印机制(水位线、watermark)机制可以帮助我们在短期延迟下,允许乱序数据的到来。这个机制很好的处理了那些因为网络等情况短期延迟的数据,让窗口等它们一会儿。
水印机制无法长期的等待下去,因为水印机制简单说就是让窗口一直等在那里,等达到水印时间才会触发计算和关闭窗口。这个等待不能一直等,因为会一直缓着数据不计算。一般水印也就是几秒钟最多几分钟而已。
这个场景的解决方式就是:延迟数据处理机制(allowedLateness方法)
水印: 乱序数据处理(时间很短的延迟)
延迟处理:长期延迟数据的处理机制
主要的办法是给定一个允许延迟的时间,在该时间范围内仍可以接受处理延迟数据:
设置允许延迟的时间是通过allowedLateness(lateness: Time)设置
保存延迟数据则是通过sideOutputLateData(outputTag: OutputTag[T])保存
获取延迟数据是通过DataStream.getSideOutput(tag: OutputTag[X])获取
自定义水印策略 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 package com.itheima.flink.watermark;import org.apache.flink.api.common.eventtime.*;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;import org.apache.flink.streaming.api.windowing.time.Time;import org.apache.flink.streaming.api.windowing.windows.TimeWindow;import org.apache.flink.util.Collector;import java.time.Duration;import java.util.Random;import static org.apache.flink.util.Preconditions.checkArgument;import static org.apache.flink.util.Preconditions.checkNotNull;public class CustomWaterMarkStrategy { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> streamSource = env.socketTextStream("node1" , 9999 ); streamSource.assignTimestampsAndWatermarks(new WatermarkStrategy <String>() { @Override public WatermarkGenerator<String> createWatermarkGenerator (WatermarkGeneratorSupplier.Context context) { return new CustomWaterMarkGenerator (); } }.withTimestampAssigner(new SerializableTimestampAssigner <String>() { @Override public long extractTimestamp (String element, long recordTimestamp) { return Long.parseLong(element.split("," )[1 ]) * 1000 ; } })).keyBy(str -> str.split("," )[0 ]) .window(TumblingEventTimeWindows.of(Time.seconds(5 ))) .process(new ProcessWindowFunction <String, String, String, TimeWindow>() { @Override public void process (String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) throws Exception { elements.forEach(System.out::println); } }); env.execute(); } private static class CustomWaterMarkGenerator implements WatermarkGenerator <String> { private long maxTimestamp = 0L ; @Override public void onEvent (String event, long eventTimestamp, WatermarkOutput output) { this .maxTimestamp = Math.max(eventTimestamp, maxTimestamp); } @Override public void onPeriodicEmit (WatermarkOutput output) { output.emitWatermark(new Watermark (maxTimestamp + new Random ().nextInt(10 ) * 1000 - 1 )); } } }
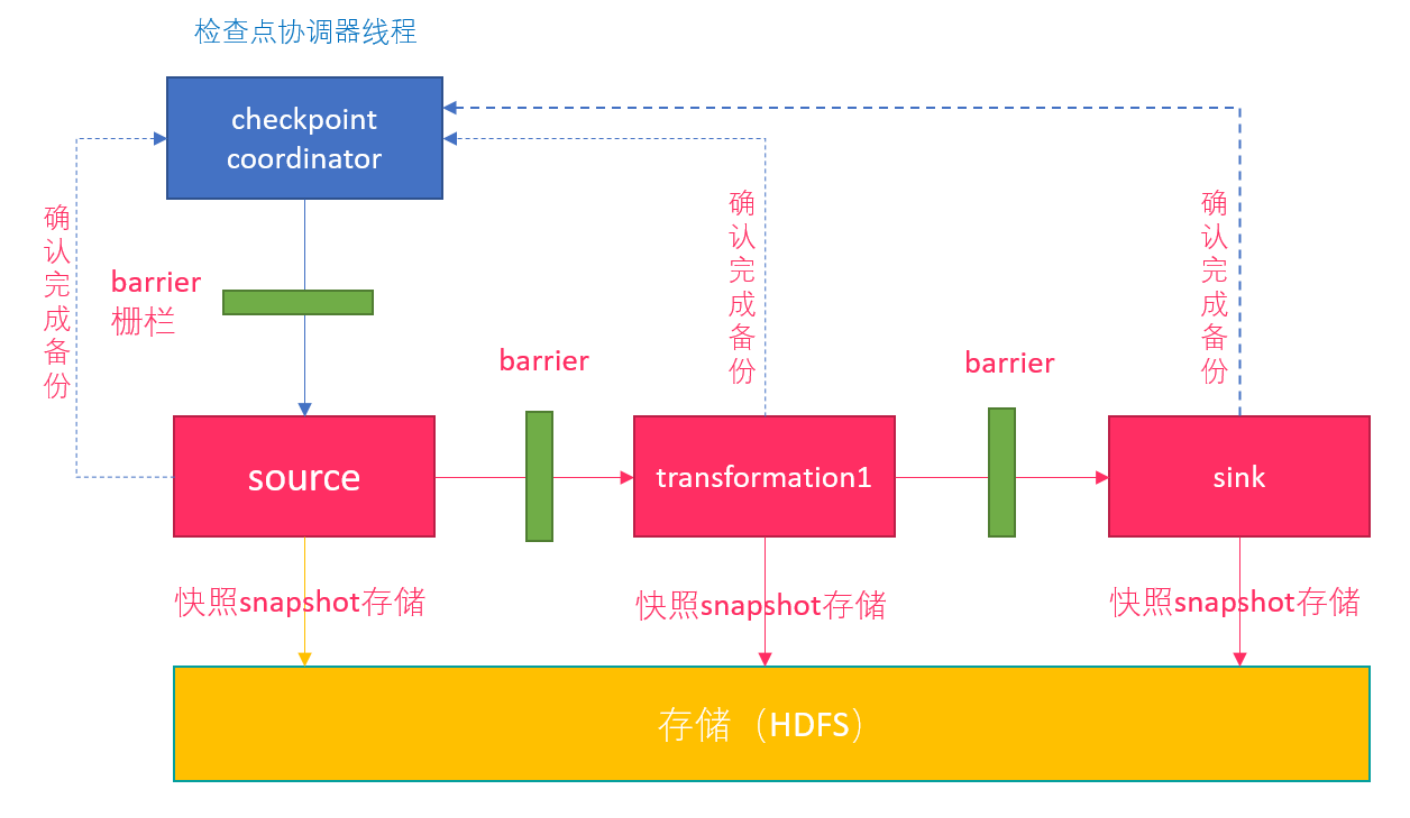
Flink 中的快照机制 Checkpoint 检查点 为了使 Flink 的状态具有良好的容错性,Flink 提供了检查点机制 (CheckPoints) 。通过检查点机制,Flink 定期在数据流上生成 checkpoint barrier ,当某个算子收到 barrier 时,即会基于当前状态生成一份快照,然后再将该 barrier 传递到下游算子,下游算子接收到该 barrier 后,也基于当前状态生成一份快照,依次传递直至到最后的 Sink 算子上。当出现异常后,Flink 就可以根据最近的一次的快照数据将所有算子恢复到先前的状态。
Checkpoint实现过程 Flink 的数据可以粗略分为以下三类:
第一种是元信息,相当于一个 Flink 作业运行起来所需要的最小信息集合,包括比如 Checkpoint 地址、Job Manager、Dispatcher、Resource Manager 等等,这些信息的容错是由 Kubernetes/Zookeeper 等系统的高可用性来保障的,不在我们讨论的容错范围内。
Flink 作业运行起来以后,会从数据源读取数据写到 Sink 里,中间流过的数据称为处理的中间数据 Inflight Data (第二类)。
对于有状态的算子比如聚合算子,处理完输入数据会产生算子状态数据 (第三类)。
Flink 会周期性地对所有算子的状态数据做快照,上传到持久稳定的海量存储中 (Durable Bulk Store),这个过程就是做 Checkpoint。Flink 作业发生错误时,会回滚到过去的一个快照检查点 Checkpoint 恢复。
Checkpointing 的流程分为以下几步:
第一步:
第二步:
第三步:
第四步:
Checkpoint参数配置 在flink-conf.yaml中配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 execution.checkpointing.interval: 5000 execution.checkpointing.mode: EXACTLY_ONCE state.backend: filesystem state.checkpoints.dir: hdfs://node1:8020/checkpoints state.savepoints.dir: hdfs://node1:8020/checkpoints execution.checkpointing.timeout: 2500 execution.checkpointing.min-pause: 500 execution.checkpointing.max-concurrent-checkpoints: 1 state.checkpoints.num-retained: 3 execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
State 状态后端 Flink 提供了不同的状态后端,用于指定状态的存储方式和位置。
默认情况下,flink的状态会保存在taskmanager的内存中,⽽checkpoint会保存在jobManager的内存中。
Flink 提供了三种可用的状态后端用于在不同情况下进行状态的保存:
MemoryStateBackend
FsStateBackend
RocksDBStateBackend
MemoryStateBackend MemoryStateBackend内部将状态(state)数据作为对象保存在java堆内存中(taskManager),通过checkpoint机制,MemoryStateBackend将状态(state)进⾏快照并保存Jobmanager(master)的堆内存中。
使用 MemoryStateBackend 时的注意点:
默认情况下,每一个状态的大小限制为 5 MB。可以通过 MemoryStateBackend 的构造函数增加这个大小。
状态大小受到 akka 帧大小的限制,所以无论怎么调整状态大小配置,都不能大于 akka 的帧大小。
状态的总大小不能超过 JobManager 的内存。
何时使用 MemoryStateBackend:
本地开发或调试时建议使用 MemoryStateBackend,因为这种场景的状态大小的是有限的。
MemoryStateBackend 最适合小状态的应用场景。例如 Kafka Consumer,或者一次仅一记录的函数 (Map, FlatMap,或 Filter)。
全局配置 flink-conf.yaml
1 2 3 state.backend: hashmap state.checkpoint-storage: jobmanager
FsStateBackend 该持久化存储主要将快照数据保存到文件系统中,目前支持的文件系统主要是 HDFS和本地文件。
FsStateBackend适用的场景:
具有大状态,长窗口,大键 / 值状态的作业。
所有高可用性设置。
分布式文件持久化,每次读写都会产生网络IO,整体性能不佳
全局配置 flink-conf.yaml:
1 2 3 4 state.backend: hashmap state.checkpoints.dir: file:///checkpoint-dir/ state.checkpoint-storage: filesystem
RocksDBStateBackend RocksDB 是一种嵌入式的本地数据库
RocksDBStateBackend 将处理中的数据使用 RocksDB 存储在本地磁盘上。在 checkpoint 时,整个 RocksDB 数据库会被存储到配置的文件系统中,或者在超大状态作业时可以将****增量****的数据存储到配置的文件系统中。同时 Flink 会将极少的元数据存储在 JobManager 的内存中,或者在 Zookeeper 中(对于高可用的情况)。
何时使用 RocksDBStateBackend:
RocksDBStateBackend 最适合用于处理大状态,长窗口,或大键值状态的有状态处理任务。
RocksDBStateBackend 非常适合用于高可用方案。
RocksDBStateBackend 是目前唯一支持增量 checkpoint 的后端。增量 checkpoint 非常适用于超大状态的场景。
全局配置 flink-conf.yaml:
1 2 3 4 5 6 state.backend: rocksdb state.checkpoints.dir: file:///checkpoint-dir/ state.checkpoint-storage: filesystem
任务重启策略 重启策略类型 Flink支持的重启策略类型如下:
none, off, disable:无重启策略,作业遇到问题直接失败,不会重启。
fixeddelay, fixed-delay:固定延迟重启策略,作业失败后,延迟一定时间重启。但是有最大重启次数限制,超过这个限制后作业失败,不再重启。
failurerate, failure-rate:失败率重启策略,作业失败后,延迟一定时间重启。但是有最大失败率限制。如果一定时间内作业失败次数超过配置值,则标记为真的失败,不再重启。
exponentialdelay, exponential-delay:作业失败后重启延迟时间随着失败次数指数递增。没有最大重启次数限制,无限尝试重启作业。
注意:如果启用了checkpoint并且没有显式配置重启策略,会默认使用fixeddelay策略,最大重试次数为Integer.MAX_VALUE。
全局配置 全局配置影响Flink提交的所有作业的。修改全局配置需要编辑flink-conf.yaml文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 no restart restart-strategy: none fixeddelay restart-strategy: fixed-delay restart-strategy.fixed-delay.attempts: 10 restart-strategy.fixed-delay.delay: 20 s failurerate restart-strategy: failure-rate restart-strategy.failure-rate.delay: 10 s restart-strategy.failure-rate.failure-rate-interval: 2 min restart-strategy.failure-rate.max-failures-per-interval: 10 exponentialdelay restart-strategy: exponential-delay restart-strategy.exponential-delay.initial-backoff: 1 s restart-strategy.exponential-delay.backoff-multiplier: 2 restart-strategy.exponential-delay.jitter-factor: 0.1 restart-strategy.exponential-delay.max-backoff: 1 min restart-strategy.exponential-delay.reset-backoff-threshold: 1 h
端到端一致性 端到端一致性 端到端的保障指的是在整个数据处理管道上结果都是正确的 。在每个组件都提供自身的保障情况下,整个处理管道上端到端的保障会受制于保障最弱的那个组件 。
内部 :Checkpoints机制,在发生故障的时候能够恢复各个环节的数据。Source :保证数据读取之后仍存在,可设置数据读取的偏移量,当发生故障的时候重置偏移量到故障之前的位置。Sink :从故障恢复时,数据不会重复写入外部系统,需要支持幂等写或事务写。
两阶段提交实现Sink一致性
幂等写:一个操作可以重复执行多次,但只导致一次结果的更改
事务写:需要外部数据支持事务写入,可以通过两阶段提交实现事务写
1、Sink算子在一批数据处理过程中,先通过预提交事务开始对外输出数据
2、等这批数据处理完成(即完成checkpoint)后,向checkpoint coordinator上报自己完成checkpoint信息
3、checkpoint coordinator收到所有算子任务完成ck的信息后,再向所有算子任务广播本次ck的完成信息
4、两阶段事务提交sink算子收到协调器的回调信息时,执行事务commit操作
2pc提交主要实现beginTransaction-开启事务、preCommit准备提交、commit正式提交、abort丢弃四个方法
设置checkpoint和重启策略(DataStreamAPI) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 package com.itheima.flink.checkpoint;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.common.restartstrategy.RestartStrategies;import org.apache.flink.api.common.time.Time;import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;public class CheckpointDemo { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1 ); env.enableCheckpointing(5000 ); env.getCheckpointConfig().setCheckpointTimeout(2000 ); env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500 ); env.getCheckpointConfig().setMaxConcurrentCheckpoints(1 ); env.setStateBackend(new HashMapStateBackend ()); env.getCheckpointConfig().setCheckpointStorage("hdfs://node1:8020/flink-checkpoints" ); env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); env.setRestartStrategy(RestartStrategies.fixedDelayRestart( 3 , Time.seconds(5 ))); DataStreamSource<String> streamSource = env.socketTextStream("node1" , 9999 ); streamSource.flatMap(new FlatMapFunction <String, String>() { @Override public void flatMap (String value, Collector<String> out) throws Exception { if (value.contains("laowang" )) { System.out.println(1 /0 ); } String[] strings = value.split(" " ); for (String str : strings) { out.collect(str); } } }).print(); System.setProperty("HADOOP_USER_NAME" , "root" ); env.execute(); } }









 微信
微信 支付宝
支付宝