
【Flink】Flink算子及分区概念
粥所周知, Flink程序由四部分构成, 运行环境 + Source + Transformation + Sink.
接下来一个个说.
运行环境
批处理
获取批处理执行环境(用于测试/生产)
1
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
流处理
获取流式处理执行环境(用于测试/生产)
1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
流批一体
获取流批一体处理执行环境(用于测试/生产)
1
2
3final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置为批处理模式
env.setRuntimeMode(ExecutionMode.BATCH);
本地环境
创建本地执行环境(用于测试)
1
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
带有WebUI的本地环境
创建带有webui的本地执行环境(用于测试)
1
2
3Configuration conf = new Configuration();
conf.setInteger("rest.port",8081);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
执行模式
从Flink1.12.0版本起,Flink实现了API上的流批统一。DataStreamAPI新增了一个重要特性可以支持不同的执行模式,通过简单的设置就可以让一段Flink程序在流处理和批处理之间切换。这样一来,DataSet API也就没有存在的必要了。
执行模式的分类:
- 流执行(STREAMING)模式。
STREAMING模式是DataStream API最经典的模式,一般用于需要持续实时处理的无界数据流。在默认情况下,程序使用的就是STREAMING模式。- 批执行(BATCH)模式。
BATCH模式是专门用于批处理的执行模式,在这种模式下,Flink处理作业的方式类似于MapReduce框架。对于不会持续计算的有界数据,用这种模式处理会更方便。- 自动(AUTOMATIC)模式。
在AUTOMATIC模式下,将由程序根据输入数据源是否有界来自动选择执行模式。
执行模式的配置方法
(以BATCH为例,默认是STREAMING模式):
2
bin/flink run -Dexecution.runtime-mode=BATCH ...
2
3
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment ();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
建议:不要在代码中配置,而是使用命令行。这同设置并行度是类似的在提交作业时指定参数可以更加灵活,同一段应用在程序写好之后,既可以用于批处理,又可以用于流处理而在代码中进行硬编码的方式的可扩展性比较差,一般都不推荐。
输入算子Source
输入算子总结Summary
单并行算子如果显式设置>1的并行度,会抛异常
- 使用
env.fromElements(),这种方式也支持Tuple,自定义对象等复合形式- DataStreamSource <String> words = env.fromElements(“flink”, “hadoop”, “flink”);
- 使用
env.fromCollection(),这种方式支持多种Collection的具体类型,如List,Set,Queue- 非并行的Source(是一个单并行度的source算子),可以将一个Collection作为参数传入到该方法中,返回一个DataStreamSource。
- List <String> dataList = Arrays.asList(“a”, “b”, “a”, “c”);
- 非并行的Source(是一个单并行度的source算子),可以将一个Collection作为参数传入到该方法中,返回一个DataStreamSource。
- 使用
env.fromParallelCollection所返回的source算子,是一个多并行度的source算子
1 | DataStreamSource<LongValue> parallelCollection = env.fromParallelCollection(new LongValueSequenceIterator(1, 100), TypeInformation.of(LongValue.class)).setParallelism(2); |
使用
env.generateSequence()方法创建基于Sequence的DataStream- 并行的Source(并行度也可以通过调用该方法后,再调用setParallelism来设置)通过指定的起始值和结束值来生成数据序列流;
- DataStreamSource <Long> sequence = env.generateSequence(1, 100);
- 并行的Source(并行度也可以通过调用该方法后,再调用setParallelism来设置)通过指定的起始值和结束值来生成数据序列流;
使用
env.fromSequence()方法创建基于开始和结束的DataStream- final DataStreamSource
sequence2 = env.fromSequence(1L, 5L);
- final DataStreamSource
Example
1 | // 使用env.fromElements(),这种方式也支持Tuple,自定义对象等复合形式 |
基于集合的Source
1 | package io.github.sourceOperator; |
基于Socket的Source
非并行的Source,DataStream API 支持从 Socket 套接字读取数据。只需要指定要从其中读取数据的主机和端口号即可。读取 Socket 套接字的数据源函数定义如下:
- socketTextStream(hostName, port)
- socketTextStream(hostName, port, delimiter):可指定分隔符,默认行分隔符是”\n”
- socketTextStream(hostName, port, delimiter, maxRetry):还可以指定 API 应该尝试获取数据的最大次数,默认最大重新连接次数为0。
基于文件的Source
基于文件的Source,本质上就是使用指定的FileInputFormat组件读取数据,可以指定TextInputFormat、CsvInputFormat、BinaryInputFormat等格式;底层都是ContinuousFileMonitoringFunction,这个类继承了RichSourceFunction,都是非并行的Source;
- readFile(FileInputFormat inputFormat, String filePath) 方法可以指定读取文件的FileInputFormat 格式,参数FileProcessingMode,可取值:
- PROCESS_ONCE,只读取文件中的数据一次,读取完成后,程序退出
- PROCESS_CONTINUOUSLY,会一直监听指定的文件,文件的内容发生变化后,会将以前的内容和新的内容全部都读取出来,进而造成数据重复读取。
- readTextFile(String filePath) 可以从指定的目录或文件读取数据,默认使用的是TextInputFormat格式读取数据,还有一个重载的方法readTextFile(String filePath, String charsetName)可以传入读取文件指定的字符集,默认是UTF-8编码。该方法是一个有限的数据源,数据读完后,程序就会退出,不能一直运行。该方法底层调用的是readFile方法,FileProcessingMode为PROCESS_ONCE
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是前两个方法内部调用的方法。它基于给定的 fileInputFormat 读取路径 path 上的文件。根据提供的 watchType 的不同,source 可能定期(每 interval 毫秒)监控路径上的新数据(watchType 为 FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次当前路径中的数据然后退出(watchType 为 FileProcessingMode.PROCESS_ONCE)。使用 pathFilter,用户可以进一步排除正在处理的文件。
第三方 Source(Kafka举例)
在实际生产环境中,为了保证flink可以高效地读取数据源中的数据,通常是跟一些分布式消息中件结合使用,例如Apache Kafka。Kafka的特点是分布式、多副本、高可用、高吞吐、可以记录偏移量等。Flink和Kafka整合可以高效的读取数据,并且可以保证Exactly Once(精确一次性语义)。
- 添加依赖
2
3
4
5
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
- Kafka Source 提供了构建类来创建 KafkaSource 的实例。构建 KafkaSource 来消费 “input-topic” 最早位点的数据, 使用消费组 “my-group”,并且将 Kafka 消息体反序列化为字符串:
2
3
4
5
6
7
8
9
.setBootstrapServers(brokers)
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
- 以下属性在构建 KafkaSource 时是必须指定的:
- Bootstrap server,通过 setBootstrapServers(String) 方法配置
- 消费者组 ID,通过 setGroupId(String) 配置
- 要订阅的 Topic / Partition,
- 用于解析 Kafka 消息的反序列化器(Deserializer)
- Topic / Partition订阅
2
3
4
5
6
7
8
9
KafkaSource.builder().setTopics("topic-a", "topic-b");
// 正则表达式匹配,订阅与正则表达式所匹配的 Topic 下的所有 Partition:
KafkaSource.builder().setTopicPattern("topic.*");
// Partition 列表,订阅指定的 Partition:
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(
new TopicPartition("topic-a", 0), // Partition 0 of topic "topic-a"
new TopicPartition("topic-b", 5))); // Partition 5 of topic "topic-b"
KafkaSource.builder().setPartitions(partitionSet);
- 消费解析
2
3
4
// 如果只需要 Kafka 消息中的消息体(value)部分的数据,可以使用 KafkaSource 构建类中的 setValueOnlyDeserializer(DeserializationSchema) 方法,其中 DeserializationSchema 定义了如何解析 Kafka 消息体中的二进制数据。
// 也可使用 Kafka 提供的解析器 来解析 Kafka 消息体。例如使用 StringDeserializer 来将 Kafka 消息体解析成字符串:
KafkaSource.<String>builder() .setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));
- 起始偏移量
2
3
4
5
6
7
8
9
10
11
// 从消费组提交的位点开始消费,不指定位点重置策略
.setStartingOffsets(OffsetsInitializer.committedOffsets())
// 从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))
// 从时间戳大于等于指定时间的数据开始消费
.setStartingOffsets(OffsetsInitializer.timestamp(1592323200L))
// 从最早位点开始消费
.setStartingOffsets(OffsetsInitializer.earliest())
// 从最末尾位点开始消费
.setStartingOffsets(OffsetsInitializer.latest());
- 动态分区检查
2
3
4
// 分区检查功能默认不开启。需要显式地设置分区检查间隔才能启用此功能。
KafkaSource.builder()
.setProperty("partition.discovery.interval.ms", "10000"); // 每 10 秒检查一次新分区
CodeDemo
1 | package io.github.sourceOperator; |
自定义Source(MySQL举例)
1 | // 可以实现 SourceFunction 或者 RichSourceFunction , 这两者都是非并行的source算子 |
上面已经使用了自定义数据源和Flink自带的Kafka source,那么接下来就模仿着写一个从 MySQL 中读取数据的 Source。
- 建表语句
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
use flinkdemo;
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (10, 'dazhuang', '123456', '大壮');
INSERT INTO `user` VALUES (11, 'erya', '123456', '二丫');
INSERT INTO `user` VALUES (12, 'sanpang', '123456', '三胖');
SET FOREIGN_KEY_CHECKS = 1;
- 添加依赖
2
3
4
5
6
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
CodeDemo
1 | package io.github.sourceOperator; |
转换算子Transformation
转换算子
Flink中的算子,是对DataStream进行操作,返回一个新的DataStream的过程。Transformation 过程,是将一个或多个DataStream 转换为新的 DataStream,可以将多个转换组合成复杂的数据流拓扑。
Transformation:指数据转换的各种操作。有 map / flatMap / filter / keyBy / reduce / fold / aggregations / window / windowAll / union / window join / split / select / project 等,可以将数据转换计算成你想要的数据。
map映射:DataStream→DataStream
DataStream.map(MapFunction<T, R> mapper)
1 | /** |
flatmap扁平化映射:DataStream→DataStream
DataStream.flatMap(FlatMapFunction<T, R> flatMapper)
1 | /** |
filter过滤:DataStream→DataStream
DataStream.filter(FilterFunction
1 | /** |
keyBy按key分组:DataStream→KeyedStream
DataStream.keyBy(KeySelector<T, K> key)
1 | /** |
简单聚合:KeyedStream→DataStream
- sum():在输入流上,对指定的字段做叠加求和的操作。
- min():在输入流上,对指定的字段求最小值。
- max():在输入流上,对指定的字段求最大值。
- minBy():与 min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包含字段最小值的整条数据。
- maxBy():与 max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
reduce归约:KeyedStream→DataSream
KeyedStream.reduce(ReduceFunction
1 | /** |
转换算子Operator
1 | package io.github.transformation; |
物理分区
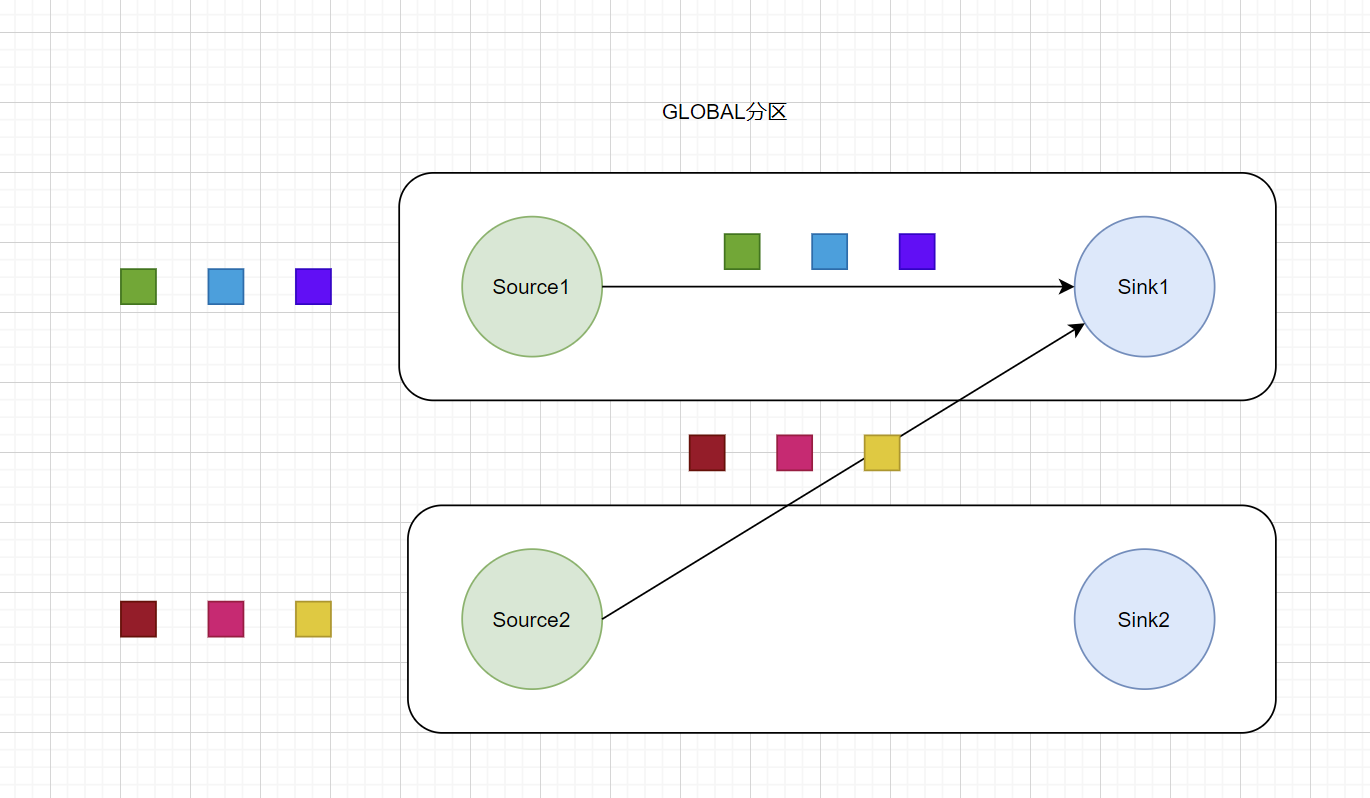
GLOBAL分区
GlobalPartitioner 分区器会将上游所有元素都发送到下游的第一个算子实例上(SubTask Id = 0):
1 |
|
1 | /** |
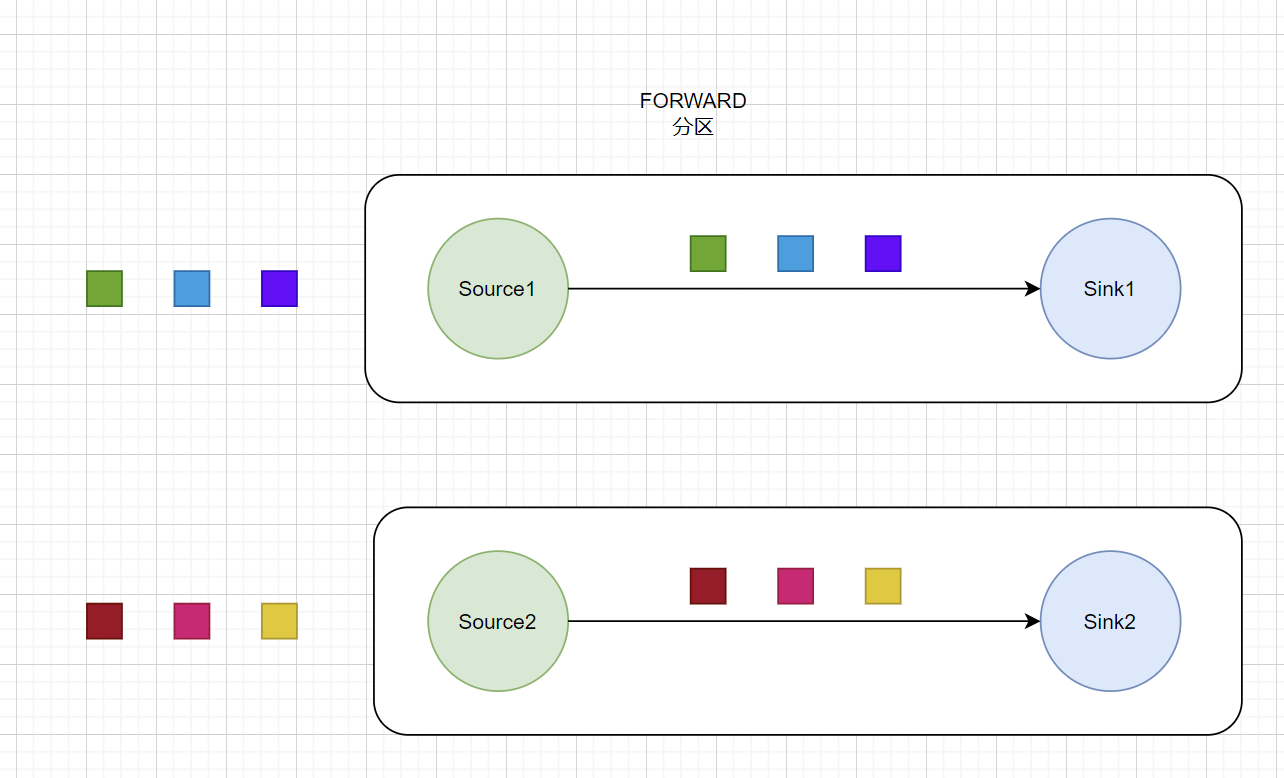
FORWARD分区
与 GlobalPartitioner 实现相同,但它只会将数据输出到本地运行的下游算子的第一个实例,而非全局。在上下游的算子没有指定分区器的情况下,如果上下游的算子并行度一致,则使用ForwardPartitioner,否则使用 RebalancePartitioner,对于ForwardPartitioner,必须保证上下游算子并行度一致,否则会抛出异常。
1 | /** |
1 | /** |
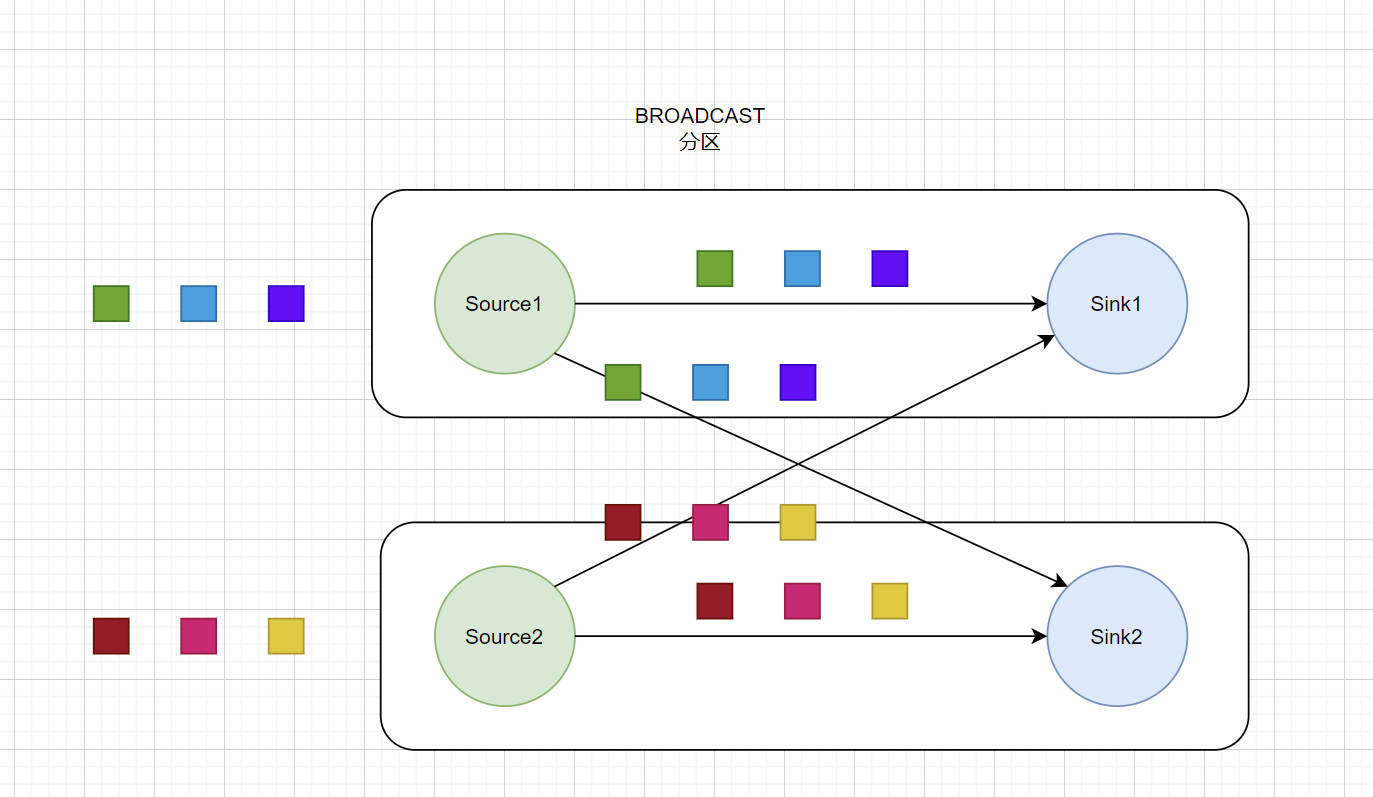
BROADCAST分区
广播分区将上游数据集输出到下游Operator的每个实例中。适合于大数据集Join小数据集的场景。
1 | /** |
1 | /** |
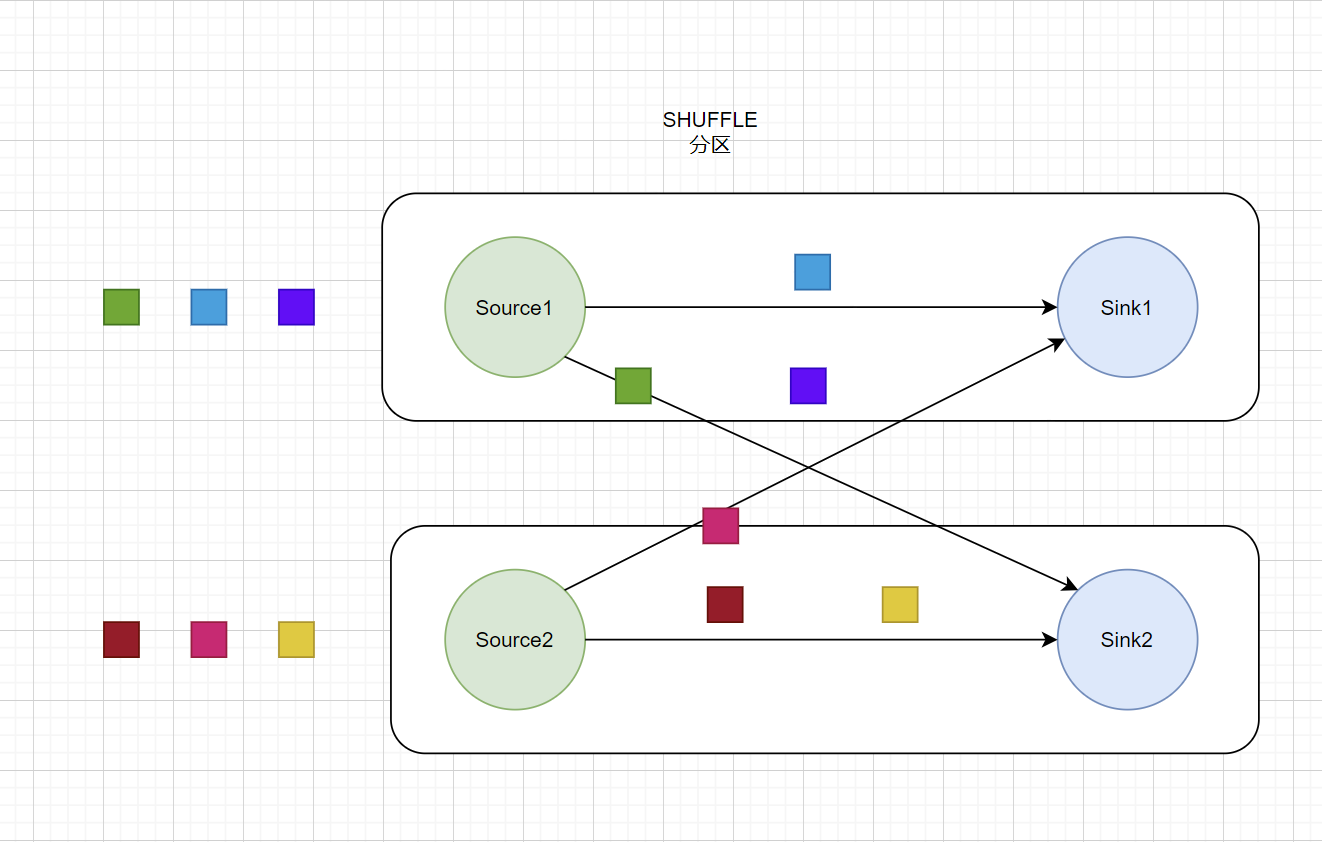
SHUFFLE分区
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区,因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
1 | /** |
1 | /** |
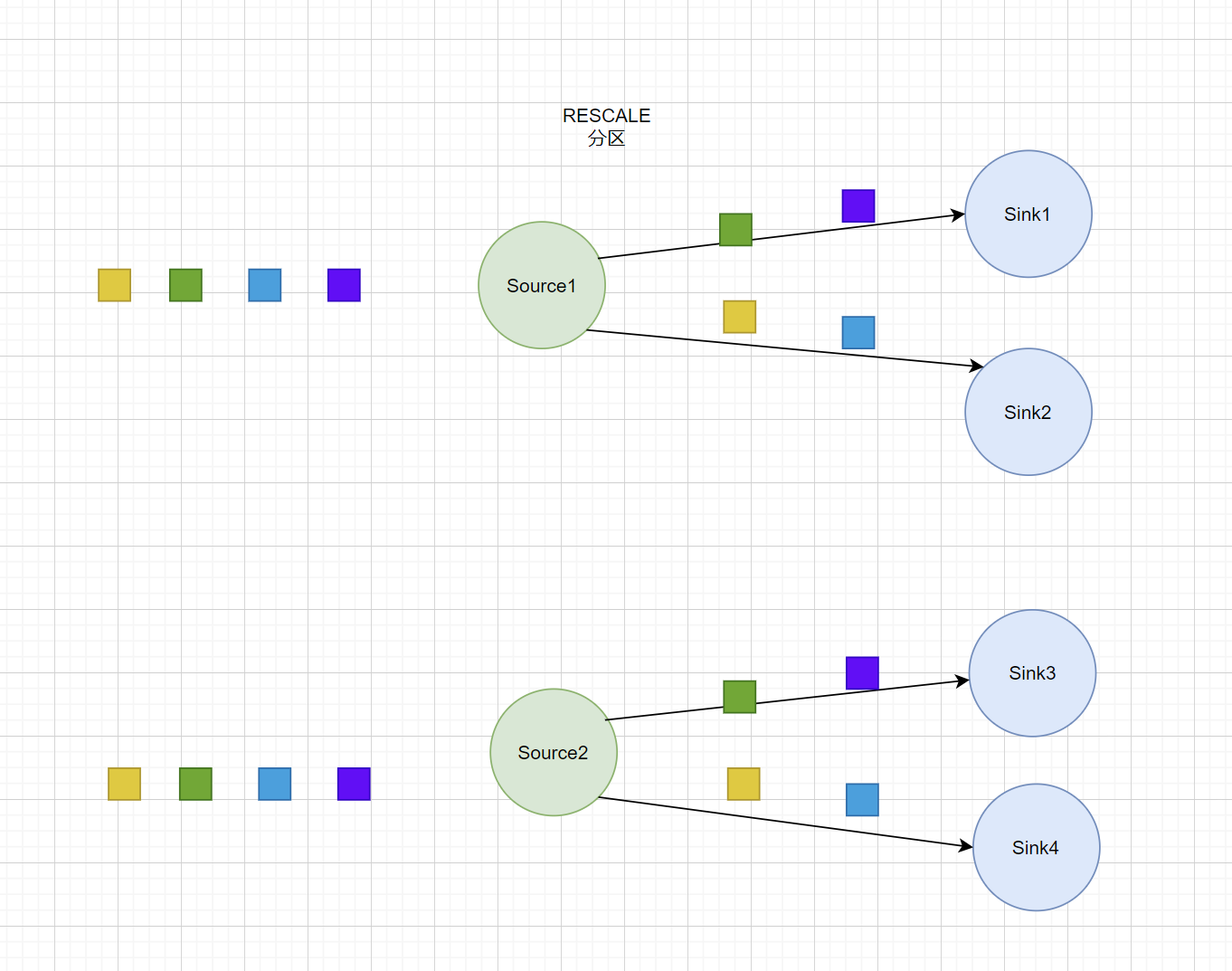
REBALANCE分区
基于上下游算子的并行度,将元素循环的分配到下游算子的某几个实例上。以上游算子并行度为 2,而下游算子并行度为 4 为例,当使用 RebalancePartitioner时,上游每个实例会轮询发给下游的 4 个实例。但是当使用 RescalePartitioner 时,上游每个实例只需轮询发给下游 2 个实例。因为 Channel 个数变少了,Subpartition 的 Buffer 填充速度能变快,能提高网络效率。当上游的数据比较均匀时,且上下游的并发数成比例时,可以使用 RescalePartitioner 替换 RebalancePartitioner。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
* Sets the partitioning of the {@link DataStream} so that the output elements are distributed
* evenly to a subset of instances of the next operation in a round-robin fashion.
*
* <p>The subset of downstream operations to which the upstream operation sends elements depends
* on the degree of parallelism of both the upstream and downstream operation. For example, if
* the upstream operation has parallelism 2 and the downstream operation has parallelism 4, then
* one upstream operation would distribute elements to two downstream operations while the other
* upstream operation would distribute to the other two downstream operations. If, on the other
* hand, the downstream operation has parallelism 2 while the upstream operation has parallelism
* 4 then two upstream operations will distribute to one downstream operation while the other
* two upstream operations will distribute to the other downstream operations.
*
* <p>In cases where the different parallelisms are not multiples of each other one or several
* downstream operations will have a differing number of inputs from upstream operations.
*
* @return The DataStream with rescale partitioning set.
*/
public DataStream<T> rescale() {
return setConnectionType(new RescalePartitioner<T>());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
* Partitioner that distributes the data equally by cycling through the output channels. This
* distributes only to a subset of downstream nodes because {@link
* org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator} instantiates a {@link
* DistributionPattern#POINTWISE} distribution pattern when encountering {@code RescalePartitioner}.
*
* <p>The subset of downstream operations to which the upstream operation sends elements depends on
* the degree of parallelism of both the upstream and downstream operation. For example, if the
* upstream operation has parallelism 2 and the downstream operation has parallelism 4, then one
* upstream operation would distribute elements to two downstream operations while the other
* upstream operation would distribute to the other two downstream operations. If, on the other
* hand, the downstream operation has parallelism 2 while the upstream operation has parallelism 4
* then two upstream operations will distribute to one downstream operation while the other two
* upstream operations will distribute to the other downstream operations.
*
* <p>In cases where the different parallelisms are not multiples of each other one or several
* downstream operations will have a differing number of inputs from upstream operations.
*
* @param <T> Type of the elements in the Stream being rescaled
*/
public class RescalePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo = -1;
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
if (++nextChannelToSendTo >= numberOfChannels) {
nextChannelToSendTo = 0;
}
return nextChannelToSendTo;
}
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
public SubtaskStateMapper getUpstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
public StreamPartitioner<T> copy() {
return this;
}
public String toString() {
return "RESCALE";
}
public boolean isPointwise() {
return true;
}
}
CUSTOM分区
自定义实现元素要发送到相对应的下游算子实例上
1 | /** |
Demo
1 | package io.github.pratitioner; |
输出算子Sink
FileSink
场景描述:
- 大数据业务场景中,经常有一种场景:外部数据发送到kafka中,Flink作为中间件消费kafka数据并进行业务处理;处理完成之后的数据可能还需要写入到数据库或者文件系统中,比如写入hdfs中。
- FileSink就可以用来将分区文件写入到支持 Flink FileSystem 接口的文件系统中,支持Exactly-Once语义。
- 这种sink实现的****Exactly-Once****都是基于Flink checkpoint来实现的两阶段提交模式来保证的,主要应用在实时数仓、topic拆分、基于小时分析处理等场景下。
实现原理:
- Bucket:FileSink可向由Flink FileSystem抽象支持的文件系统写入分区文件(因为是流式写入,数据被视为无界)。该分区行为可配,默认按时间,具体来说每小时写入一个Bucket,该Bucket包括若干文件,内容是这一小时间隔内流中收到的所有record。
- PartFile:每个Bucket内部分为多个PartFile来存储输出数据,该Bucket生命周期内接收到数据的sink的每个子任务至少有一个PartFile。
- FileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded,比如 Parquet)格式。
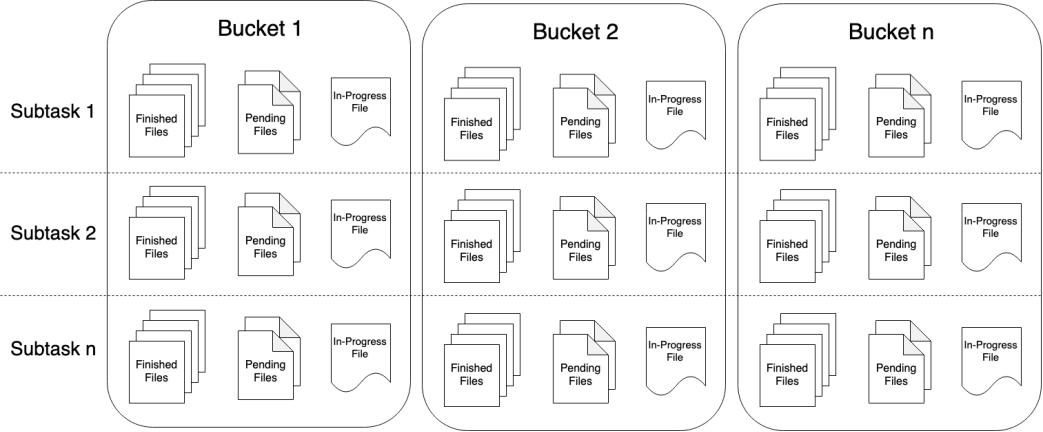
配置详解:
1-PartFile:每个Bucket内部分为多个部分文件,该Bucket内接收到数据的sink的每个子任务至少有一个PartFile。而额外文件滚动由可配的滚动策略决定。
- 生命周期:在每个活跃的Bucket期间,每个Writer的子任务在任何时候都只会有一个单独的In-progress PartFile,但可有多个Peding和Finished状态文件。
- In-progress :当前文件正在写入中
- Pending :当处于 In-progress 状态的文件关闭(closed)了,就变为 Pending 状态
- Finished :在成功的 Checkpoint 后,Pending 状态将变为 Finished 状态,处于 Finished 状态的文件不会再被修改,可以被下游系统安全地读取。
- 命名规则:
- In-progress / Pending:part-
- .inprogress.uid - Finished:part-
- 当 Sink Subtask 实例化时,它的 uid 是一个分配给 Subtask 的随机 ID 值。这个 uid 不具有容错机制,所以当 Subtask 从故障恢复时,uid 会重新生成 - Flink 允许用户给 Part 文件名添加一个前缀和/或后缀。 使用 OutputFileConfig 来完成。
- 注意:使用 FileSink 时需要启用 Checkpoint ,每次做 Checkpoint 时写入完成。如果 Checkpoint 被禁用,部分文件(part file)将永远处于 ‘in-progress’ 或 ‘pending’ 状态,下游系统无法安全地读取。
2-序列化编码:FileSink 支持行编码格式和批量编码格式( 比如:Apache Parquet) 。
FileSink.forRowFormat(basePath, rowEncoder)
必须配置项:
- 输出数据的BasePath
- 序列化每行数据写入PartFile的Encoder
使用RowFormatBuilder可选配置项:
- 自定义RollingPolicy:默认使用DefaultRollingPolicy来滚动文件,可自定义bucketCheckInterval
- 默认1分钟。该值单位为毫秒,指定按时间滚动文件间隔时间
FileSink sink = FileSink .forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8")) .withRollingPolicy( DefaultRollingPolicy.builder() .withRolloverInterval(Duration.ofMinutes(15)) .withInactivityInterval(Duration.ofMinutes(5)) .withMaxPartSize(MemorySize.ofMebiBytes(1)) .build()) .build()
FileSink.forBulkFormat(basePath, bulkWriterFactory)
- Bulk-encoded 的 Sink 的创建和 Row-encoded 的相似,但不需要指定 Encoder,而是需要指定 BulkWriter.Factory。 BulkWriter 定义了如何添加和刷新新数据以及如何最终确定一批记录使用哪种编码字符集的逻辑。
- 需要相关依赖
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
```xml
<!-- 应用FileSink功能所需要的依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>${parquet-avro}</version>
</dependency>
2
3
- 根据schema将数据写成parquet格式
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
Schema schema = SchemaBuilder.builder()
.record("DataRecord")
.namespace("cn.itcast.flink.avro.schema")
.fields()
.requiredInt("gid")
.requiredLong("ts")
.requiredString("eventId")
.requiredString("sessionId")
.name("eventInfo")
.type()
.map()
.values()
.type("string")
.noDefault()
.endRecord();
// 构造好一个数据流
DataStreamSource<EventLog> streamSource = env.addSource(new MySourceFunction());
// 2. 通过定义好的schema模式,来得到一个parquetWriter
ParquetWriterFactory<GenericRecord> writerFactory = AvroParquetWriters.forGenericRecord(schema);
// 3. 利用生成好的parquetWriter,来构造一个 支持列式输出parquet文件的 sink算子
FileSink<GenericRecord> sink1 = FileSink.forBulkFormat(new Path("d:/filesink/bulkformat"), writerFactory)
.withBucketAssigner(new DateTimeBucketAssigner<GenericRecord>("yyyy-MM-dd--HH"))
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(OutputFileConfig.builder().withPartPrefix("itcast").withPartSuffix(".parquet").build())
.build();
// 4. 将自定义javabean的流,转成 上述sink算子中parquetWriter所需要的 GenericRecord流
SingleOutputStreamOperator<GenericRecord> recordStream = streamSource
.map((MapFunction<EventLog, GenericRecord>) eventLog -> {
// 构造一个Record对象
GenericData.Record record = new GenericData.Record(schema);
// 将数据填入record
record.put("gid", (int) eventLog.getGuid());
record.put("eventId", eventLog.getEventId());
record.put("ts", eventLog.getTimeStamp());
record.put("sessionId", eventLog.getSessionId());
record.put("eventInfo", eventLog.getEventInfo());
return record;
}).returns(new GenericRecordAvroTypeInfo(schema)); // 由于avro的相关类、对象需要用avro的序列化器,所以需要显式指定AvroTypeInfo来提供AvroSerializer
// 5. 输出数据
recordStream.sinkTo(sink1).uid("fileSink");
env.execute();
2
- 传入普通JavaBean,然后工具可以自己通过反射手段来获取用户的普通JavaBean中的包名、类名、字段名、字段类型等信息,来翻译成一个符合Avro要求的Schema。
- 3-桶分配策略
- FileSink使用BucketAssigner来确定每条输入的数据应该被放入哪个Bucket,默认情况下,DateTimeBucketAssigner 基于系统默认时区每小时创建一个桶。
- Flink 有两个内置的 BucketAssigners :
- DateTimeBucketAssigner:默认基于时间的分配器
- BasePathBucketAssigner:将所有部分文件(part file)存储在基本路径中的分配器(单个全局桶)
- 4-滚动策略
- 滚动策略 RollingPolicy 定义了指定的文件在何时关闭(closed)并将其变为 Pending 状态,随后变为 Finished 状态。处于 Pending 状态的文件会在下一次 Checkpoint 时变为 Finished 状态,通过设置 Checkpoint 间隔时间,可以控制部分文件(part file)对下游读取者可用的速度、大小和数量。
- Flink 有两个内置的滚动策略:
- DefaultRollingPolicy
- OnCheckpointRollingPolicy
- 注意:使用Bulk Encoding时,文件滚动就只能使用OnCheckpointRollingPolicy的策略,该策略在每次checkpoint时滚动part-file。
文件合并:
在 Flink1.15 之后为了快速滚动,并且避免小文件的操作,添加了 compact 功能,可以在 checkpoint 的时候进行合并。
1 | FileSink<Integer> fileSink= |
- 参数设置
- setNumcCompactThreads:设置合并的线程数
- setSizeThreshold:设置大小的阈值(小于这个大小的会被合并)
- enableCompactionOnCheckpoint:多少个 checkpoint 信号来了,会进行一次 compact
- 如果开启了 Compaction,那么必须在 source.sinkTo(fileSink)的时候添加 uid:source.sinkTo(fileSink).uid(“fileSink”);
KafkaSink
Flink 与 Kafka 的连接器提供了端到端的精确一次(exactly once)语义保证,这在实际项目中是最高级别的一致性保证。
1 | // 1. 构造一个kafka的sink算子 |
JDBCSink
- 不保证Exactly-Once
1 | SinkFunction<EventLog> jdbcSink = JdbcSink.sink( |
- 保证Exactly-Once
1 | SinkFunction<EventLog> exactlyOnceSink = JdbcSink.exactlyOnceSink( |
 微信
微信 支付宝
支付宝