作业(Job)提交流程 高层级抽象视角
Flink 的提交流程,随着部署模式、资源管理平台的不同,会有不同的变化。首先我们从一个高层级的视角,来做一下抽象提炼,看一看作业提交时宏观上各组件是怎样交互协作的。
具体步骤如下:
(1) 一般情况下,由客户端(App)通过分发器提供的 REST 接口,将作业提交给JobManager。
(2)由分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
(3)JobMaster 将 JobGraph 解析为可执行的 ExecutionGraph,得到所需的资源数量,然后向资源管理器请求资源(slots)。
(4)资源管理器判断当前是否由足够的可用资源;如果没有,启动新的 TaskManager。
(5)TaskManager 启动之后,向 ResourceManager 注册自己的可用任务槽(slots)。
(6)资源管理器通知 TaskManager 为新的作业提供 slots。
(7)TaskManager 连接到对应的 JobMaster,提供 slots。
(8)JobMaster 将需要执行的任务分发给 TaskManager。
(9)TaskManager 执行任务,互相之间可以交换数据。
如果部署模式不同,或者集群环境不同(例如 Standalone、YARN、K8S 等),其中一些步骤可能会不同或被省略,也可能有些组件会运行在同一个 JVM 进程中。比如我们在上一章实践过的独立集群环境的会话模式,就是需要先启动集群,如果资源不够,只能等待资源释放,而不会直接启动新的 TaskManager。
Standalone集群
在独立模式(Standalone)下, TaskManager 都需要手动启动,所以当 ResourceManager 收到 JobMaster 的请求时,会直接要求 TaskManager 提供资源。提交的整体流程如图所示。
我们发现除去第 4 步不会启动 TaskManager,而且直接向已有的 TaskManager 要求资源,其他步骤与上一节所讲抽象流程完全一致。
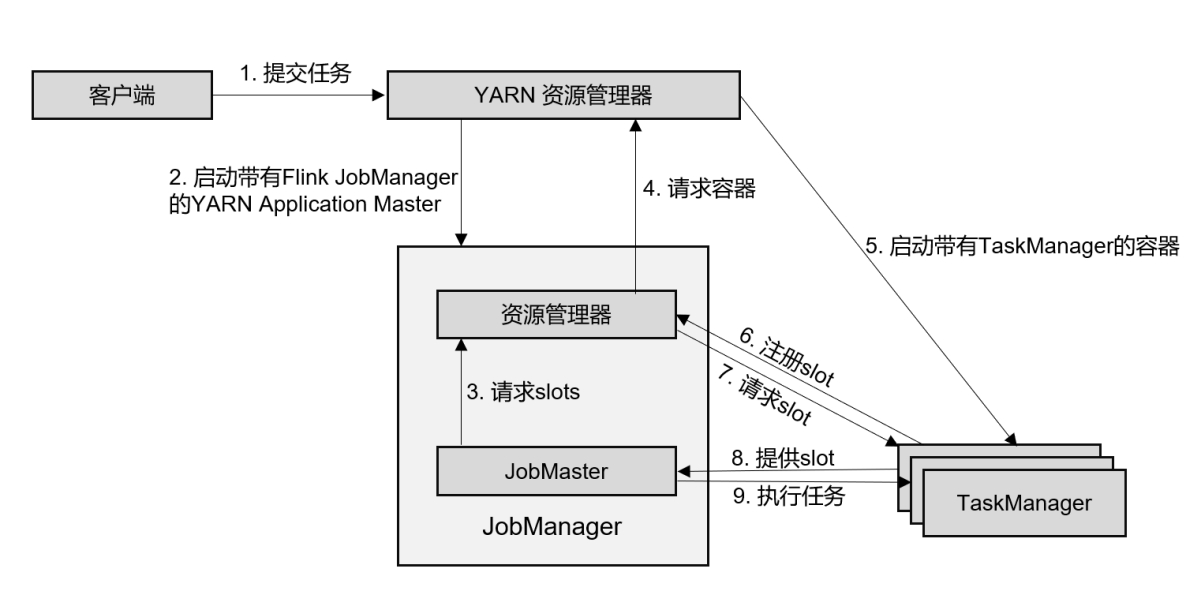
YARN 集群 会话(Session)模式
作业的流程,如上图所示:
(1)客户端通过 REST 接口,将作业提交给分发器。
(2)分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
(3)JobMaster 向资源管理器请求资源(slots)。
(4)资源管理器向 YARN 的资源管理器请求 container 资源。
(5)YARN 启动新的 TaskManager 容器。
(6)TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
(7)资源管理器通知 TaskManager 为新的作业提供 slots。
(8)TaskManager 连接到对应的 JobMaster,提供 slots。
(9)JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,整个流程除了请求资源时要“上报”YARN 的资源管理器,其他与 7.5.1 节所述抽象流程几乎完全一样。
单作业(Per-Job)模式
(1) 客户端将作业提交给 YARN 的资源管理器,这一步中会同时将 Flink 的 Jar 包和配置上传到 HDFS,以便后续启动 Flink 相关组件的容器。
(2) YARN 的资源管理器分配 Container 资源,启动 Flink JobManager,并将作业提交给JobMaster。这里省略了 Dispatcher 组件。
(3) JobMaster 向资源管理器请求资源(slots)。
(4) 资源管理器向 YARN 的资源管理器请求 container 资源。
(5) YARN 启动新的 TaskManager 容器。
(6) TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
(7) 资源管理器通知 TaskManager 为新的作业提供 slots。
(8) TaskManager 连接到对应的 JobMaster,提供 slots。
(9) JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,区别只在于 JobManager 的启动方式,以及省去了分发器。当第 2 步作业提交给JobMaster,之后的流程就与会话模式完全一样了。
应用(Application)模式 应用模式与单作业模式的提交流程非常相似,只是初始提交给 YARN 资源管理器的不再是具体的作业,而是整个应用。一个应用中可能包含了多个作业,这些作业都将在 Flink 集群中启动各自对应的 JobMaster。
standalone:集群提前启动,包括JM和TM,而且TM不能动态扩展
yarn session:集群提前启动,只启动JM,而TM根据需要动态启动(由flink的rm向yarn的rm请求资源,并由yarn的rm启动TM)
yarn per-job:集群不需要提前启动,客户端直接将作业提交给yarn的rm,由yarn的rm启动flink的JM(包括有JobMaster和rm,不再有分发器)
Flink编程模型
Flink 提供了不同的抽象级别以开发流式或批处理应用。
最顶层:SQL/Table API 提供了操作关系表、执行SQL语句分析的API库,供我们方便的开发SQL相关程序
中层:流和批处理API层,提供了一系列流和批处理的API和算子供我们对数据进行处理和分析
最底层:运行时层,提供了对Flink底层关键技术的操纵,如对Event、state、time、window等进行精细化控制的操作API
Flink编程实现 Flink程序构建流程
众嗦粥汁, Flink程序由四部分组成, 分别为运行环境, Source, Transformtion, Sink 四部分组成.
构建flink程序的上下文环境
构建source
处理数据
构建sink
Flink工程搭建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 <repositories > <repository > <id > aliyun</id > <url > http://maven.aliyun.com/nexus/content/groups/public/</url > </repository > <repository > <id > apache</id > <url > https://repository.apache.org/content/repositories/snapshots/</url > </repository > <repository > <id > cloudera</id > <url > https://repository.cloudera.com/artifactory/cloudera-repos/</url > </repository > </repositories > <properties > <project.build.sourceEncoding > UTF-8</project.build.sourceEncoding > <flink.version > 1.15.2</flink.version > <hive.version > 3.1.2</hive.version > <hadoop.version > 3.3.0</hadoop.version > <flink-shaded-hadoop.version > 3.1.1.7.2.9.0-173-9.0</flink-shaded-hadoop.version > <mysql.version > 5.1.48</mysql.version > <log4j.version > 2.17.1</log4j.version > <lombok.version > 1.18.22</lombok.version > <kafka.version > 3.0.0</kafka.version > <java.version > 11</java.version > <scala.version > 2.12</scala.version > <scala.binary.version > 2.12</scala.binary.version > <maven.compiler.source > ${java.version}</maven.compiler.source > <maven.compiler.target > ${java.version}</maven.compiler.target > </properties > <dependencies > <dependency > <groupId > org.scala-tools</groupId > <artifactId > maven-scala-plugin</artifactId > <version > ${scala.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-java</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-streaming-java</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-scala_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-cep</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-api-java</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-runtime</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-common</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-clients</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-queryable-state-runtime</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-api-java-bridge</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-api-scala-bridge_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-table-planner_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-streaming-scala_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-runtime-web</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-csv</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-json</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-parquet</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-connector-files</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > ${mysql.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-connector-jdbc</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-sql-connector-kafka</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-connector-base</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.kafka</groupId > <artifactId > kafka-clients</artifactId > <version > ${kafka.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-hadoop-compatibility_2.12</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-client</artifactId > <version > ${hadoop.version}</version > </dependency > <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-shaded-hadoop-3-uber</artifactId > <version > ${flink-shaded-hadoop.version}</version > </dependency > <dependency > <groupId > org.apache.logging.log4j</groupId > <artifactId > log4j-core</artifactId > <version > ${log4j.version}</version > </dependency > <dependency > <groupId > org.apache.logging.log4j</groupId > <artifactId > log4j-api</artifactId > <version > ${log4j.version}</version > </dependency > <dependency > <groupId > org.apache.logging.log4j</groupId > <artifactId > log4j-1.2-api</artifactId > <version > ${log4j.version}</version > <scope > test</scope > </dependency > <dependency > <groupId > org.apache.logging.log4j</groupId > <artifactId > log4j-slf4j-impl</artifactId > <version > ${log4j.version}</version > <scope > test</scope > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > <version > ${lombok.version}</version > </dependency > </dependencies > <build > <sourceDirectory > src/main/java</sourceDirectory > <plugins > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <version > 3.5.1</version > <configuration > <source > 1.8</source > <target > 1.8</target > </configuration > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-surefire-plugin</artifactId > <version > 2.18.1</version > <configuration > <useFile > false</useFile > <disableXmlReport > true</disableXmlReport > <includes > <include > **/*Test.*</include > <include > **/*Suite.*</include > </includes > </configuration > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-shade-plugin</artifactId > <version > 2.3</version > <executions > <execution > <phase > package</phase > <goals > <goal > shade</goal > </goals > <configuration > <filters > <filter > <artifact > *:*</artifact > <excludes > <exclude > META-INF/*.SF</exclude > <exclude > META-INF/*.DSA</exclude > <exclude > META-INF/*.RSA</exclude > </excludes > </filter > </filters > <transformers > <transformer implementation ="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer" > <mainClass > </mainClass > </transformer > </transformers > </configuration > </execution > </executions > </plugin > </plugins > </build >
Flink批处理实现 构建测试数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Total,time,BUILD,SUCCESS Final,Memory,Finished,at Total,time,BUILD,SUCCESS Final,Memory,Finished,at Total,time,BUILD,SUCCESS Final,Memory,Finished,at BUILD,SUCCESS BUILD,SUCCESS BUILD,SUCCESS BUILD,SUCCESS BUILD,SUCCESS BUILD,SUCCESS user_001,1621718199,10.1,电脑 user_001,1621718201,14.1,手机 user_002,1621718202,82.5,手机 user_001,1621718205,15.6,电脑 user_004,1621718207,10.2,家电 user_001,1621718208,15.8,电脑 user_005,1621718212,56.1,电脑 user_002,1621718260,40.3,家电 user_001,1621718580,11.5,家居 user_001,1621718860,61.6,家居
DataStreamAPI实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 package io.github.batch;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.java.ExecutionEnvironment;import org.apache.flink.api.java.operators.*;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.util.Collector;import org.omg.CORBA.Environment;public class WordCountBatchDataStream { public static void main (String[] args) throws Exception { ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); DataSource<String> text = env.readTextFile("/Users/Liguibin/Desktop/opt/Java/FlinkCode/src/main/resources/wordcount.txt" ); FlatMapOperator<String, String> wordDS = text.flatMap(new FlatMapFunction <String, String>() { @Override public void flatMap (String value, Collector<String> out) throws Exception { String[] strings = value.split("," ); for (String str : strings) { out.collect(str); } } }); MapOperator<String, Tuple2<String,Integer>> mapDs = wordDS.map(new MapFunction <String, Tuple2<String,Integer>>() { @Override public Tuple2<String,Integer> map (String value) throws Exception { return Tuple2.of(value, 1 ); } }); UnsortedGrouping<Tuple2<String,Integer>> groupBy = mapDs.groupBy(0 ); AggregateOperator<Tuple2<String,Integer>> sumDs = groupBy.sum(1 ); sumDs.print(); } }
TableAPI 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 package io.github.batch;import org.apache.flink.table.api.*;import org.omg.CORBA.Environment;import javax.swing.text.TableView;import static org.apache.flink.table.api.Expressions.$;public class WordCountBatchTable { public static void main (String[] args) { EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build(); TableEnvironment tEnv = TableEnvironment.create(settings); tEnv.createTemporaryTable("sourceTable" , TableDescriptor.forConnector("filesystem" ) .schema(Schema.newBuilder() .column("userId" , DataTypes.STRING()) .column("timestamp" ,DataTypes.BIGINT()) .column("money" , DataTypes.DOUBLE()) .column("category" , DataTypes.STRING()) .build()) .option("path" , "/Users/Liguibin/Desktop/opt/Java/FlinkCode/src/main/resources/order.csv" ) .option("format" , "csv" ) .build()); Table result = tEnv.from("sourceTable" ) .groupBy($("userId" )) .select($("userId" ), $("money" ).sum().as("totalMoney" )); tEnv.createTemporaryTable("sinkTable" , TableDescriptor.forConnector("print" ) .schema(Schema.newBuilder() .column("userId" , DataTypes.STRING()) .column("totalMoney" , DataTypes.DOUBLE()) .build()) .build()); result.executeInsert("sinkTable" ); } }
SQLAPI 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package io.github.batch;import org.apache.flink.table.api.EnvironmentSettings;import org.apache.flink.table.api.TableEnvironment;public class WordCountSql { public static void main (String[] args) { EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build(); TableEnvironment tEnv = TableEnvironment.create(settings); String DDLSource = "create table sourceTable (\n" + " userId STRING,\n" + " `timestamp` BIGINT,\n" + " money DOUBLE,\n" + " category STRING\n" + " ) WITH (\n" + " 'connector' = 'filesystem',\n" + " 'path' = '/Users/Liguibin/Desktop/opt/Java/FlinkCode/src/main/resources/order.csv',\n" + " 'format' = 'csv'\n" + ");" ; tEnv.executeSql(DDLSource); String DDLSink = "create table sinkTable(\n" + " userId STRING,\n" + " totalMoney DOUBLE\n" + " )WITH (\n" + " 'connector' = 'print'\n" + ");" ; tEnv.executeSql(DDLSink); String DMLResult = "insert into sinkTable select userId, SUM(money) as totalMoney from sourceTable group by userId;" ; tEnv.executeSql(DMLResult); } }
Flink流处理实现 DataStreamAPI 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 package io.github.stream;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.KeyedStream;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;import java.util.Arrays;public class WordCountDataStream { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> streamSource = env.socketTextStream("192.168.88.161" , 9999 ); SingleOutputStreamOperator<String> wordOp = streamSource.flatMap(new FlatMapFunction <String, String>() { @Override public void flatMap (String value, Collector<String> out) throws Exception { String[] strings = value.split(" " ); Arrays.stream(strings).forEach(out::collect); } }); SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneOp = wordOp.map(new MapFunction <String, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map (String value) throws Exception { return Tuple2.of(value, 1 ); } }); KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordAndOneOp.keyBy(t -> t.f0); SingleOutputStreamOperator<Tuple2<String, Integer>> summed = keyedStream.sum(1 ); summed.print(); env.execute(); } }
TableAPI 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 package io.github.stream;import org.apache.flink.connector.datagen.table.DataGenConnectorOptions;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.table.api.DataTypes;import org.apache.flink.table.api.Schema;import org.apache.flink.table.api.Table;import org.apache.flink.table.api.TableDescriptor;import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import static org.apache.flink.table.api.Expressions.$;public class WordCountTableAPI { public static void main (String[] args) { StreamExecutionEnvironment sEnv = StreamExecutionEnvironment.getExecutionEnvironment(); sEnv.setParallelism(2 ); StreamTableEnvironment tEnv = StreamTableEnvironment.create(sEnv); tEnv.createTemporaryTable("sourceTable" , TableDescriptor.forConnector("datagen" ) .schema(Schema.newBuilder() .column("word" , DataTypes.STRING()) .column("frequency" , DataTypes.BIGINT()) .build()) .option(DataGenConnectorOptions.ROWS_PER_SECOND, 1L ) .option("fields.word.kind" , "random" ) .option("fields.word.length" , "1" ) .option("fields.frequency.min" , "1" ) .option("fields.frequency.max" , "9" ) .build()); Table res = tEnv.from("sourceTable" ).groupBy($("word" )) .select($("word" ), $("frequency" ).sum().as("frequency" )); tEnv.createTemporaryTable("sinkTable" , TableDescriptor.forConnector("print" ) .schema(Schema.newBuilder() .column("word" , DataTypes.STRING()) .column("frequency" , DataTypes.BIGINT()) .build()) .build()); res.executeInsert("sinkTable" ); } }
SQLAPI 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package io.github.stream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;public class WordCountSql { public static void main (String[] args) { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env); String DDLSource = "create table sourceTable(\n" + " `word` STRING,\n" + " frequency BIGINT\n" + ") WITH (\n" + " 'connector' = 'datagen',\n" + " 'rows-per-second' = '1',\n" + " 'fields.word.kind' = 'random',\n" + " 'fields.word.length' = '1',\n" + " 'fields.frequency.min' = '1',\n" + " 'fields.frequency.max' = '2'\n" + ");\n" ; tEnv.executeSql(DDLSource); String DDLSink = "create table sinkTable(\n" + " `word` STRING,\n" + " frequency BIGINT\n" + ") WITH (\n" + " 'connector' = 'print'\n" + ");" ; tEnv.executeSql(DDLSink); String DMLComputeSql = "INSERT INTO sinkTable select `word` , SUM(frequency) as frequency from sourceTable group by `word`;" ; tEnv.executeSql(DMLComputeSql); } }
Lambda表达式处理DataStreamAPI 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package io.github.stream;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;import java.lang.reflect.Array;import java.util.Arrays;import java.util.function.Function;public class WordCountLambda { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.socketTextStream("node1" , 9999 ) .flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (value, out) -> Arrays.stream(value.split(" " )) .map(word -> Tuple2.of(word,1 )) .forEach(out::collect)) .returns(Types.TUPLE(Types.STRING, Types.INT)) .keyBy(t -> t.f0) .sum(1 ) .print(); env.execute(); } }
提交Flink任务到服务器 Code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package io.github.submit;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.api.java.utils.ParameterTool;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;import java.util.Arrays;import java.util.function.Function;public class WordCount { public static void main (String[] args) throws Exception { ParameterTool parameterTool = ParameterTool.fromArgs(args); String outPut = "" ; if (parameterTool.has("output" )){ outPut = parameterTool.get("output" ); }else { outPut = "hdfs://node1:8020/wordcount/output01_" ; } StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> streamSource = env.fromElements("hadoop spark flink" , "hadoop spark sqoop" ); SingleOutputStreamOperator<Tuple2<String, Integer>> res = streamSource.flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (value, out) -> { Arrays.stream(value.split(" " )) .map((Function<String, Tuple2>) s -> Tuple2.of(s, 1 )) .forEach(out::collect); }).returns(Types.TUPLE(Types.STRING, Types.INT)) .keyBy(s -> s.f0) .sum(1 ); System.setProperty("HADOOP_USER_NAME" , "root" ); res.writeAsText(outPut + System.currentTimeMillis()).setParallelism(1 ); env.execute(); } }
Process Maven打包
这里使用了打包插件(Shade), 又是一个小细节.
提交到8081端口
拷贝主程序入口(路径)
在Linux提交Flink任务
Yarn三种模式下的任务提交
还有一种是StandAlone下的任务提交, 这里就由于不太清楚就不多介绍了.
Yarn的三种模式Session, Per-job, Application三种模式.
YARN Session提交任务 前提
这种模式下会启动yarn session,并且会启动Flink的两个必要服务:JobManager和Task-managers,然后你可以向集群提交作业。同一个Session中可以提交多个Flink作业。需要注意的是,这种模式下Hadoop的版本至少是2.2,而且必须安装了HDFS(因为启动YARN session的时候会向HDFS上提交相关的jar文件和配置文件)
启动YarnSession和提交任务方法 1 2 3 4 yarn-session.sh -tm 1024 -s 4 -d flink run -p 8 /export/server/flink/examples/batch/WordCount.jar
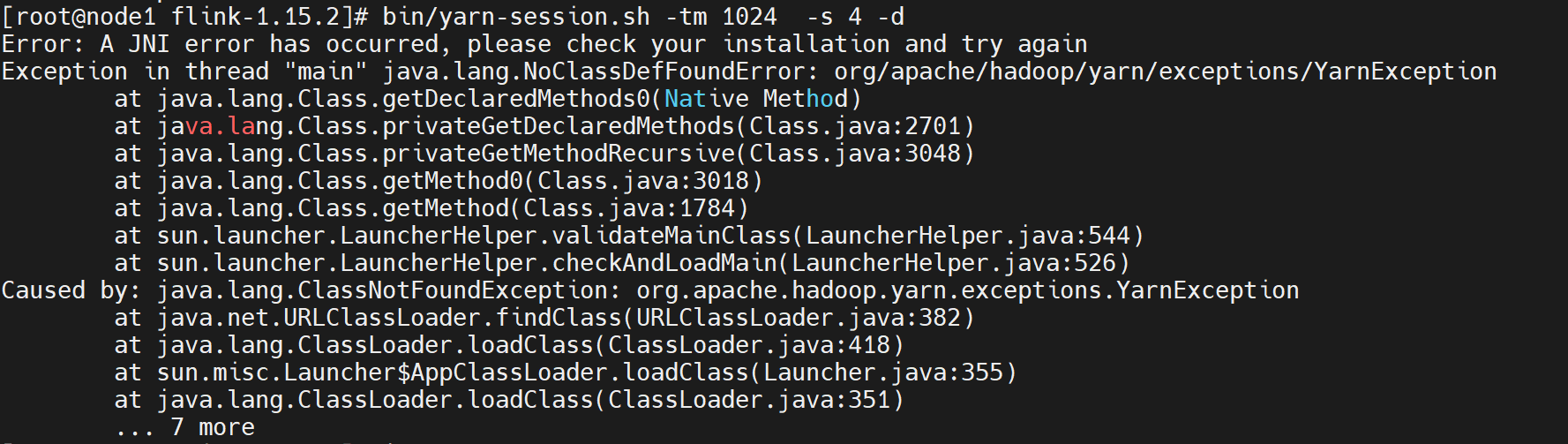
启动YARN Session报错一:
解决办法:
缺失依赖:flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar,将之上传至flink根目录下的lib目录下
启动YARN Session报错二:
解决办法:
缺失依赖:commons-cli-1.5.0.jar,将之上传至flink根目录下的lib目录下
相关参数 1 2 3 4 5 6 7 -n(--container):TaskManager的数量。(1.10 已经废弃) -s(--slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。 -jm:JobManager的内存(单位MB)。 -q:显示可用的YARN资源(内存,内核); -tm:每个TaskManager容器的内存(默认值:MB) -nm:yarn 的appName(现在yarn的ui上的名字)。 -d:后台执行。
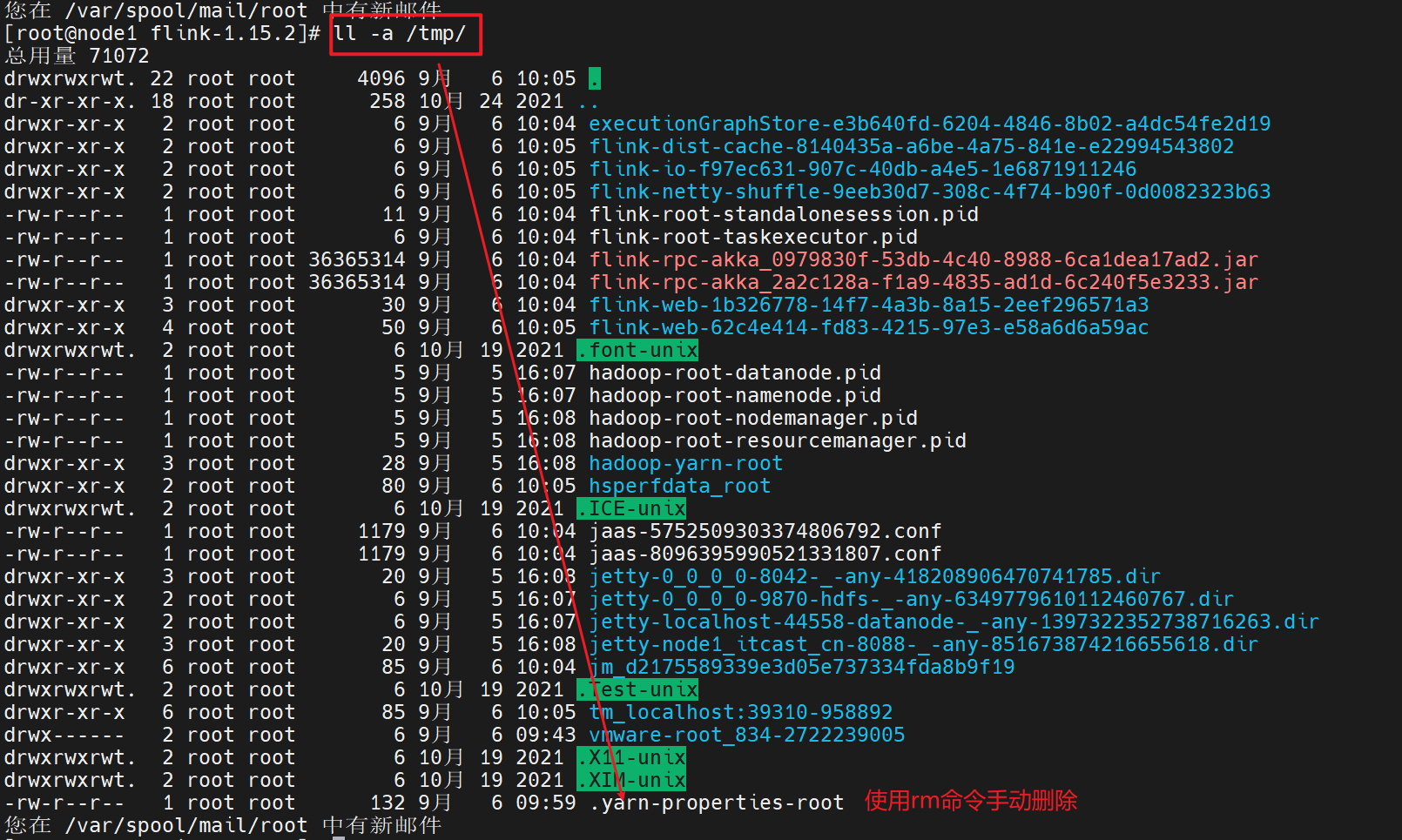
停止当前任务 1 2 3 4 5 6 # 第一种推荐 echo "stop" | yarn-session.sh -id application_1662342426082_0001 # 第二种不推荐 yarn application -kill application_1662342426082_0001 # 会话模式将在/tmp中创建一个隐藏的 YARN 属性文件,提交作业时,命令行界面将选取该文件以进行群集发现。/tmp/.yarn-properties-<username>。 # 采用第一种方式,会自动删除该文件,如果采用kill 直接杀掉该任务,不会删除该隐藏文件。
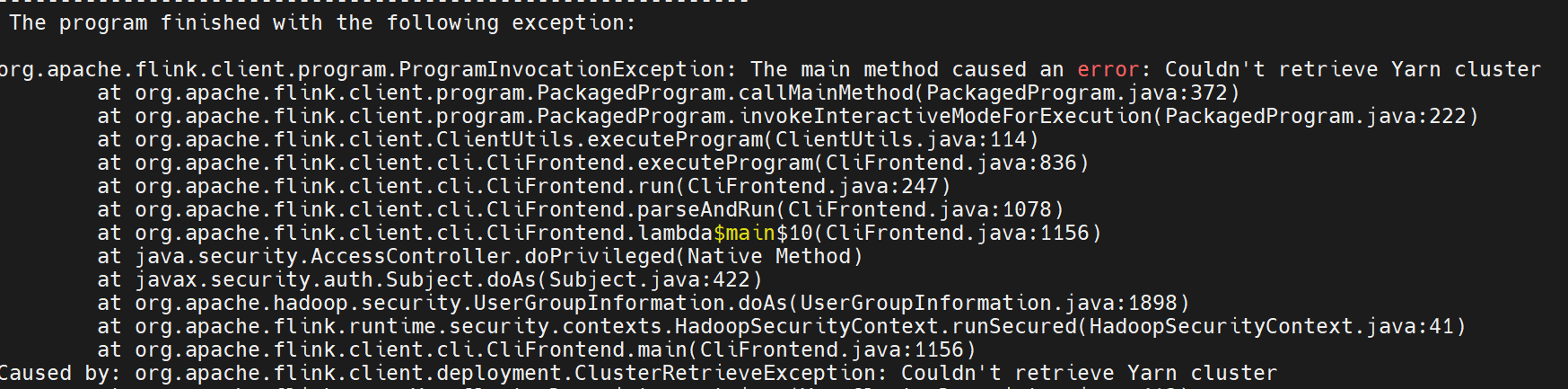
停止任务后再次提交任务报错
当前使用yarn application -kill方式停止yarn-session集群后,再次使用yarn standalone集群提交任务会报错
解决办法:
需要手动删除yarn-session运行时留下的临时文件
YARN Per-Job提交任务
上面的YARN session是在Hadoop YARN环境下启动一个Flink cluster集群,里面的资源是可以共享给其他的Flink作业。我们还可以在YARN上启动一个Flink作业,这里我们还是使用./bin/flink,但是不需要事先启动YARN session:
使用flink直接提交任务 1 flink run -m yarn-cluster /export/server/flink/examples/batch/WordCount.jar
常用参数: 1 2 3 4 5 6 7 8 9 10 --p 程序默认并行度 下面的参数仅可用于 -m yarn-cluster 模式 --yjm JobManager可用内存,单位兆 --ynm YARN程序的名称 --yq 查询YARN可用的资源 --yqu 指定YARN队列是哪一个 --ys 每个TM会有多少个Slot --ytm 每个TM所在的Container可申请多少内存,单位兆 --yD 动态指定Flink参数 --yd 分离模式(后台运行,不指定-yd, 终端会卡在提交的页面上)
停止yarn-cluster 1 2 3 4 5 6 7 8 9 10 11 12 yarn application -kill application的ID flink run \ -m yarn-cluster \ -yD fs.overwrite-files=true examples/batch/WordCount.jar \ -yD fs.overwrite-files=true \ -yD taskmanager.network.numberOfBuffers=16368
Application Mode提交任务
application 模式使用 flink run-application 提交作业;通过 -t 指定部署环境,目前 application 模式支持部署在 yarn 上(-t yarn-application) 和 k8s 上(-t kubernetes-application);并支持通过 -D 参数指定通用的 运行配置,比如 jobmanager/taskmanager 内存、checkpoint 时间间隔等。
Tips 通过 flink run-application -h 可以看到 -D/-t 的详细说明
任务提交
带有 JM 和 TM 内存设置的命令提交, 并且自己设置 TaskManager slots 个数为3,以及指定并发数为3
1 2 3 4 5 6 flink run-application -t yarn-application -p 3 \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=1024m \ -Dyarn.application.name="MyFlinkWordCount" \ -Dtaskmanager.numberOfTaskSlots=3 \ /export/server/flink/examples/batch/WordCount.jar --output hdfs://node1:8020/wordcount/output_52
指定并发还可以使用如下命令-Dparallelism.default=3来代替 -p 3
1 2 3 4 5 6 7 8 flink run-application -t yarn-application \ -Dparallelism.default=3 \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=1024m \ -Dyarn.application.name="MyFlinkWordCount" \ -Dtaskmanager.numberOfTaskSlots=3 \ /export/server/flink/examples/batch/WordCount.jar --output hdfs://node1:8020/wordcount/output_53
任务提交yarn.provided.lib.dirs参数
yarn.provided.lib.dirs参数一起使用,可以充分发挥 application 部署模式的优势
但是, 如果自己指定 yarn.provided.lib.dirs,有以下注意事项:
需要将 lib 包和 plugins 包地址用;分开,从上面的例子中也可以看到,将 plugins 包放在 lib 目录下可能会有包冲突错误
plugins 包路径地址必须以 plugins 结尾,例如上面例子中的 hdfs://node1.itcast.cn:8020/flink/plugins
hdfs 路径必须指定 nameservice(或 active namenode 地址),而不能使用简化方式(例如 hdfs://node1.itcast.cn:8020/flink/libs)
该种模式的操作使得 flink 作业提交变得很轻量,因为所需的 Flink jar 包和应用程序 jar 将到指定的远程位置获取,而不是由客户端下载再发送到集群。这也是社区在 flink-1.11 版本引入新的部署模式的意义所在。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 # 上传 Flink 相关 plugins 到hdfs cd /export/server/flink/plugins hdfs dfs -mkdir /flink/plugins hdfs dfs -put \ external-resource-gpu/flink-external-resource-gpu-1.15.2.jar \ metrics-datadog/flink-metrics-datadog-1.15.2.jar \ metrics-graphite/flink-metrics-graphite-1.15.2.jar \ metrics-influx/flink-metrics-influxdb-1.15.2.jar \ metrics-jmx/flink-metrics-jmx-1.15.2.jar \ metrics-prometheus/flink-metrics-prometheus-1.15.2.jar \ metrics-slf4j/flink-metrics-slf4j-1.15.2.jar \ metrics-statsd/flink-metrics-statsd-1.15.2.jar \ /flink/plugins # 根据自己业务需求上传相关的 jar cd /export/server/flink/lib hdfs dfs -mkdir /flink/lib hdfs dfs -put ./* /flink/lib # 上传用户需要运行的作业jar 到 hdfs cd /export/server/flink hdfs dfs -mkdir /flink/user-libs hdfs dfs -put ./examples/batch/WordCount.jar /flink/user-libs # 提交任务 flink run-application -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=1024m \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=2 \ -Dyarn.provided.lib.dirs="hdfs://node1.itcast.cn:8020/flink/lib;hdfs://node1.itcast.cn:8020/flink/plugins" \ -Dyarn.application.name="batchWordCount" \ hdfs://node1.itcast.cn:8020/flink/user-libs/WordCount.jar \ --output hdfs://node1:8020/wordcount/output_54 # 也可以将 yarn.provided.lib.dirs 配置到 conf/flink-conf.yaml,这时提交作业就和普通作业没有区别了:
模式切换注意事项
如果使用的是flink on yarn方式,想切换回standalone模式的话,需要删除文件:/tmp/.yarn-properties-因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager
如果是分离模式运行的YARN JOB后,其运行完成会自动删除这个文件
但是会话模式的话,如果是kill掉任务,其不会执行自动删除这个文件的步骤,所以需要我们手动删除这个文件。









 微信
微信 支付宝
支付宝