
【富华保险】项目简介及项目配置流程和启动
本项目涵盖两方面的内容:
- 保险数仓
- 保险用户画像
项目背景
精算说明
整个保险行业中, 最为核心的技术就是
精算, 精算简单来说, 就是根据不同年龄以及保额来计算需要收取多少保费的问题, 精算的出现改变了从早期的经验判断的方案来确定保费阶段, 让保险行业更加的专业化, 精细化 , 准确化精算行业并不仅仅解决保费的问题, 包含有: 确保保费的费率, 应付意外损失的准备金、自留限额、未到期责任准备金和未决赔款准备金等方面, 都力求采用更精确的方式取代以前的经验判断
保险精算学主要研究事故的出险规律、损失的分布规律、保费的厘定、保险产品的设计、准备金的提取、偿付能力等保险具体问题
精算发展里程
发展里程说明:
- 1693年,英国大数学家、天文学家哈雷编制出第一张生命表,这就标志着精算学的诞生。
- 1757年,英国人简姆士·丹松首先提出应按保险人的年龄和保额收取保费,即提出保费的计算应考虑死亡率的大小。至此,精算思想正式进入人寿保险领域。
- 1764年,英国的爱德沃创办了世界上第一家人寿保险公司——伦敦公平人寿保险社,采用了简姆士·丹松的计算保费的思想和方法,并设立了专门的精算技术部门,承担分析保险公司的利润来源、编制生命表、测定人口死亡率等,把精算技术作为保险经营决策的依据,使得保险公司的效益稳定、业绩领先。
- 保险公司官网
https://www.pingan.com/official/home-a?channel_id=1
保险Industry重要相关概念
风险:精算学是对风险的评价和制定经济安全方案的方法体系。而风险的重要特征是:不确定性!
寿险:以人的生命为保险标的的保险,人的生存与死亡决定保险金的给付与否及给付时间。如,终身寿险,定期寿险,两全保险,生存年金,万能寿险,分红保险等。
非寿险:财产保险、责任保险、健康保险、意外伤害保险
投保人: 指的申购或者缴纳保费的人
被保人: 以谁的生命作为标的(自然人)
可能是投保人,也可能是投保的利益关联人
受益人: 当进行理赔的时候, 获取理赔金的人
保险人: 指的是保险公司
保险准备金: 保险准备金是指保险人为保证其如约履行保险赔偿或给付义务,根据政府有关法律规定或业务特定需要,从保费收入或盈余中提取的与其所承担的保险责任相对应的一定数量的基金,类似存款准备金:20% 1万亿存款,0.2 * 1万亿 = 2千亿, 可用活动资金 = 8千亿
生命表: 根据以往一定时期内容各种年龄死亡统计资源 编制一种统计表
保费: 投保人向保险公司缴纳的费用
责任: 保险公司向被保人,提供的保障责任是多方面的,比如医疗门诊责任,医疗住院责任,自然死亡责任,意外死亡责任,残疾责任,重疾赔付责任,住院津贴责任等等。
保额、保险金、责任保险金: 如果客户在某个责任达到获赔条件,向保险公司申请赔付,保险公司提供的最大的保障金额。
新单、新契约: 购买的保单在首年内,称为新单,或新契约
续期: 对长期险来说,持续几年都会交保费,从第二期保费开始,称为续期。
理赔: 如果客户出险了,保险公司需要按照保单合约,对客户进行理赔,相应会支付理赔金。
免责条款:提前说好有些因素造成的风险,保险公司不赔。比如酒后驾车,或者战乱,核爆炸等等引起的重疾和死亡,都在责任免除的范围内。
既往症:被保人在投保前就患有的疾病。或者没有确诊,但是已经有明显的症状,表明是某种病的迹象,也会给认作既往症。保险公司也是不赔的。保险公司设定既往症不赔的目的,很简单,就是避免有些人,已经有明显感觉到自己是某种病了,然后再去带病投保。
保障期限:保险保多久,如30年、保至70岁、保终身等
缴费期:交多少年保费,如20年、30年等
等待期:投保后,保单生效起至指定时期内(一般是30-180天不等)若出险,保险公司不赔。原因可以参考既往症。
犹豫期:投保后可无条件申请退保的一段时间。犹豫期一般是15天,犹豫期内退保,是全额退保的。
宽限期:到期后没交后期保费,保险合同仍有效的时间,通常为60天
复效期:超过宽限期仍未交保费,保单失效,此时若能在一定时间内补交上保费,保单继续有效,否则彻底终止。
保险精算[精度损失设置]
- 保险的指标计算对精度要求是比较高的, 目前这款保险项目精度要求: 最终结果不能超过1元, 内部结果的指标结果, 不能超过 0.1元: decimal(17,12) 表示小数位12位. 总位数是 17位
- 保险行业实时需求比较少, 因为保险中交易频次比较低的, 但是历史存量数据极高的, 所有大多数的场景都是针对过去历史数据进行统计分析操作
1 | -- 注意:使用spark,保险、金融、证券都需要设置不允许精度损失 |
保险分类
- 风险转移类保险
- 寿险: 解决家庭责任
- 定期寿险
- 两全寿险
- 终身寿险
- 健康险: 解决因病致贫 看病少花钱
- 医疗险
- 重疾险
- 意外险: 解决家庭责任
- 意外医疗
- 意外身故
- 意外伤残
- 理财型保险
- 年金保险
- 万能险
- 投递连结险
数据来源
- 理赔数据Oracle数据源
- 介绍:记录客户出现死亡,医疗意外等,保险公司需要赔付的信息,该数据库记录出险时间、详情等,赔付金额等。
- 理赔数据量,基于用户量,一般平均一个用户理赔1~3次
- 精算数据MySQL数据源
- 介绍:存储保单的现金价值,准备金,生存金,婚假金,教育金,理财收益等结果数据,以及保费的确定,需要精算师的参与,大数据工程师跟精算师沟通。
- 数据量小,一般就是几千条
- 保单数据PostgreSQL数据源
- 介绍:保单数据存储具体客户保单的详情,比如投保时间,地点,产品以及缴费时长等信息。
- 在不同的部门下, 或者不同的业务下, 可能选择的数据库都是不一样的, 所以在一个公司中, 数据源不仅仅只有一个
- postgresql是开源的,支持分区,支持存储过程,支持使用其他数据库,进行分布横向扩展(greenplum)
- 本项目主要采用MySQL作为统一数据源来处理, 存储 理赔 精算 保单 数据 方便学习使用
数仓架构
离线架构:mysql→sqoop→hive→es→spark SQL→es→presto
实时架构:日志文件→flume→kafka→spark SQL→mysql→presto
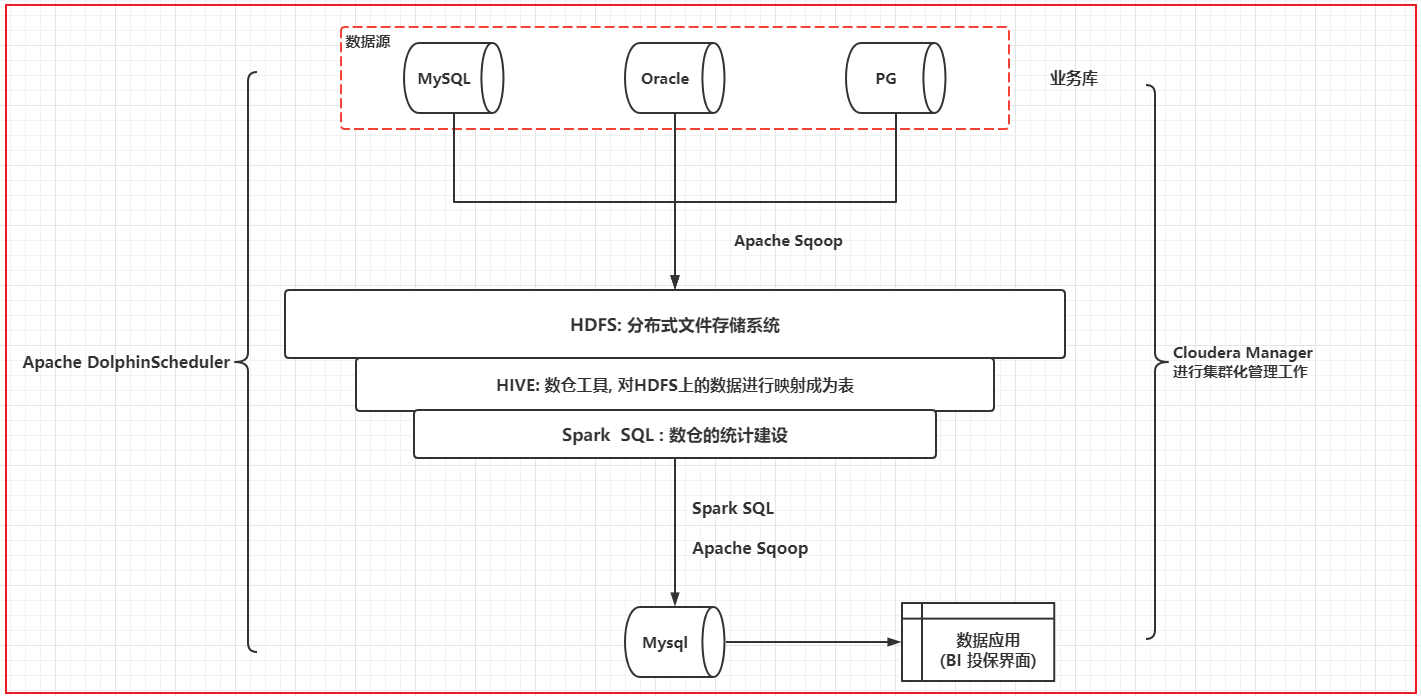
保险数仓实现
涉及的指标
1 | 业务发展类指标 |
技术选型:
1 | Spark2.4.8 + Elasticsearch7.10 + Hadoop2.7 + Hive2.1 + Flume1.10 + Zookeeper3.4 + Kafka2.11 + Dolphinscheduler2.0 + Mysql5.7 |
涉及流程:
1 | 项目业务流程: |
项目配置
1 | 20台服务器的集群, 当前这个项目使用资源是200个cpu, 600g内存 |
项目周期
2
3
4
5
6
7
阶段划分:
需求调研, 评审 (4周)
架构设计: 1周
编写和集成: 12周
测试: 2周 (分散的两周, 因为测试是阶段测试)
上线部署: 3周 (每完成一个阶段, 完成一次阶段上线, 实现敏捷开发)
项目环境及配置
- 启动hadoop相关服务
1 | hdfs分布式文件系统服务 |
- 启动Hive相关服务
1 | 启动hive元数据服务 |
- 启动elasticsearch服务
1 | su es |
- 启动presto服务
1 | /export/server/presto/bin/launcher run & |
- 安装python elasticsearch模块
1 | 并此环境中安装elasticsearch库: |
- 安装pyspark源码插件
1 | conda activate pyspark_env |
- 使用spark-sumbit脚本提交spark任务到yarn测试环境
1 | /export/server/spark/bin/spark-submit --master yarn --deploy-mode cluster --executor-memory 1G --num-executors 2 /export/server/spark/examples/src/main/python/pi.py 100 |
datagrip连接mysql(up01:3306)、hive(up01:10000)、presto(up01:8090)
启动flume服务
安装:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15下载并上传到服务器存放软件的目录,解压
apache-flume-1.10.1-bin.tar.gz
解压
tar zxvf apache-flume-1.10.1-bin.tar.gz -C /export/server
创建软链接
ln -s apache-flume-1.10.1-bin/ flume
cd /export/server/flume/conf
cp flume-env.sh.template flume-env.sh
chmod u+x flume-env.sh
修改文件内容
打开注释,设置jdk路径
export JAVA_HOME=/export/server/jdk测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40# 1.启动flume采集日志数据到kafka的相关服务: zookeeper、kafka、数据、flume的配置文件、启动agent的命令
已启动服务 :zk、kafka
# 2.配置flume采集日志目录下文件数据到kafka的conf文件
日志目录=/root/logs/nginx_log
nginx_kafka_test.conf:
a1.channels = c1
a1.sources = s1
a1.sinks = k1
# spooldir监控文件目录,目录有新文件生成就会读取
# 文件一旦生成内容不能改变
# 文件名不能修改
a1.sources.s1.type = spooldir
a1.sources.s1.spoolDir = /root/logs/nginx_log
a1.sources.s1.fileHeader = true
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /mnt/flume/checkpoint
a1.channels.c1.dataDirs = /mnt/flume/data
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = nginx_test_topic
a1.sinks.k1.kafka.bootstrap.servers = up01:9092
a1.sinks.k1.kafka.flumeBatchSize = 3
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
#a1.sinks.k1.kafka.producer.compression.type = snappy
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
# 3.启动agent
cd $FLUME_HOME
bin/flume-ng agent -n a1 -c conf -f conf/nginx_kafka_test.conf
# 4.上传测试数据到: `/root/logs/nginx_log`
# 5.使用kafkatool2工具 到kafka中查看数据内容和核对总记录与采集的记录数是否一致
启动zookeeper
1 | /export/server/zookeeper/bin/zkServer.sh start |
- 启动kafka
1 | nohup /export/server/kafka/bin/kafka-server-start.sh /export/server/kafka/config/server.properties 2>&1 >> /tmp/kafka.out & |
- 启动dolphinscheduler
1 | 先安装配置 |
需求
标签计算
在实现标签之前,使用sql先导入标签规则
匹配和统计(22个标签):
- policy_client:性别、身高、年龄、省份、城市、区域、收入、名字、婚姻状况、民族、学历、星座
- policy_benefit:缴费期(统计)、投保年龄、最近购买周期(统计)、保险类型、保单是否有效
- policy_surrender:keep_days计算保单持有周期(统计年、天)
- claim_info:购买周期,理赔周期、理赔责任类型、理赔金额高
标签开发需求分析:(共计22个)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29# 1.投保客户表(用户会员) => 匹配
user_id
sex 性别标签
height 身高标签
birthday 年龄标签
province 省区域标签
city 市区域标签
direction 华中、华东、华南、华西、华北
income 收入
race 名族
marriage_state 婚姻状况
edu 教育程度
sign 星座
# 2.投保记录表 => 统计
ppp 缴费期
age_buy 购买保险年龄
buy_datetime 投保日期,购买周期标签
insur_name、insur_code 保险类型
pol_flag 保单状态
elapse_date 保单失效时间,统计到期的保险日期(7, 30, 90, 180, 365)
# 3.理赔记录表 => 统计
claim_date 理赔日期
claim_item 理赔责任
claim_mnt 理赔金
# 4.退保记录表 => 统计
keep_days 保单持有日期(天)
 微信
微信 支付宝
支付宝