决策树算法 树可以分为多种类型,包括二叉树、二叉搜索树、AVL树、红黑树、B树、B+树等等。
二叉树是一种特殊的树,它的每个节点最多只有两个子节点,分别称为左子节点和右子节点。
二叉搜索树是一种二叉树,它的每个节点都满足左子节点的值小于当前节点的值,右子节点的值大于当前节点的值。这种特性使得二叉搜索树可以快速地进行查找、插入和删除操作。
AVL树是一种自平衡二叉搜索树,它通过旋转操作保持树的平衡,以保证查找、插入和删除操作的时间复杂度为O(log2 n)。
红黑树也是一种自平衡二叉搜索树,它通过颜色标记节点来保持树的平衡,以保证查找、插入和删除操作的时间复杂度为O(log n)。
B树和B+树是一种多路搜索树,它的每个节点可以存储多个值,并且可以有多个子节点。B树和B+树主要用于磁盘存储数据的索引,可以有效地减少磁盘I/O操作的次数,提高数据的访问效率。
什么是决策树 决策树算法是一种监督学习算法,英文是Decision tree。
决策树是一个类似于流程图的树结构:其中,每个内部结点表示一个特征或属性,而每个树叶结点代表一个分类。树的最顶层是根结点。使用决策树分类时就是将实例分配到叶节点的类中。该叶节点所属的类就是该节点的分类。
决策树思想的来源非常朴素,试想每个人的大脑都有类似于if-else这样的逻辑判断,这其中的if表示的是条件,if之后的then就是一种选择或决策。程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
比如:你母亲要给你介绍男朋友,是这么来对话的:
1 2 3 4 5 6 7 8 9 ◇ 女儿:多大年纪了? ◇ 母亲:26。 ◇ 女儿:长的帅不帅? ◇ 母亲:挺帅的。 ◇ 女儿:收入高不? ◇ 母亲:不算很高,中等情况。 ◇ 女儿:是公务员不? ◇ 母亲:是,在税务局上班呢。 ◇ 女儿:那好,我去见见。
◇ 女儿:多大年纪了?◇ 母亲:26。◇ 女儿:长的帅不帅?◇ 母亲:挺帅的。◇ 女儿:收入高不?◇ 母亲:不算很高,中等情况。◇ 女儿:是公务员不?◇ 母亲:是,在税务局上班呢。◇ 女儿:那好,我去见见。
构建决策树
构建决策树包括三个步骤:
final_term_score
Performance
isEmployee
1
A
yes
99
A+
no
如上表: 是训练过的模型, 假如来了60分的期末成绩, 那么毕业之后的就业情况就为0(预测结果很差, 且偏向0), 由于数值差异较大, 所以期末成绩对结果的影响很大, 而没有完全考虑到学生的平时成绩, 造成了测试模型较差的结果, 所以在训练模型的时候需要将第一列给裁剪掉.
过拟合:训练集表现较好,但是测试集表现不好可以通过剪枝(减少特征列)
欠拟合:训练集表现不好,测试集表现不好,通过增加特征列解决
熵(entropy) 1948年,香农提出了 “信息熵(entropy)”的概念,熵在信息论中代表随机变量不确定度的度量。
熵越大,数据的不确定性越高
熵越小,数据的不确定性越低
ID3算法
计算每个特征的信息增益=经验熵-条件熵:整个数据集的信息熵-当前节点的信息熵
使用信息增益最大的特征将数据集 S 拆分为子集
使用该特征(信息增益最大的特征)作为决策树的一个节点
使用剩余特征对子集重复上述(1,2,3)过程
C4.5 是计算信息增益率 :信息增益/当前特征取值的信息熵
解决ID3决策树缺点
当前特征列的取值越多时,信息增益越大
ID3会偏向于选择特征列取值比较多的特征列
Cart算法
Cart模型是一种决策树模型,它即可以用于分类,也可以用于回归,其学习算法分为下面两步:
(1)决策树生成:用训练数据生成决策树,生成树尽可能大。
(2)决策树剪枝:基于损失函数最小化的剪枝,用验证数据对生成的数据进行剪枝。
Cart算法通过计算基尼指数(GINI)来选择特征:基尼指数=1-∑Pi²
信息增益(ID3)、信息增益率(C4.5)值越大,则说明优先选择该特征。
基尼指数值越小(cart),则说明优先选择该特征。
总结
分类算法:决策树-以特征列为节点,特征列的值为边构建的树,使用if….then….else…的思想进行分类的方法
构建决策树
进行特征的选择
不同的算法根据不同方式选择特征作为根节点 (根节点->子节点)
当训练数据集表现较好,但是测试数据集表现不好,发生过拟合现象,可以通过剪枝(减少特征列,可以通过控制树的最大深度实现)
决策树的算法
ID3:通过计算每个节点的信息增益(整个数据的信息熵-当前节点的信息熵),信息增益越大说明不确定性越小,所以我们选择本次信息增益最大的节点作为根节点
C4.5:通过计算每个节点的信息增益率(信息增益/当前节点的信息熵),为了解决ID3算法缺陷(偏向于选择特征值比较多的特征列),信息增益率越大不确定性越小
CART:通过计算每个节点的基尼指数(1-∑Pi²),基尼指数越大不确定性越大,选择基尼指数小的作为当前节点
模型评估:用预测值正确的数量/已知的标签值的数量=准确率
SparkML决策树实现
from pyspark.ml.classification import DecisionTreeClassifier 创建决策树分类器
randomSplit() 切分数据集
maxdepth 处理过拟合
from pyspark.ml.evaluation import MulticlassClassificationEvaluator 创建多分类模型评估对象
鸢尾花案例
iris以鸢尾花的特征作为数据来源,常用在分类操作中。该数据集由3种不同类型的鸢尾花的50个样本数据构成。其中的一个种类与另外两个种类是线性可分离的,后两个种类是非线性可分离的。
该数据集包含了5个属性:
● Sepal.Length(花萼长度),单位是cm;
● Sepal.Width(花萼宽度),单位是cm;
● Petal.Length(花瓣长度),单位是cm;
● Petal.Width(花瓣宽度),单位是cm;
Class|Species种类:Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),以及Iris Virginica(维吉尼亚鸢尾)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 划分训练集 / 测试集 \# 监督学习模型, 数据中带有目标, 分类模型训练好了之后, 需要进行模型评估, 此时需要计算准确率, 利用模型输出的结果和目标值进行比较 \# 要求留一部分有标签的数据, 用于模型评估. \# 所有的训练数据 一部分用于模型训练, 一部分用于模型评估 \# 对于 训练集 / 测试集 的要求 \# 训练集和测试集数据要互斥 测试集数据 不要出现在训练集中 \# 当数据量有限的前提下 训练集数据多于测试集数据 0.7:0.3 0.75:0.25 0.8:0.2 \# 在真实业务场景下 测试集尽量就用一次 (不用使用一份测试数据反复测试)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 from pyspark.ml import Pipelinefrom pyspark.ml.classification import DecisionTreeClassifierfrom pyspark.ml.evaluation import MulticlassClassificationEvaluatorfrom pyspark.ml.feature import StringIndexer, VectorAssemblerfrom pyspark.sql import SparkSessionif __name__ == '__main__' : spark = SparkSession\ .builder\ .appName('决策树算法实现' )\ .master('local[*]' )\ .getOrCreate() iris_df = spark\ .read\ .format ('csv' )\ .option('header' , True )\ .option('inferSchema' , True )\ .option('sep' , ',' ).load('/root/iris.csv' ) indexer = StringIndexer(inputCol='class' , outputCol='label' ) indexer_df = indexer.fit(iris_df).transform(iris_df) assembler = VectorAssembler(inputCols=['sepal_length' , 'sepal_width' , 'petal_length' , 'petal_width' ], outputCol='features' ) vector_df = assembler.transform(indexer_df) (train_df, test_df) = vector_df.randomSplit([0.8 , 0.2 ], seed=5 ) classifier = DecisionTreeClassifier()\ .setFeaturesCol('features' )\ .setLabelCol('label' )\ .setPredictionCol('prediction' )\ .setMaxDepth(4 )\ .setImpurity('gini' ) model = classifier.fit(train_df) train_result_df = model.transform(train_df) test_result_df = model.transform(test_df) print ("训练集的准确率:" , (train_result_df.filter ("label == prediction" ).count() / train_result_df.count())) print ("测试集的准确率:" , (test_result_df.filter ("label == prediction" ).count() / test_result_df.count())) evaluator = MulticlassClassificationEvaluator(predictionCol='prediction' , labelCol='label' ) print ("训练集的准确率" , evaluator.evaluate(train_result_df)) print ("测试集的准确率" , evaluator.evaluate(test_result_df)) """ 结果: 训练集的准确率: 0.9745762711864406 测试集的准确率: 0.96875 训练集的准确率 0.9745762711864407 测试集的准确率 0.96875 """
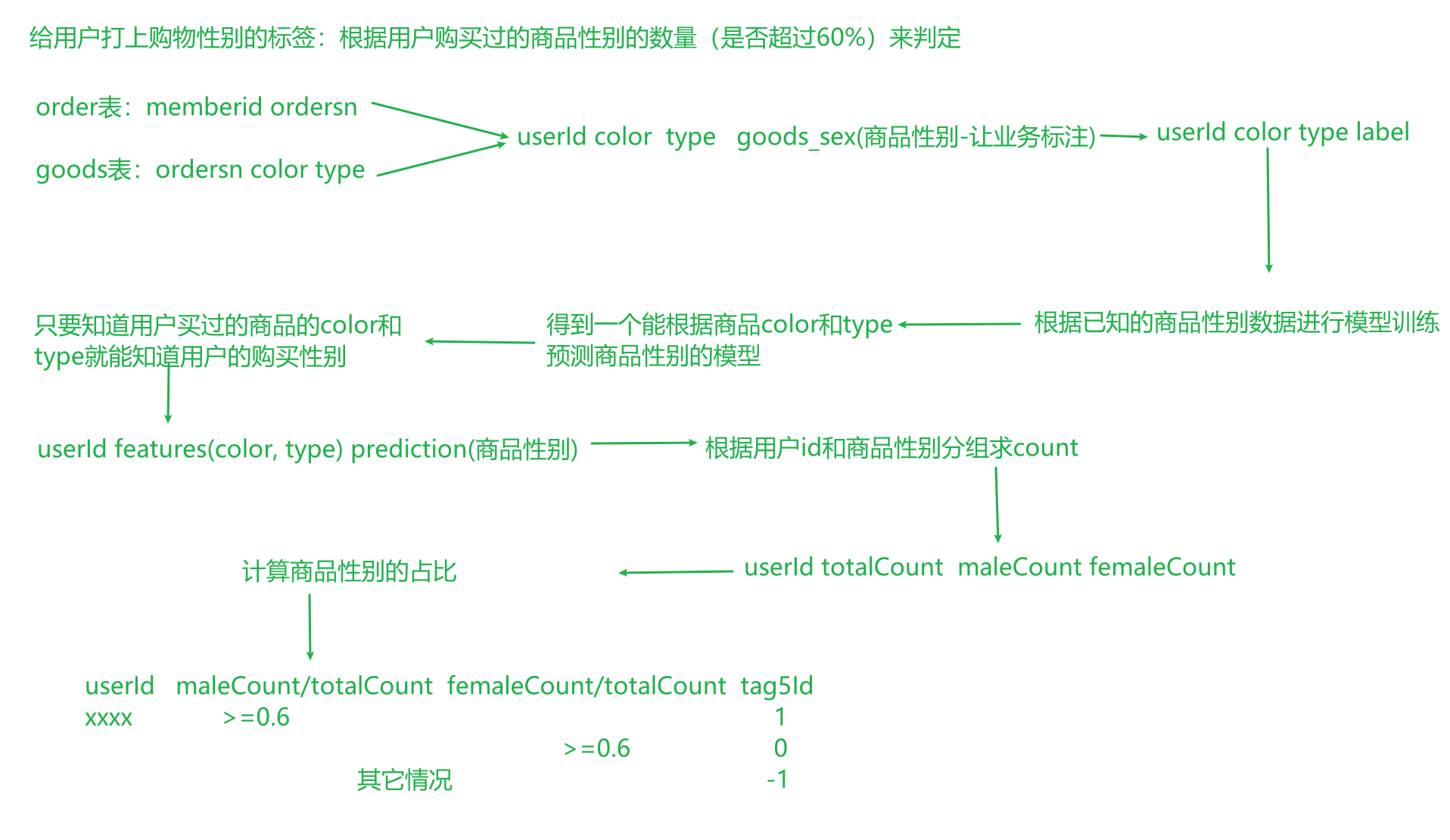
SparkMachineLearning计算用户购物性别 计算步骤
1、主函数编写
2、获取GoodsDF商品表DF
3、获取ordersDF订单表数据
4、对商品表的颜色、商品类型转化为数值类型
5、数据标注
6、GoodsDF和OrderDF数据合并
7、特征工程
8、构建决策树模型
9、模型预测
10、模型评价
11、模型返回结果并保存
12、标签预测
13、自定义UDF完成tags转换
全流程
购物性别标签计算 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 from pyspark.ml import Pipelinefrom pyspark.ml.classification import DecisionTreeClassifierfrom pyspark.ml.evaluation import MulticlassClassificationEvaluatorfrom pyspark.ml.feature import StringIndexer, VectorAssemblerfrom pyspark.sql import DataFramefrom pyspark.sql.types import StringTypefrom UserProfile.offline.base.TagComputeBase import TagComputeBaseimport pyspark.sql.functions as Fclass ShoppingGenderDecisionTree (TagComputeBase ): def tagCompute (self, es_df: DataFrame, tag5_df: DataFrame ): spark = self.getSparkSession() order_df = spark.read.format ('es' ) \ .option('es.nodes' , 'up01:9200' ) \ .option('es.resource' , 'tfec_tbl_orders' ) \ .option('es.read.field.include' , 'memberid, ordersn' ) \ .load() order_indexer = StringIndexer(inputCol='ogcolor' , outputCol='color' ) type_indexer = StringIndexer(inputCol='producttype' , outputCol='type' ) order_indexer_df = order_indexer.fit(es_df).transform(es_df) indexer_df = type_indexer.fit(order_indexer_df).transform(order_indexer_df) indexer_df.show() labelColumn = F \ .when((F.col("ogcolor" ) == ("樱花粉" )) | (F.col("ogcolor" ) == ("白色" )) | (F.col("ogcolor" ) == ("香槟色" )) | (F.col("ogcolor" ) == ("香槟金" )) | (F.col("producttype" ) == ("料理机" )) | (F.col("producttype" ) == ("挂烫机" )) | (F.col("producttype" ) == ("吸尘器/除[螨仪" )), 1 ) \ .otherwise(0 ) \ .alias('label' ) goods_order_df = indexer_df.join(order_df, on=indexer_df.cordersn == order_df.ordersn) \ .select(indexer_df['color' ], indexer_df['type' ], order_df['memberid' ].alias('userId' ), labelColumn) assembler = VectorAssembler(inputCols=['color' , 'type' ], outputCol='features' ) vector_df = assembler.transform(goods_order_df) (train_df, test_df) = vector_df.randomSplit([0.7 , 0.3 ], seed=5 ) classfier = DecisionTreeClassifier(featuresCol='features' , labelCol='label' , predictionCol='prediction' , maxDepth=5 ) model = classfier.fit(train_df) train_result_df = model.transform(train_df) test_result_df = model.transform(test_df) evalutor = MulticlassClassificationEvaluator(predictionCol='prediction' , labelCol='label' ) print ("训练数据集的准确率" , evalutor.evaluate(train_result_df)) print ("测试数据集的准确率" , evalutor.evaluate(train_result_df)) count_df = test_result_df.union(train_result_df).groupby('userId' ).agg( F.count(F.col('prediction' )).alias('total' ), F.sum (F.when(F.col('prediction' ) == 0 , 1 ).otherwise(0 )).alias('male' ), F.sum (F.when(F.col('prediction' ) == 1 , 1 ).otherwise(0 )).alias('female' ) ) count_df.show() tag5_dict = tag5_df.rdd.map (lambda row: (row.rule, row.id )).collectAsMap() print (tag5_dict) @F.udf def computeTagId (total, male, female ): if male / total >= 0.6 : return tag5_dict['0' ] if female / total >= 0.6 : return tag5_dict['1' ] else : return tag5_dict['-1' ] return count_df.select(count_df['userId' ].cast(StringType()).alias('userId' ), computeTagId('total' , 'male' , 'female' ).cast(StringType()).alias('tagsId' )) if __name__ == '__main__' : dic = {0 : 1 } print (dic) ShoppingGenderDecisionTree('购物性别标签计算' , '56' ).execute()
Pipeline介绍与使用
从Spark1.2版本之后引入了ML Pipeline,经过多个版本的发展,SparkMl克服了Mllib在处理复杂机器学习问题的一些不足,如工作比较复杂,流程不够清晰等,向用户提供基于DataFrame之上的更高层次的API库,以方便的构建复杂的机器学习工作流式应用,使得整个机器学习构建过程更加简单、高效和规范。
ML提倡使用Pipeline流水线,以便将多种算法更容易地组合成单个流水线或工作流程。一个Pipeline在结构上会包含一个或多个Stage,每一个 Stage都会完成一个任务,如数据处理、数据转化、模型训练、参数设置或数据预测等,其中两个主要的Stage为Transformer和Estimator。Transformer 主要是用来操作一个DataFrame数据并生成另外一个DataFrame数据,比如决策树模型、一个特征提取工具,都可以抽象为一个Transformer。Estimator 则主要是用来做模型拟合,用来生成一个Transformer。这些Stage有序组成一个Pipeline。
1 2 3 4 pipeline = Pipeline().setStages([indexer, assembler, classifier]) model = pipeline.fit(iris_df) result_df = model.transform(iris_df) result_df.show()
减少代码量
流程更清晰
pipeline中所有stage的入参都是相同
模型的保存与加载 模型训练好之后, 评估没有问题就可以把模型保存起来
1 model.save('hdfs:///model/usegmodel' )
模型保存时路径下要求没有文件, 如果有文件会报错
再次使用这个模型用来分类的时候, 直接加载模型, 就可以进行transform获得分类结果
1 2 3 model = PipelineModel.load('hdfs:///model/usegmodel' ) result_df2 = model.transform(source_df) result_df2.show()
如果能使用Pipeline 尽量使用Pipeline, 保存一个Pipelinemodel , 加载模型后 ,对后续数据进行分类会很简单


 微信
微信 支付宝
支付宝