
【用户画像(五)】挖掘类客户价值标签(RFM模型)
RFM模型
RFM模型介绍
RFM模型是一种用于客户价值分析的模型,通过对客户的消费行为进行分析,将客户分为不同的类别,以便企业更好地了解客户、制定更有效的营销策略和提高客户满意度。RFM模型的三个指标分别为最近一次购买时间(Recency)、购买频率(Frequency)和消费金额(Monetary),因此也被称为RFM分析。
最近一次购买时间(Recency)指客户最近一次购买产品或服务的时间,购买时间越近,说明客户越活跃,对企业的贡献也越大。
购买频率(Frequency)指客户在一段时间内购买产品或服务的次数,购买频率越高,说明客户对企业的忠诚度和购买意愿越强。
消费金额(Monetary)指客户在一段时间内购买产品或服务的金额,消费金额越高,说明客户的购买能力和对企业的贡献越大。

RFM计算方法
RFM模型的计算方法是将客户的消费数据按照时间顺序进行排序,然后将客户分为不同的类别,例如将客户分为高、中、低三个层次,或将客户分为ABC三个等级。不同的企业可以根据自己的实际情况来确定分级标准。
二等分
- 将RFM三个指标分别可以取高和低两个值,共有8个组合(111 011 101 001 110 100 010 000)
- 高于7天R-高,低于7于R-低
- 高于10单F-高,低于10单F-低
- 高于1000元M-高,低于1000元M-低
三等分
- 将RFM三个指标进行三等分-高中低-27组合
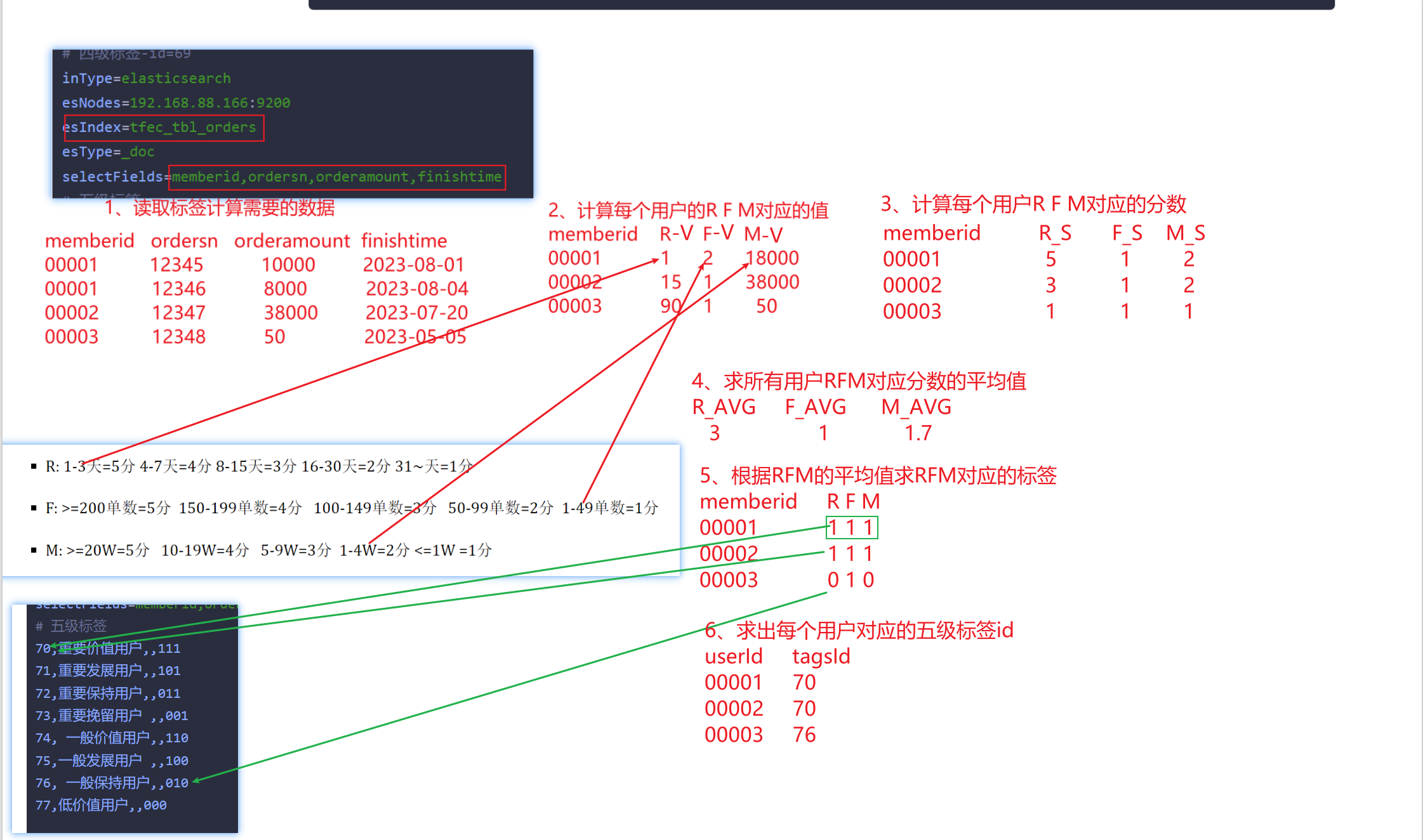
五等分※
- 对RFM进行打分:
- R: 1-3天=5分 4-7天=4分 8-15天=3分 16-30天=2分 31~天=1分
- F: >=200单数=5分 150-199单数=4分 100-149单数=3分 50-99单数=2分 1-49单数=1分
- M: >=20W=5分 10-19W=4分 5-9W=3分 1-4W=2分 <=1W =1分
- 对RFM进行指标计算:
- R: R的分值大于X-取1 R的分值小于X-取0 X=所有R值的平均值
- F: F的分值大于Y-取1 F的分值小于Y-取0 Y=所有F值的平均值
- M: M的分值大于Z-取1 M的分值小于Z-取0 Z=所有M值的平均值
标签元数据
四级标签-id=69
inType=elasticsearch
esNodes=192.168.88.166:9200
esIndex=tfec_tbl_orders
esType=_doc
selectFields=memberid,ordersn,orderamount,finishtime
1 | # 五级标签 |
标签计算流程
1 | # 1、计算 R/F/M的值 |
标签计算代码
1 | from pyspark.sql import DataFrame, Window |
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 微信
微信 支付宝
支付宝