1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
| """
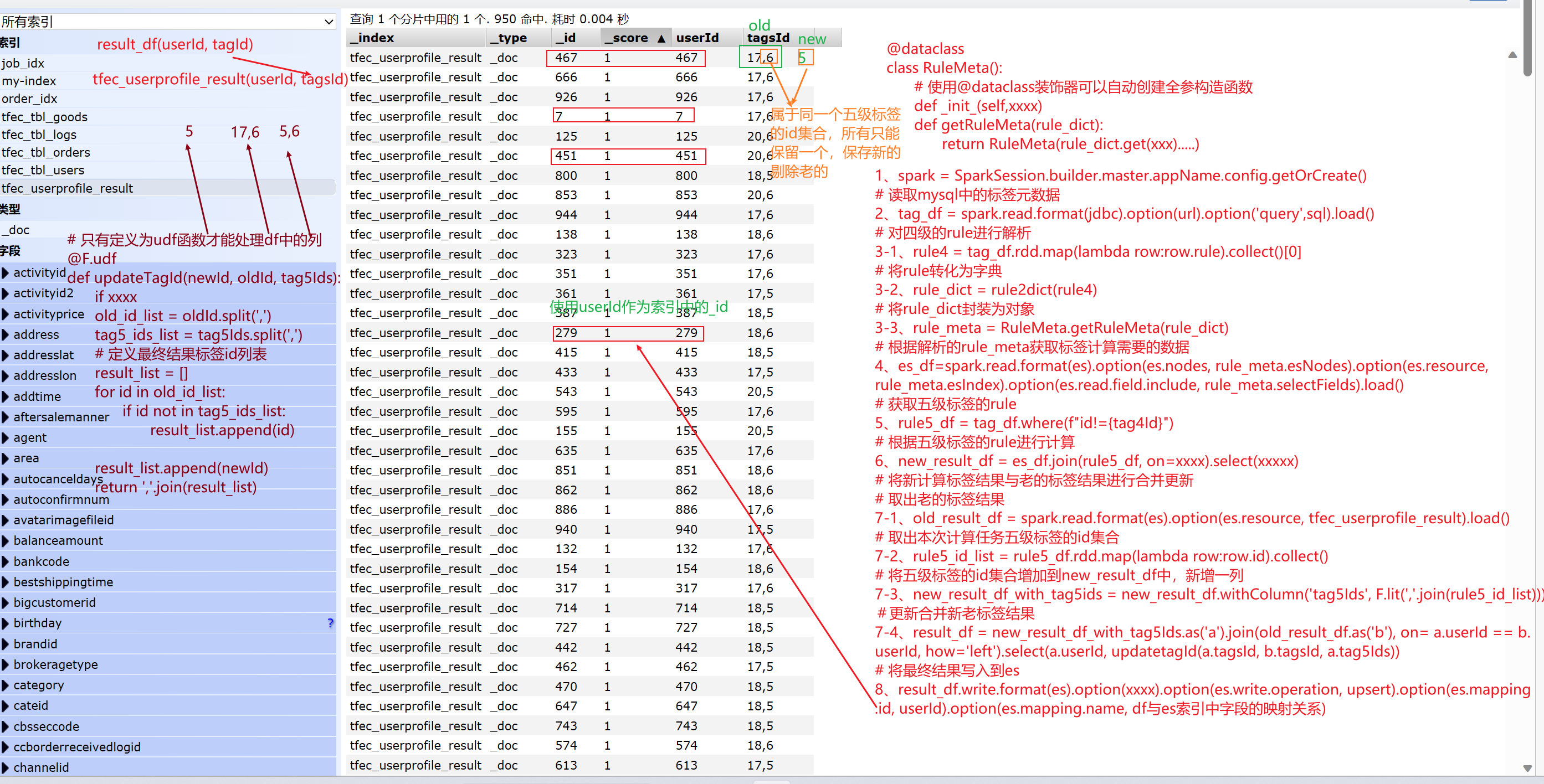
1.准备Spark开发环境
2.读取MySQL数据
3.读取和性别标签相关的4级标签rule并解析
4.根据4级标签加载ES数据
5.读取和性别标签相关的5级标签(根据4级标签的id作为pid查询)
6.根据ES数据和5级标签数据进行匹配,得出userId,tagsId
7.查询ES中的oldDF
8.合并newDF和oldDF
9.将最终结果写到ES
"""
from pyspark.sql import SparkSession
import os
from pyspark.sql.types import StringType
from UserProfile.offline.pojo.RuleMeta import Rule4Meta
import pyspark.sql.functions as F
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_HOME'] = '/root/anaconda3/envs/pyspark_env/bin/python'
@F.udf
def updateTagsId(old_tags:str, new_tag:str, tag5_ids:str):
if new_tag == None:
return old_tags
if old_tags == None:
return new_tag
old_tags_list = old_tags.split(",")
tag5_id_list = tag5_ids.split(',')
new_list = []
for old in old_tags_list:
if old not in tag5_id_list:
new_list.append(old)
new_list.append(new_tag)
return ','.join(new_list)
def strParse(rule_str:str):
all_element_list = rule_str.split("##")
rule_four_dict = {}
for element in all_element_list:
rule_four_dict[element.split("=")[0]] = element.split("=")[1]
return rule_four_dict
if __name__ == '__main__':
spark = SparkSession\
.builder\
.master("local[*]")\
.appName('获取MySQL的数据,读取ES中数据,并将分析结果写入到ES')\
.config("spark.sql.shuffle.partitions", 10)\
.getOrCreate()
url = "jdbc:mysql://192.168.88.166:3306/tfec_tags?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false&user=root&password=123456"
tableName = "tbl_basic_tag"
tag4Id = 4
sql = f"select id,rule from {tableName} where id = {tag4Id} or pid = {tag4Id}"
tfec_userprofile_result = "tfec_userprofile_result"
tag_four_df = spark.read\
.format('jdbc')\
.option('url', url)\
.option('query', sql)\
.load()
tag_four_str = tag_four_df.rdd.map(lambda row: row.rule).collect()[0]
tag_four_dict = strParse(tag_four_str)
rule_four_meta = Rule4Meta.dict_to_obj(tag_four_dict)
print(rule_four_meta.esIndex, rule_four_meta.esNodes, rule_four_meta.selectFields)
es_df = spark.read.format('es')\
.option('es.nodes', rule_four_meta.esNodes)\
.option('es.resource', rule_four_meta.esIndex)\
.option('es.read.field.include', rule_four_meta.selectFields)\
.load()
tag_five_df = tag_four_df.where(f'id!={tag4Id}')
result_df = es_df\
.join(tag_five_df,
on=tag_five_df.rule ==es_df.gender,
how='left')\
.select(es_df.id.cast(StringType()).alias('userId'),
tag_five_df.id.cast(StringType()).alias('tagsId'))
old_df = spark.read.format('es')\
.option('es.nodes', rule_four_meta.esNodes)\
.option('es.resource', tfec_userprofile_result)\
.load()
tag5Ids = tag_five_df\
.select(F.col('id').cast(StringType()).alias('id'))\
.rdd.map(lambda row: row.id).collect()
print(tag5Ids)
new_result_df = result_df.withColumn('tag5Ids', F.lit(','.join(tag5Ids)))
merge_df = new_result_df\
.join(old_df, on=new_result_df.userId==old_df.userId,how='right')\
.select(old_df.userId.alias('userId'), updateTagsId(old_df.tagsId, new_result_df.tagsId, new_result_df.tag5Ids).alias('tagsId'))
merge_df.show()
merge_df\
.write\
.format('es')\
.option('es.nodes', rule_four_meta.esNodes)\
.option('es.resource', tfec_userprofile_result)\
.option('es.write.operation','upsert')\
.option('es.mapping.id','userId')\
.option('es.mapping.name',"userId:userId,tagsId:tagsId") \
.mode('append')\
.save()
|

 微信
微信 支付宝
支付宝