+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | visit_date | date | | people | int | +---------------+---------+ visit_date 是表的主键 每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people) 每天只有一行记录,日期随着 id 的增加而增加
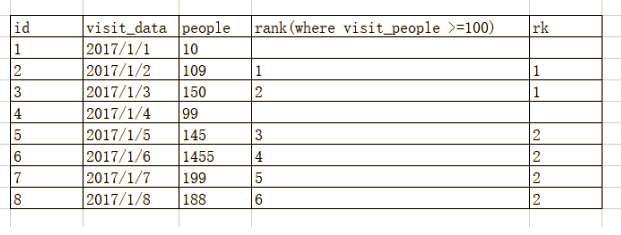
with tmp as ( select *, id -row_number() over(orderby id) as rk from Stadium where people >=100 ) select id, visit_date, people from tmp where rk in ( select rk from tmp groupby rk havingcount(id) >=3 )
+----------------+---------+ | Column Name | Type | +----------------+---------+ | requester_id | int | | accepter_id | int | | accept_date | date | +----------------+---------+ (requester_id, accepter_id) 是这张表的主键。 这张表包含发送好友请求的人的 ID ,接收好友请求的人的 ID ,以及好友请求通过的日期。
with tmp as ( (select requester_id as id, count(*) as cnt from RequestAccepted groupby requester_id ) unionall ( select accepter_id as id, count(*) as cnt from RequestAccepted groupby accepter_id ) ) select id, sum(cnt) as num from tmp groupby id orderby num desc limit 1
select id, ( case when p_id isnullthen'Root' when id notin ( select p_id from tree where p_id isnotnull ) then'Leaf' else'Inner' end )as Type from tree

 微信
微信 支付宝
支付宝