
【Spark笔耕不辍(三)】Kafka生产者消费者API及核心原理
Retrospect
Kafka常用命令
创建主题:指定分区数和副本数
- topic bigdata01 主题的名字
- partitions 3 分区的个数
- replication-factor 2 副本个数
- bootstrap-server kafka内部服务器通信地址,端口默认是9092
创建主题:不指定分区数和副本数,默认是1个分区,1个副本
查看所有主题
查看某一个主题的详情(关键字describe)
1 | # 创建主题:指定分区数和副本数 |
查看Topic信息
1 | kafka-topics.sh --describe --topic bigdata01 --bootstrap-server node1:9092,node2:9092,node3:9092 |
结果
1
2
3
4
5
6Topic名称 分区个数 副本个数
Topic: bigdata01 PartitionCount: 3 ReplicationFactor: 2
分区:Topic名称 + 分区编号
Topic: bigdata01 Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: bigdata01 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: bigdata01 Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3Topic:Topic名称
Partition:分区的编号,从0开始
Replicas:当前这个分区所有的副本所在的Broker的id
Isr:当前这个分区所有可用的副本所在的Broker的id
Leader:当前这个分区的Leader副本所在的Broker的id
Kafka的Python生产者消费者API
环境准备(安装Kafka的API包)
1 | #1、在node1,node2,node3分别安装python和kakfa连接包 |
生产者
1 | from kafka import KafkaProducer |
消费者代码
1 | from kafka import KafkaConsumer |
Kafka的消费原理(API解析)
消费者的auto_offset_reset参数
- auto_offset_reset该参数只对第一次消费有意义,第一次消费指的是消费组id在kafka中没有记录
- auto_offset_reset有两个值, earliest是从头消费, latest是从最新位置开始消费
- 如果你是第二次消费则永远都是从最新位置开始消费,不会再从头消费
1 | 1、auto_offset_reset有两个值: |
Offset数据保存位置
1 | 1、在Kafka中,系统会自动的创建一个Topic,被命名为:__consumer_offsets,该主题用来报错所有分区的offset信息 |
自动提交offset
1 | 0、自动提交offset的方式 |
手动提交Offset
1 | 1、关闭kafka自动提交 |
Kafka的负载均衡(※)
- 负载均衡分为生产者, 消费者两方的负载均衡
- 负载均衡这个概念出现在NameNode管理DataNode中(指的是NameNode为了保证DataNode存储的信息大致相同, 会在分配存储任务的时候, 会优先存储在余量比较大的DataNode上.)
生产者负载均衡
三种策略
- 随机分区(不会出现数据倾斜)
- Hash分区(可能会导致数据倾斜)
- 指定分区
1 | #2.1 随机分区-----写数据时,只指定了value,没有指定key |
消费者负载均衡
两个原则, 三种策略两个原则
- 一个分区的数据只能由这个消费者组中的某一个消费者消费
- 一个消费者可以消费多个分区的数据
三种分配策略
- 范围分配
- 原则: 分区按照范围划分给不同的消费者,一般是按照范围平均划分,如果不够平均,优先分配给编号小的消费者
- 缺点:
- (编号小的消费者处理的数据更多)如果topic过多,对于编号小的消费者,可以能需要承担更多的数据量
- (某个消费者挂掉,需要重新洗牌)如果某一个消费者挂掉,则所有的消费者和分区全部断开,推倒重来,重新进行按照范围划分
- 轮询分配
- 原则: 该分配策略是对所有Topic的分区编号进行排序,然后开始轮询(你一个,我一个)
- 优点: 该方案基本上可以显示每个消费者均衡消费
- 缺点: 如果某一个挂掉,则推导重新轮询,缺点就是由于是重新推导,效率相对低一点
- 粘性策略
- 原理: 该策略底层和轮询类似
- 优点: 有点和轮询不同,如果某一个消费者挂掉,则原来正在消费的消费者继续消费,多出来的分区继续轮询,效率相对高一点
两个原理介绍:
1 | 1、有多个分区,有多个消费者组,有多个消费者,这些分区的数据如何合理的给消费者消费 |
Kafka读写流程及数据清理
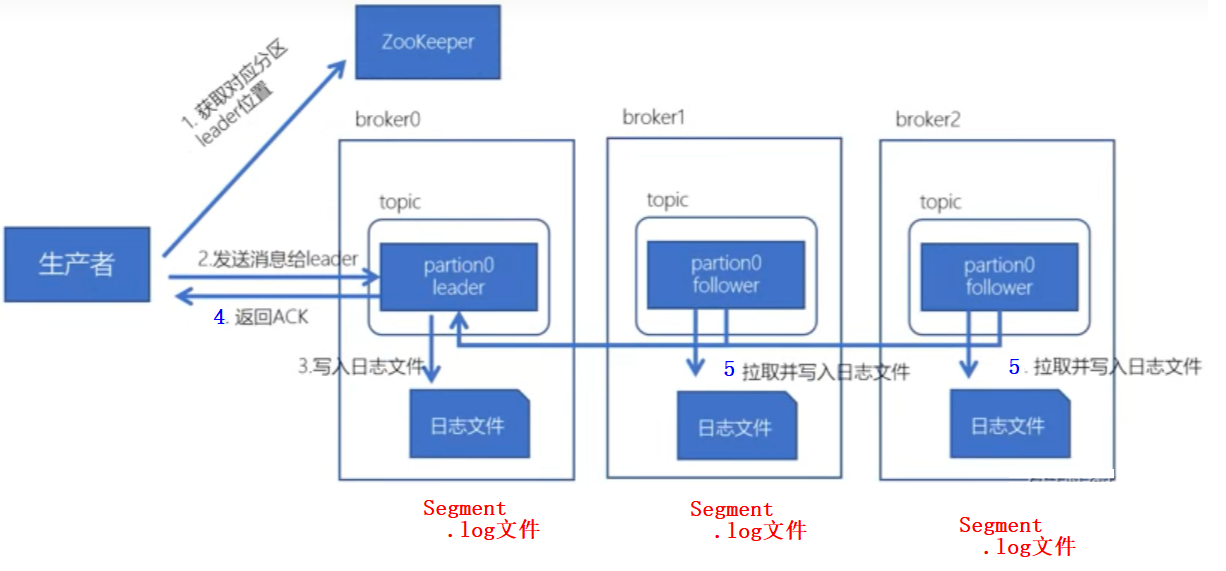
Kafka写入流程
1 | 1、生成者生产消息时,先去Zookeeper获取对应分区Leader所在的主机位置 |
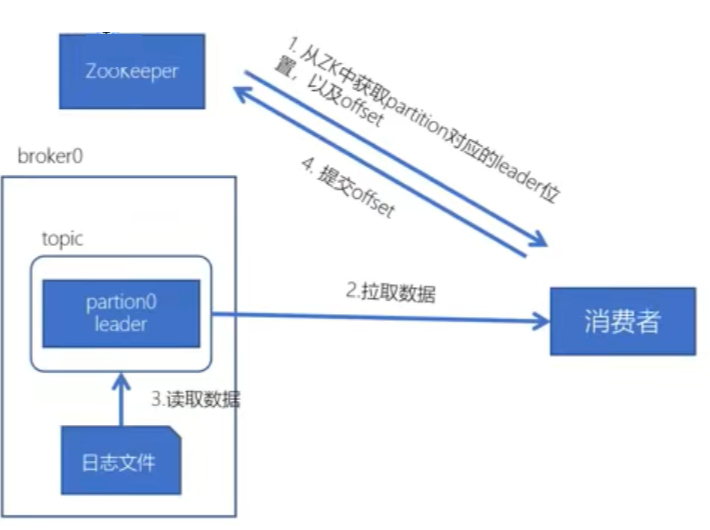
Kafka读取流程
1 | 1、消费者从Zookeeper获取所在分区Leader主机位置,从__consumer_offsets主题当前分区的offset信息 |
Kafka的清理设置
实施
属性配置
1
2
3
4
5#开启清理
log.cleaner.enable = true
#清理规则
log.cleanup.policy = delete基于存活时间规则:最常用的方式,单位越小,优先级越高
1
2
3
4
5
6
7
8# 清理周期
log.retention.ms=1000 #每隔1000毫秒就删除kafka数据
log.retention.minutes=10 #每隔10分钟就删除kafka数据
log.retention.hours=168 #每隔168小时就删除kafka数据
# 检查周期,要搭配清理周期来修改
log.retention.check.interval.ms=300000 #每隔5分钟就检测删除时候时间是否到来
# Segment文件最后修改时间如果满足条件将被删除基于文件大小规则
1
2#删除文件阈值,如果整个数据文件大小,超过阈值的一个segment大小,将会删除最老的segment,-1表示不使用这种规则
log.retention.bytes = -1
小结:理解Kafka中数据清理的规则
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 微信
微信 支付宝
支付宝