
【Spark笔耕不辍(二)】Kafka
消息队列
什么是消息队列
消息队列MQ(Message Queue)用于实现两个系统之间或者两个模块之间
传递消息数据时,实现数据缓存
消息队列的作用
消息队列可以实现两个模块之间的异步通信,并降低模块之间的耦合性,并可以限流削峰
由于消息队列是连接两个模块的桥梁,至关重要,因此消息队列都是采用分布式架构来保证数据的安全性和可靠性
常见的消息队列:
ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ、Pulsar
发布和订阅
介绍
- 1、发布者又称生成者,多个生成者都可以向消息队列生成数据,为了区分不同的消息,每个消息都有主题
- 2、订阅者又称消费者,每个消费者可以消费或者订阅多个主题的消息
- 3、消费者消费完消息之后,队列中的消息并不会立刻消失
Kafka
什么是Kafka
Kafka是基于分布式的流式处理框架,主要用于实时分析
Kafka是基于发布订阅模式的消息队列,有生产者 消费者 主题 队列等
Kafka的核心组件
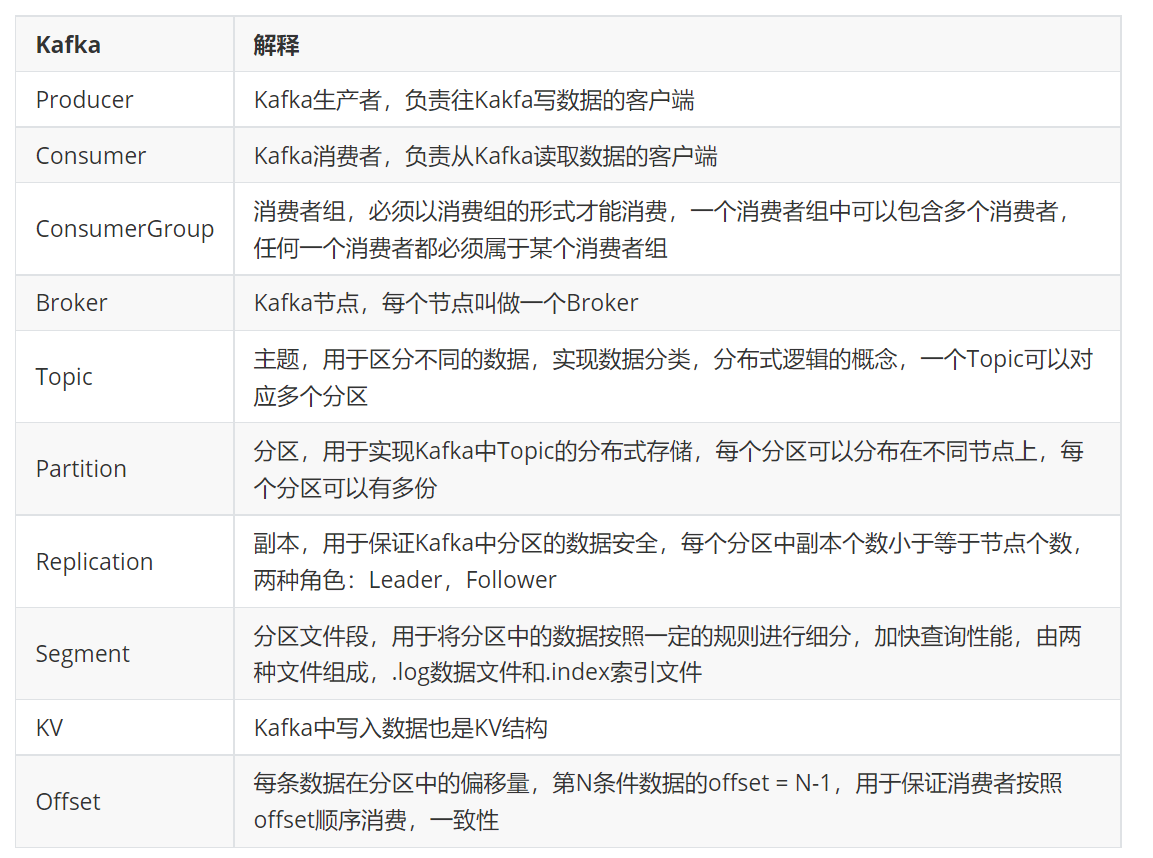
Broker
1
2
31、搭建Kafka集群的每台主机被称为Broker
2、Kafka是主从架构,分为主Broker和从Broker,主Broker是由ZK选举得到,被称为Controller
3、如果主Broker挂掉,则重新选举,主Broker负责管理和对外读写数据,从Broker只负责对外读写数据Producer:生产者
1
负责向Kafka生成消息
Consumer:消费者
1
负责从Kafka消费消息
消费者组
1
2
3
4
51、任何一个消费者必须属于某一个消费者组
2、同一个组的消费者只能消费同一个Topic中不同分区的数据,也就是同一个组的消费者不能消费相同的数据,不能出现抢食现象(每人各自一盘菜)
3、同一个消费者组 ,一个消费者可以消费多个分区的数据,尽量让分区数等于消费者数,这样效率最高
3、消费者组中多个消费者可以实现并发消费,也就是同时消费,提高数据消费的速度和效率
4、整个消费者组中所有消费者消费的数据加在一起是一份完整的数据Toic
1
21、为了对数据进行分类,不同类型的数据被称为不同的Topic(主题)
2、Kafka中的Topic类似HDFS中的一个文件Partition
1
2
3
4
5
6
71、每个Topic可以被分成多个分区
2、Kafka中的分区类似HDFS中的一个Block
3、每个分区都有多个副本
4、Kafka的分区副本有主副本(Leader副本)和从副本(Follower副本),主副本负责对外读写数据,从副本负责和主副本保持数据同步
#主副本和从副本由Controller的Broker主机来决定
#Controller的Broker主机由ZK来决定
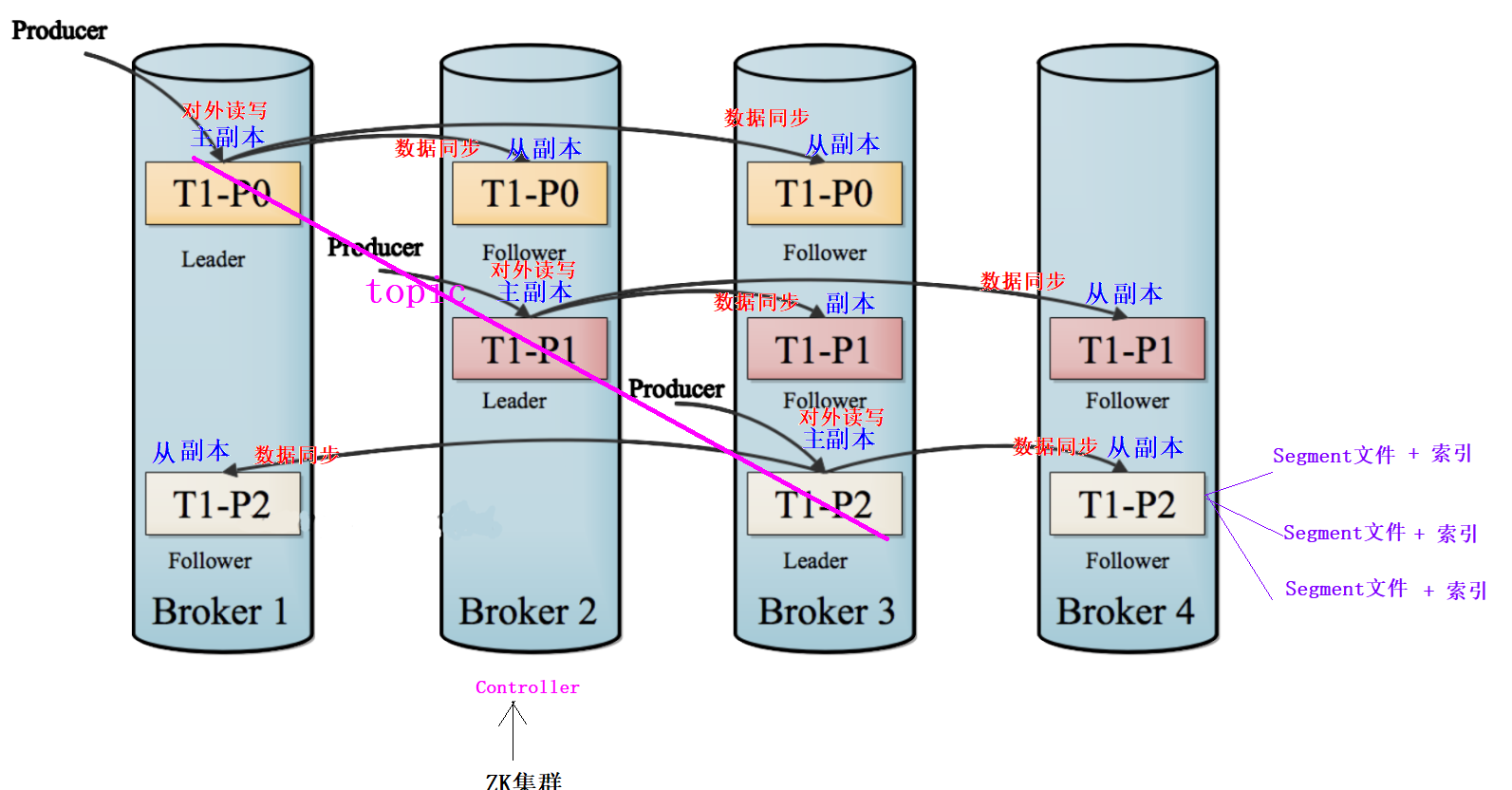
Segment
1
2
3
4
5
61、为了更新的管理数据,Kafka每个分区的数据被切分成一个个Segment文件,一般一个Segment文件最大是一个G
2、为了更方便查询每一个Segment文件内容,Kafka会生成对应的索引文件
3、每个Segment对应两种【三个】文件
xxxxxxxxx.log: 存储数据
xxxxxxxxx.index 根据数据查找索引
xxxxxxxx.timeindex:根据时间查找索引Offset
1
2
3
41、Offset是每条数据在自己分区中的偏移量,也可以理解为每条数据的编号,从0开始
2、Offset是每个分区独立关系,比如每个分区都有offset为0的数据,分区之间的offset彼此独立
3、比如一个分区的数据上次被消费到offset=2的位置,下一次从offset+1=3的位置开始消费
4、如果没有offset,就有可能出现重复消费或遗漏消费的情况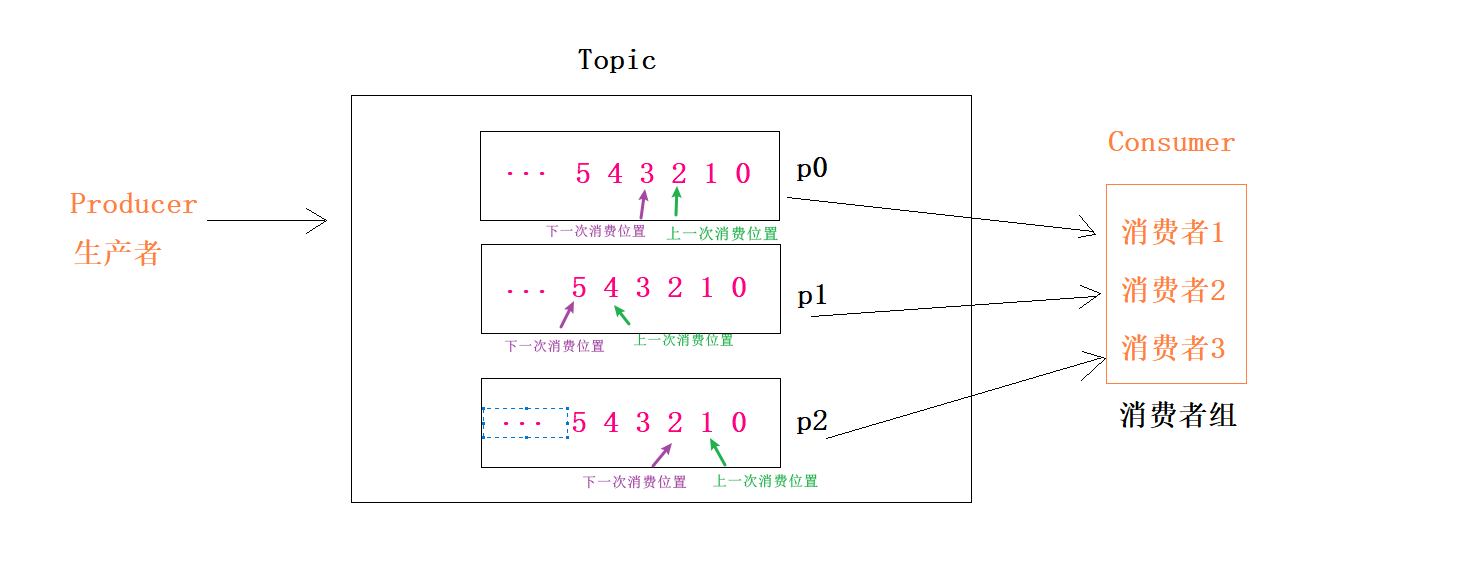
小结
Kafka的环境搭建
搭建过程
下载解压安装
上传到第一台机器
1
2cd /export/software/
rz解压
1
2
3
4
5解压安装
tar -zxvf kafka_2.12-2.4.1.tgz -C /export/server/
cd /export/server/kafka_2.12-2.4.1/
Kafka数据存储的位置
mkdir datas
修改配置
切换到配置文件目录
1
cd /export/server/kafka_2.12-2.4.1/config
修改server.properties:
vim server.properties
1
2
3
4
5
6
7
8
9#21行:唯一的 服务端id
broker.id=1
#60行:指定kafka的日志及数据【segment【.log,.index】】存储的位置
log.dirs=/export/server/kafka_2.12-2.4.1/datas
#123行:指定zookeeper的地址
zookeeper.connect=node1:2181,node2:2181,node3:2181
#在最后添加两个配置,允许删除topic,当前kafkaServer的主机名
delete.topic.enable=true
host.name=node1分发
1
2
3cd /export/server/
scp -r kafka_2.12-2.4.1 node2:$PWD
scp -r kafka_2.12-2.4.1 node3:$PWD第二台:vim /export/server/kafka_2.12-2.4.1/config/server.properties
1
2
3
4#21行:唯一的 服务端id
broker.id=2
#最后
host.name=node2第三台:vim /export/server/kafka_2.12-2.4.1/config/server.properties
1
2
3
4#21行:唯一的 服务端id
broker.id=3
#最后
host.name=node3
每台机器添加环境变量
1
vim /etc/profile
1
2
3KAFKA_HOME
export KAFKA_HOME=/export/server/kafka_2.12-2.4.1
export PATH=:$PATH:$KAFKA_HOME/bin1
source /etc/profile
启动Kafka
- 启动Zookeeper
1 | 在node1,node2,node3分别执行以下命令 |
- 启动Kafka
1 | #在node1,node2,node3分别执行以下命令 |
验证Kafka
1 | 1、创建主题:指定分区数和副本数 |

All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 微信
微信 支付宝
支付宝