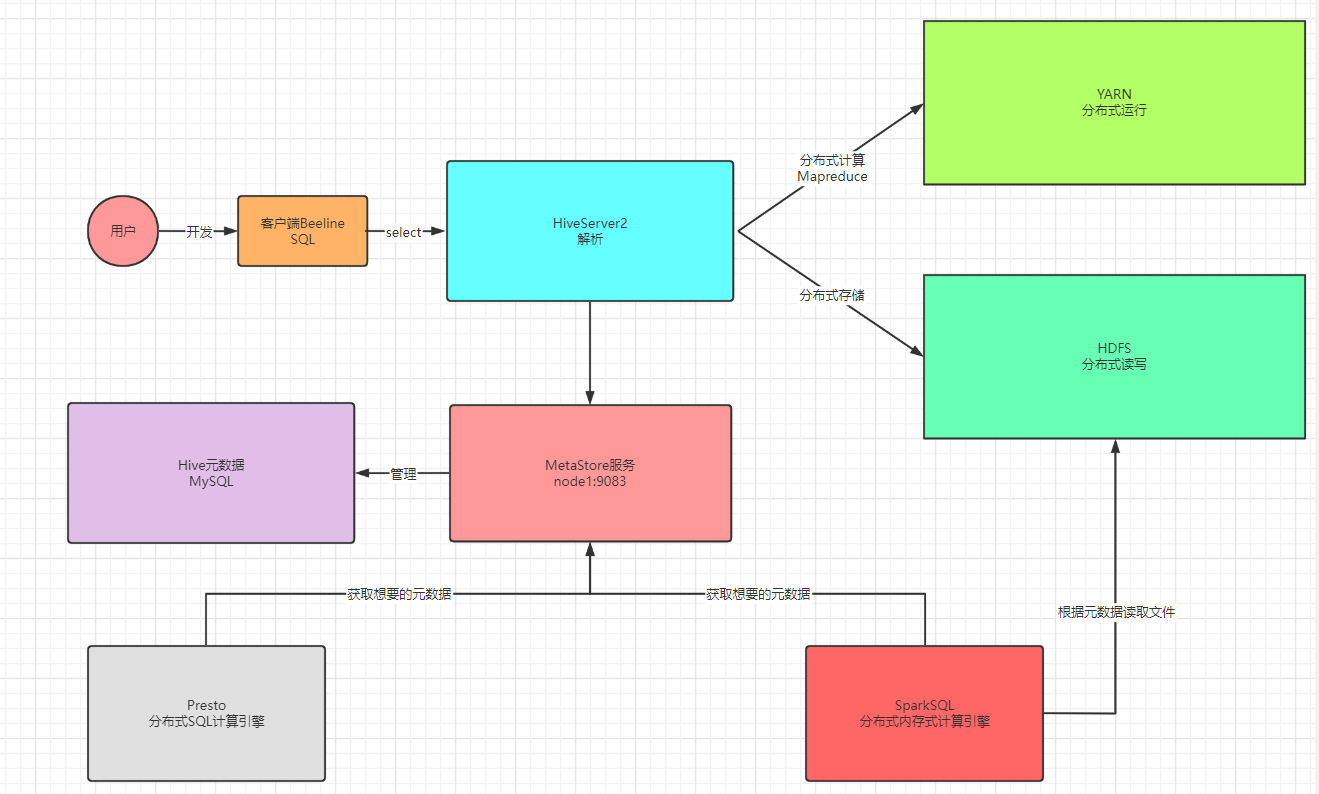
Spark连接Hive
Hive底层默认是MR引擎,计算性能特别差,一般用Hive作为数据仓库,使用SparkSQL对Hive中的数据进行计算
本质上:SparkSQL访问了Metastore服务获取了Hive元数据,基于元数据提供的地址进行计算
命令行集成 Pycharm中集成 Pycharm连接Hive +Spark
测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from pyspark.sql import SparkSessionimport osimport reimport pyspark.sql.functions as Fif __name__ == '__main__' : os.environ['JAVA_HOME' ] = '/export/server/jdk' os.environ['HADOOP_HOME' ] = '/export/server/hadoop' os.environ['PYSPARK_PYTHON' ] = '/export/server/anaconda3/bin/python3' os.environ['PYSPARK_DRIVER_PYTHON' ] = '/export/server/anaconda3/bin/python3' spark = SparkSession \ .builder \ .appName("SparkSQLAppName" ) \ .master("local[2]" ) \ .config("spark.sql.warehouse.dir" , 'hdfs://node1.itcast.cn:8020/user/hive/warehouse' )\ .config("spark.sql.shuffle.partitions" , 2 ) \ .config("hive.metastore.uris" , "thrift://node1.itcast.cn:9083" )\ .enableHiveSupport()\ .getOrCreate() spark.sparkContext.setLogLevel("WARN" ) spark.sql(""" show databases; """ ).show() hiveData = spark.read.table("db_hive.emp" ) rs_df = hiveData\ .select("deptno" , "sal" )\ .groupBy("deptno" )\ .agg(F.round (F.avg("sal" ), 2 ).alias("avg_sal" )) rs_df.write.mode("overwrite" ).format ("hive" ).saveAsTable("db_hive.test_rs" ) spark.stop()
新零售案例 需求
1-统计查询每个省份的总销售额【订单金额要小于1万】
2-统计查询销售额最高的前3个省份中,统计各省份单日销售额超过1000的各省份的店铺个数(去重)
3-统计查询销售额最高的前3个省份中,每个省份的平均订单金额
4-统计查询销售额最高的前3个省份中,每个省份的每种支付类型的占比
需求分析
1-统计查询每个省份的总销售额
指标:总销售额:sum(receivable)
维度:省份:group by storeProvince
2-统计查询销售额最高的前3个省份中 ,单日销售额超过1000的各省份的店铺个数
指标:店铺个数:count(distinct storeID)
维度:省份:group by storeProvince
前提 :不是对所有数据做统计,只对销售额最高的前3个省份的数据做统计条件:每个省份每个店铺每天的成交额 > 1000
3-统计查询销售额最高的前3个省份中 ,每个省份的平均订单金额
指标:平均订单金额:avg(receivable)
维度:省份:group by storeProvince
前提 :不是对所有数据做统计,只对销售额最高的前3个省份的数据做统计
4-统计查询销售额最高的前3个省份中 ,每个省份的每种支付类型的占比
指标:支付类型占比:每种支付类型订单个数 / 总订单个数
维度:省份、支付类型:group by storeProvince, payType
前提 :不是对所有数据做统计,只对销售额最高的前3个省份的数据做统计
数据清洗代码剖析
数据清洗,得到ETL_DataFrame
需求:读取数据变成DataFrame,并对不合法的数据进行清洗【过滤、转换】
订单金额超过10000的订单不参与统计
storeProvince不为空 ‘null’值
只保留需要用到的字段,将字段名称转换成Python规范:a_b_c
并对时间戳进行转换成日期,获取天
对订单金额转换为decimal类型
SQL风格实现(需要注册临时视图)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 input_df.createOrReplaceTempView('original_table' ) spark.sql( """ select storeProvince as store_province, storeID as store_id, payType as pay_type, from_unixtime(dateTs / 1000, "yyyy-MM-dd") as daystr, cast(receivable as decimal(5, 2)) as receivable_money from original_table where receivable < 10000 and storeProvince is not null and storeProvince != 'null' """ ).show()
DSL风格实现1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 """ 知识点: 1, DataFrame可以像RDD直接调用算子filter 2, 调用cast函数实现数据类型的转换, 转为decimal类型, 需要导包from pyspark.sql.types import DecimalType 3, 使用Hive中的函数from_unixtime函数将时间戳转换为指定日期格式 4, 当对一列数据进行处理的时候, 比如运算, 需要将列名加上col()包裹起来 """ etl_df = input_df\ .filter (col('receivable' ) <= 10000 )\ .filter ((col('storeProvince' ) != 'null' ) & (col('storeProvince' ).isNotNull()) & (col('storeProvince' ) != '' ))\ .select( col('storeProvince' ).alias('store_province' ), col('storeID' ).alias('store_id' ), col('receivable' ).cast(DecimalType(10 , 2 )), col('payType' ).alias('pay_type' ), from_unixtime(col('dateTS' ) / 1000 , 'yyyy-MM-dd' ).alias('date_ts' ) ) etl_df.show()
需求1代码剖析 SQL风格实现1 2 3 4 5 6 7 8 spark.sql( """ select store_province, sum(receivable_money) as total_money from etl_tb group by store_province order by total_money """ ).show()
DSL风格实现1 2 3 4 5 6 7 8 9 10 11 """ 知识点: 1, 使用groupBy对数据进行分组, 分组之后肯定是要聚合的, 所以需要使用agg函数, agg可以包裹sum,count等聚合函数 2, 使用orderBy(根据什么进行排序-字段名, ascending=False指定为降序) """ request1_df = etl_df\ .groupBy(col('store_province' ))\ .agg( sum (col('receivable' )).alias('total_money' ) ).orderBy(col('total_money' ), ascending=False ) request1_df.show()
补充点(将DataFrame表格转为Python列表, DataFrame缓存策略) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 """ 知识点: 1, 将DataFrame中的数据转为Python的列表, 需要先将DataFrame转为RDD, 然后变为Row对象, 最后通过map函数使用 对象名.属性名 来获取rdd中的store_province数据 """ list_top3_province = request1_df\ .limit(3 )\ .select(col('store_province' ))\ .rdd\ .map (lambda x: x.store_province)\ .collect() print (list_top3_province) """ 知识点: 1, 使用filter函数对DataFrame中的数据进行过滤 2, 使用字段名.isin(列表) 来对数据筛选 """ top3_df = etl_df\ .filter (col('store_province' ).isin(list_top3_province)) top3_df.show() top3_df.persist(StorageLevel.MEMORY_AND_DISK) top3_df.createOrReplaceTempView('top3_province' ) spark.catalog.cacheTable('top3_province' )
需求2代码剖析 1 需求二 : 统计销售额最高的前三个省份中,每个省份单日销售额高于1000的店铺的个数
SQL风格实现1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 top3_province_df.createOrReplaceTempView("tmp_view_top3_data" ) spark.catalog.cacheTable("tmp_view_top3_data" ) rs2 = spark.sql(""" with tmp as ( select store_province, store_id, daystr, sum(receivable_money) as total_money from tmp_view_top3_data group by store_province, store_id, daystr having total_money > 1000 ) select store_province, count(distinct store_id) as store_cnt from tmp group by store_province """ )
DSL风格实现1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 """ 知识点: 1, 刚开始理解错了, 理解的是单日销售额超过1000的店铺, 写了一上午无果.后来转换思路, 是求全省的销售额超过1000 2, 首先将全省销售额超过1000的省份筛选出来, 转为列表(list2). """ list2 = top3_df\ .groupBy(col('store_province' ))\ .agg(sum (col('receivable' )).alias('total_money' ))\ .where('total_money > 1000' )\ .select(col('store_province' ))\ .distinct()\ .rdd.map (lambda x: x.store_province)\ .collect() print (list2) etl_df.filter (col('store_province' ).isin(list2))\ .groupBy('store_province' )\ .agg( countDistinct('store_id' ).alias('store_cnt' ) ).show()
需求3代码剖析 SQL风格实现1 2 3 4 5 6 7 8 9 rs3 = spark.sql(""" select store_province, round(avg(receivable_money), 2) as avg_money from tmp_view_top3_data group by store_province """ )
DSL风格实现1 2 3 4 5 top3_df\ .groupBy('store_province' )\ .agg( avg('receivable' ).alias('avg_money' ) ).show()
需求4代码剖析 SQL风格实现1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 rs4 = spark.sql(""" with tmp1 as ( select store_province, pay_type, count(1) as cnt from tmp_view_top3_data group by store_province, pay_type ), tmp2 as ( select tmp1.*, sum(cnt) over (partition by store_province) as all_cnt from tmp1 ) select tmp2.store_province, tmp2.pay_type, round((tmp2.cnt / tmp2.all_cnt), 2) as rate from tmp2 """ ) rs4.printSchema() rs4.show()
DSL风格实现1 2 3 4 5 6 7 8 9 10 top3_df\ .groupBy(col('store_province' ), col('pay_type' ))\ .agg( count('*' ).alias('pay_cnt' ) ).withColumn( 'all_cnt' , sum ('pay_cnt' ).over(Window.partitionBy('store-province' )) ).withColumn('rate' , concat(round (round (col('pay_cnt' )/col('all_cnt' ),4 ) * 100 , 2 ), lit('%' )))\ .show()

 微信
微信 支付宝
支付宝