
【SparkSQL】SparkSQL词频统计Demo
SparkSQL的概念
- 1、SparkSQL是Spark发展后期产生的,是为了使用SQL风格来替换之前SparkCore的RDD风格
- 2、SparkSQL既可以做离线,也可以做实时
- 3、SparkSQL的编程有两种风格:SQL风格、DSL分格
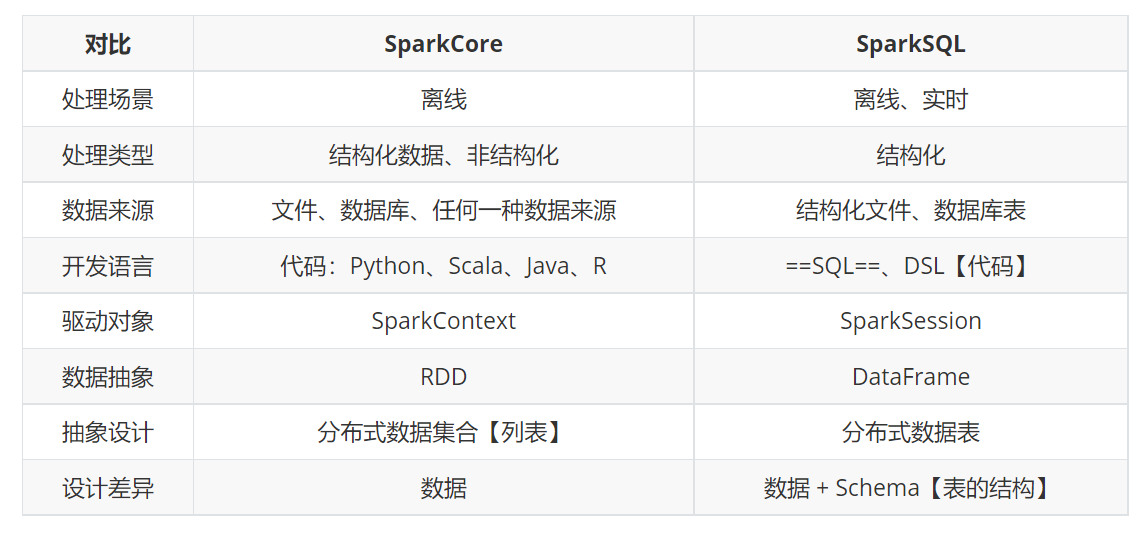
SparkSQL和SparkCore区别
- 1、SparkCore的核心数据类型是RDD,SparkSQL核心数据类型是DataFrame
- 2、SparkCore的核心入口类是SparkContext、SparkSQL的核心入口类是:SparkSession
- 3、SparkSQL是基于SparkCore,SparkSQL代码底层就是rdd
- 4、SparkCore只侧重数据本身,没有表概念,SparkSQL要侧重:数据+表结构
SparkSQL的SQL风格词频统计
SparkSQL的入口类为SparkSession, 导包方式:
from pyspark.sql import SparkSession创建SparkSQL的入口类对象
spark = SparkSession \ .builder \ .appName("wordcount_1") \ .config("spark.sql.shuffle.partitions", 2) \ .getOrCreate()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
- <font size=4 color=red face='华文楷体'>根据DataFrame来进行SQL或者DSL编程</font>
## <font size=5 color='orange' face='华文楷体'>CodeDemo</font>
```python
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import os
import re
import time
os.environ['JAVA_HOME'] = '/export/server/jdk'
os.environ['SPARK_HOME'] = '/export/server/spark' #Spark安装位置
os.environ["PYSPARK_PYTHON"] = "/export/server/anaconda3/bin/python3"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/export/server/anaconda3/bin/python3"
if __name__ == '__main__':
conf = SparkConf().setMaster('local[2]').setAppName('wordcount01')
sc = SparkContext(conf=conf)
# 1、在Python代码中入口类对象:SparkSession
spark = SparkSession \
.builder \
.appName("wordcount_1") \
.config("spark.sql.shuffle.partitions", 2) \
.getOrCreate()
# 2、读取源数据变成DataFrame
df = spark.read.text('hdfs://node1:8020/datas/input/word.txt')
df.show()
# 3、根据DataFrame来进行SQL或者DSL编程
# 3.1)注册一张临时视图(表)
df.createOrReplaceTempView('t1')
# 3.2写Sql
spark.sql(
"""
with t2 as(
select explode(split(value,' ')) as word from t1 where length (value) > 0
)
select word, count(*) cnt from t2 group by word order by cnt
"""
).show()
SparkSQL的DSL风格词频统计
1 | import time |
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 微信
微信 支付宝
支付宝