
【SparkCore】SparkTheory理论
Spark容错机制
两个问题引入Spark容错机制
- 问题1:计算机在存储数据的过程中如何保证数据的安全?
- a. 内存快照:将内存中所有数据拍摄一个快照,存储在文件中,读取快照文件恢复内存中数据
- b. 操作日志:将内存变化操作日志追加记录在一个文件中,下一次读取文件对内存重新操作
- HDFS:edits文件,保证HDFS内存元数据的安全的
- c. 副本机制:将数据构建多份冗余副本
- HDFS:副本机制,保证HDFS数据的安全
- d. 依赖关系:每份数据保留与其他数据之间的一个转换关系
- 问题2:Spark中RDD的数据如何保证数据的安全?
- 每个RDD在构建数据时,会根据自己来源一步步倒推到数据来源,然后再一步步开始构建RDD数据
- 当RDD的数据被触发调用时,就会根据RDD的血缘关系层层构建RDD的数据
- 如果在计算过程中,RDD的数据丢失,就会通过依赖关系重新构建,彻底保证了RDD的数据安全
- 但是: 如果一个RDD被触发多次,这个RDD就会按照依赖关系被构建多次,性能相对较差,怎么解决?
Persist缓存机制
- 问题:RDD依赖血缘机制保证数据安全,那每调用一次RDD都要重新构建一次,调用多次时性能就特别差,怎么办?
- 解决:将RDD进行缓存,如果需要用到多次,将这个RDD存储起来,下次用到直接读取我们存储的RDD,不用再重新构建了
cache算子
- 功能:将RDD缓存在内存中
- 本质:底层调用的还是persist(StorageLevel.MEMORY_ONLY),但是只缓存在内存,如果内存不够,缓存会失败
- 语法:
cache()
使用方法:
- 直接使用, 这里使用词频统计案例, 将rdd的结果缓存到内存中.
CodeDemo
1 | # aggRDD是最终词频统计得到的结果 |
persist算子
- 功能:将RDD【包含这个RDD的依赖关系】进行缓存,可以自己指定缓存的级别【和cache区别】
- 语法:
persist(StorageLevel) - 级别:StorageLevel决定了缓存位置和缓存几份
使用方法:
- 首先导入StorageLevel这个包, 导入方式为: from pyspark import SparkContext,SparkConf, StorageLevel
CodeDemo
1 | # aggRDD是最终词频统计得到的结果 |
unpersist算子
- 功能:将缓存的RDD进行释放
- 语法:
unpersist- unpersist(blocking=True):等释放完再继续下一步
- 场景:明确RDD已经不再使用,将RDD的数据从缓存中释放,避免占用资源
CodeDemo
1 | # 如果这个RDD明确后续代码中不会再被使用,一定要释放缓存 |
Summary
1 | #1、将你要缓存的rdd进行缓存 |
checkpoint检查点机制
checkpoint
引入
- 1、Spark认为之前的Persist缓存机制数据可以会发生丢失,所以又提供了一个checkpoint机制
- 2、checkpoint机制是将缓存数据存放在hdfs,spark认为理论上hdfs上的数据永远不丢失
- 3、checkpoint的缓存在程序结束之后依然存在,下一次运行还可以使用
功能:将RDD的数据【不包含RDD依赖关系】存储在HDFS上
语法
1 | # 设置一个检查点目录 |
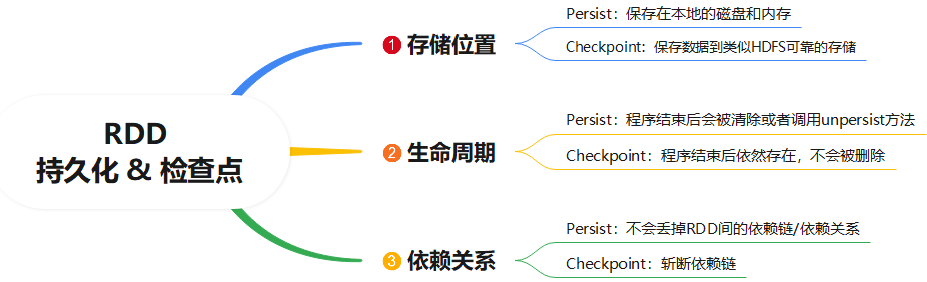
checkPoint检查点机制和Persist缓存机制的区别
Spark共享变量
案例引入Broadcast Variables(广播变量)
有如下的信息, 需要将
用户信息数据【用户id、用户名、年龄、城市id】后面加上城市的名称最初想到的是join, 但是只限于使用SparkCore中的Rdd算子解决, 故不考虑.
思路:
- 读取文件user.tsv文件得到RDD
- 使用map函数(lambda x: 定义函数实现x末尾拼接上城市的名称)
- 函数的定义是先将数据切割, 然后通过获取最后的一个城市id, 再使用字典[‘键’]获取到字典对应的值, 最后加上\t拼接得到最终的结果
1 | # users.tsv 用户信息数据【用户id、用户名、年龄、城市id】 |
不使用广播变量
产生的问题是:
- 1、RDD的数据是存在Executor内存
- 2、普通变量是存在Driver所在内存
- 3、如果RDD数据需要和普通变量进行join联合,则每次执行任务都需要从Driver主机将普通变量数据拷贝到RDD每个分区,如果普通变量数据量过大,则效率太低
CodeDemo
1 | # 1、将users.tsv转为rdd |
使用广播变量
- 使用广播变量的好处
- 1、将一个普通变量变为广播变量之后,该变量可以自动广播到每一个Executor内存中
- 2、当你想让rdd和变量进行join时,可以直接从本地内存直接读取广播变量,极大提高开发效率
- 使用广播变量的方法
- step1:将一个变量定义成为一个广播变量
broadcastVar = sc.broadcast(普通变量的名字)- step2:当需要用到这个变量时,就从广播变量中获取它的值
broadcastVar.value- step3:释放广播变量
broadcastVar.unpersist()
CodeDemo
1 | # 1、将users.tsv转为rdd |
Accumulator累加器
累加器的引入
引入: 不使用rdd的count算子,计算rdd中元素的个数
- 如果定义count变量, 然后通过foreach遍历RDD中的元素, 每遇到一个元素就加1
- 但是由于count是本地变量, 是放在Driver中的, RDD分区会从Driver中拷贝一份初始值0, 然后各自在自己的分区累加, 但是结果并没有返回, 而且总数据个数为5, 每个RDD中累加的数据是分散的.如2, 3并没有汇总起来
解决方法 - 使用累加器:
- 1、定义累加器,并指定初始值
accum_count = sc.accumulator(0)- 2、在需要的地方进行累加
accum_count.add(1)- 3、获取累加器结果值
accum_count.value
不使用累加器
结果会出现异常.
CodeDemo
1 | #1、定义列表 |
使用累加器
RDD中的count每次加1都会回馈给Driver中的本地变量
CodeDemo
1 | #1、定义列表 |
Spark内核调度


Spark中的宽窄依赖
什么是依赖关系?
- RDD会不断进行转换处理,得到新的RDD,每个RDD之间就产生了依赖关系
- 例如:A调用转换算子产生了B,那么我们称A为父RDD,称B为子RDD
什么是宽窄依赖?
- 窄依赖 Narrow Dependencies
- 定义:父RDD的一个分区的数据只给了子RDD的一个分区【不用调用分区器】
- 总结: 父分区和子分区的关系是一对一或者多对一的关系
- 宽依赖 Wide/Shuffle Dependencies
- 定义:父RDD的一个分区的数据给子RDD的多个分区【需要调用Shuffle的分区器来实现】
- 总结(特点): 父分区和子分区的对应是一对多的关系
面试:什么是宽窄依赖?为什么要设计宽窄依赖?
- 提高数据容错的性能,避免分区数据丢失时,需要重新构建整个RDD
- 场景:如果子RDD的某个分区的数据丢失
- 不标记:不清楚父RDD与子RDD数据之间的关系,必须重新构建整个父RDD所有数据
- 标记了:父RDD一个分区只对应子RDD的一个分区,按照对应关系恢复父RDD的对应分区即可
- 提高数据转换的性能,将连续窄依赖操作使用同一个Task都放在内存中直接转换
- 场景:如果RDD需要多个map、flatMap、filter、reduceByKey、sortByKey等算子的转换操作
- 不标记:每个转换不知道会不会经过Shuffle,都使用不同的Task来完成,每个Task的结果要保存到磁盘
- 标记了:多个连续窄依赖算子放在一个Stage中,共用一套Task在内存中完成所有转换,性能更快
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 微信
微信 支付宝
支付宝


