
【SparkCore】SparkOnYarn及RDD理论
Retrospect
书接上回,这次说说StandAlone的核心原理, 以及SparkOnYarn的执行流程(原理的说). 还有RDD算子的特性以及创建及分类
StandAlone原理
- 集群角色, 不管有没有任务运行,集群永远都有以下两个角色
- Master:管理,分配资源,监控worker的健康状况(相当于包工头)
- Worker: 分配资源,执行任务(相当于组长),向Master定时发送心跳包
- Task: 执行任务的(进程)相当于工人
Driver
- 1、每执行一个任务,Spark会自动启动一个Driver进程,类似于Yarn中AppMaster,负责整个任务执行的监控.当你启动10个Spark任务,系统就会启动10个Driver
- 2、Driver进程本身由于需要对整个任务进行管理,它本身也需要一定的资源,比如内存和CPU
Executor
- 1、每当你执行一个Spark任务,Spark需要启动若干个Executor进程,Executor用来管理执行执行任务的Task线程
- 2、Executor创建完成之后需要向Dirver进行注册
- 3、当执行任务时,需要多少个Executor可以手动指定,如果不指定,默认是2个,要启动多少个Executor一般需要根据数据量和集群的规模来决定,如果没有特殊的要求,一般是集群有多少台主机,就设置多少个Executor
1 | /export/server/spark/bin/spark-submit \ |
Task
- 1、Spark任务执行的最底层是一个个的Task线程,这些线程需要被分配到对应的Executor,被Executor管理
- 2、Task的个数由分区数或者文件的大小文件
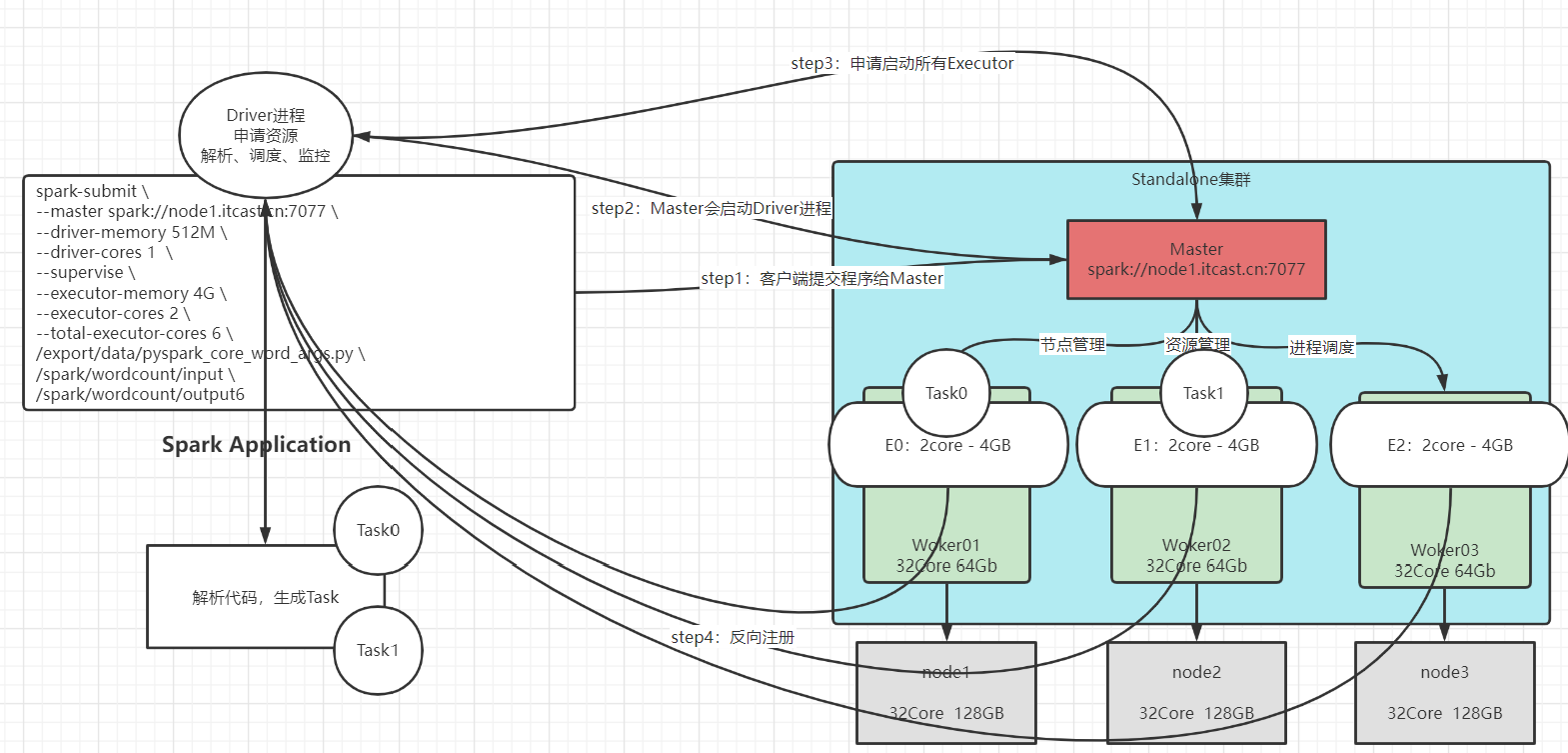
StandAlone任务执行流程
1、客户端提交程序给Master主节点
2、Master收到请求之后启动Driver进程(Dirver进程启动需要消耗内存和CPU资源)
3、Driver进程启动之后申请启动Executor进程(Executor进程启动需要消耗内存和CPU资源)
4、Executor进程启动之后向Driver进行反向注册
5、Driver解析你的代码,根据你的数据量来决定要启动几个线程,然后把这些线程交给Executor进程来执行
6、任务执行成功之后由Master释放资源
SparkOnYarn※
为什么使用SparkOnYarn
1、一般的大数据开发公司都有Hadoop集群,有Hadoop就一定有Yarn,没有必要再搭建一套额外资源调度平台否则,两套资源资源调度平台会相互竞争资源,不利于大数据分析。 2、Yarn本身可以为很多的计算引擎提供资源调度:MR,Tez,Spark,Flink 3、Yarn内部有很多资源调度策略:队列调度器、容量调度器、公平调度器
Spark On Yarn执行流程
谈到SparkOnYarn,必须要说的就是他的两种模式,一种是client模式,另外一种是cluster模式
注意, client模式是在测试环境中使用的, cluster模式是实际开发中使用的
两种运行模式的区别
1 | 1、Spark On Yarn 由两种运行模式:Client模式 和 Cluster模式 |
Client模式
1 | /export/server/spark/bin/spark-submit \ |
优点: 在Client模式下,任务执行的所有日志都通过外部网络汇集到客户端主机Dirver进程,看日志非常方便
缺点: 在Client模式下,由于所有的运行日志都要跨网络发送到客户端主机,会消耗大量的网络带宽(将相当于将所有的人日志从北京传往三亚),效率低
Cluster模式
1 | /export/server/spark/bin/spark-submit \ |
优点: 在Cluster模式下,由于所有的运行日志都是在集群内部传递,不会消耗大量的网络带宽(相当于将所有的人日志从北京传往北京),效率高
缺点: 在Cluster模式下,任务执行的所有日志都通过内部网络汇集集群内部Dirver进程所在主机,看日志不方便
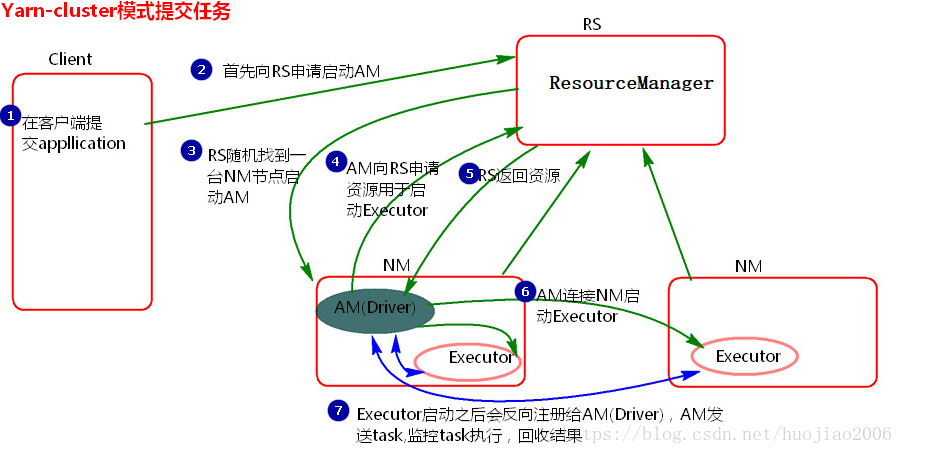
Spark On Yarn执行的流程※
- 客户端提交任务
- 客户端向RM申请AM
- RM创建AM,AM中内置Driver
- AM向RM申请资源用于启动Executor
- RM会返回给AM资源列表
- AM与相应的主机通信,启动Executor
- Executor向Driver反向注册
- Driver解析代码,将生成的Task线程分给Executor执行,并监控
- RM释放资源
1、客户端提交任务
2、客户端向ResourceManager申请启动AppMaster
3、ResourceManager随机找一台主机启动AppMaster,当AppMaster启动时,内置的Driver也会启动以下步骤和Client模式相同
4、AppMaster启动之后会向ResourceManager申请资源自动Executor
5、ResourceManager收到资源请求之后会给AppMaster返回资源列表清单
{
Executor01:node1
Executor01:node2
}
6、AppMaster收到资源列表之后,分别会列表中对应的主机通信,让其分配Executor所需资源,启动Executor
7、Executor启动之后会向Driver反向注册
8、反向注册之后,Driver会解析代码,将生成的Task线程分配给Executor执行,监控任务执行情况
9、任务执行从成功之后,由ResourceManager释放资源
Spark-RDD模型
RDD是什么: Resilient Distributed Dataset弹性分布式数据集.Spark的处理过程就是不同RDD之间迭代的过程
RDD的5个特性
特性1:每个RDD都由一系列的分区构成
特性2:RDD调用算子本质是RDD的每个分区在调用算子
特性3:每个RDD都会保存与其他RDD之间的依赖关系:血缘关系
- 1、每一个RDD都会记录该RDD的血缘关系(知道它是怎么来的,它的上一级是什么)
- 2、每次要获取一个RDD时,必须根据血缘关系,从头开始执行
特性4:可选的,Spark程序运行时,Task的分配可以指定实现最优路径解:最优计算位置
- Driver在分配每个Task给Executor时,会看看哪个Executor所在主机的数据离哪个Task最近,就会优先分配
特性五:可选的,如果是二元组【KV】类型的RDD,在Shuffle过程中可以自定义分区器
RDD的创建方式
RDD的创建有三种方式:
- 方式1:将本地列表转为RDD
sc.parallelize(list)- 方式2:将本地文件读取转为RDD
sc.textFile('file:///export/data/word.txt')- 方式3:将HDFS文件读取转为RDD
sc.textFile('hdfs://node1:8020/input/word.txt')
1 | # 创建RDD(三种RDD的创建方式 1, 将本地列表转换为RDD 2, 将本地文件转换为RDD 3,将HDFS文件转换为RDD |
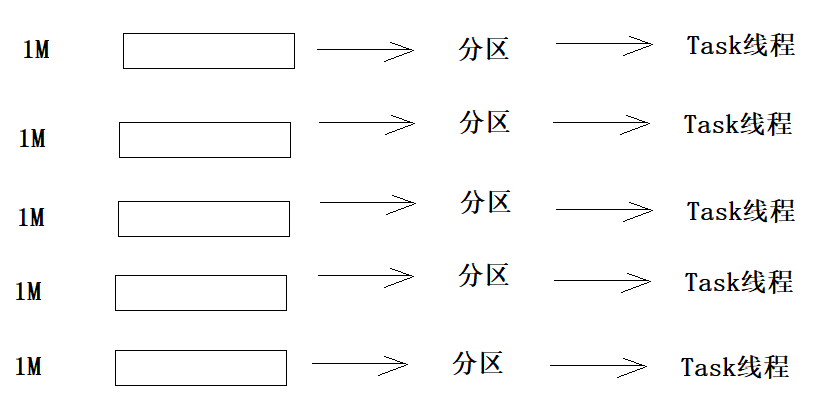
RDD的小文件处理方式
1 | 1、有100个小文件,每个文件不到1M的大小,需要用Spark对数据进行处理 |
使用算子wholeTextFiles可以将(同一个目录下的)很多小文件读取到一个RDD中, 键是文件的路径, 值是文件的内容.读取之后的数量可以手动来设置
1 | smallFile = sc.wholeTextFiles('hdfs://node1:8020/input/') |
RDD的分区理论
通过parallelize函数创建, 可以手动指定分区的数量,在未指定分区数量时: 本地模式的分区数是cpu的核数,Mesos默认分区数量为8, Yarn,StandAlone,K8s是主机核数,与2之间取最大值
- 本地模式的分区数是cpu的核数
- Mesos默认分区数量为8
- Yarn,StandAlone,K8s是主机核数,与2之间取最大值
END
 微信
微信 支付宝
支付宝