
【Spark】Spark本地与StandAlone模式
Anaconda
Anaconda是什么
1、Anaconda是一个工具包,里边包含了几百个开发工具,其中也包含Python
2、Anaconda还可以模拟多个虚拟环境,在该虚拟环境中可以安装不同版本的软件,多个虚拟环境彼此独立,以后你可以自由选择使用哪一个虚拟环境
3、你安装了Anaconda之后,自动会给你创建一个基础环境,名字为base
Anaconda常用命令
- 查看当前服务器安装的所有虚拟环境
conda env list- 创建新的虚拟环境
conda create -n 虚拟环境的名字 python=版本- 切换虚拟环境
conda activate 虚拟环境名称- 退出虚拟环境-进入上一个虚拟环境
conda deactivate- 删除某个虚拟环境
conda remove -n 虚拟环境名称 —all- 查看虚拟环境中安装的软件包
conda list- 卸载软件包
conda uninstall 包名 或pip uninstall 包名
Demo
1 | #查看当前服务器安装过哪些虚拟环境 |
SparkTemplete模板
创建模版
1 | 创建项目模板:File > Settings > Editor > File and Code Template > Python Script -->复制模板--->粘贴你的代码--->保存 |
讲解:
下面代码需要导入Pyspark包,这个包以及运行代码的解释器都是在Linux中的Anaconda中配置的
需要导入Pyspark包中的SparkContext及SparkConf,还有在后面设置JAVA_HOME等一系列环境变量
setMaster是集群的Master参数,setAppName位置填上运行任务的名称
- 集群StandAlone下参数为
spark://node1.itcast.cn:7077要用单引号引起来- 单机模式下的参数为
local[CPU核数]SparkContext中的参数是关键字参数,必须写
conf=
Templete模板
1 | from pyspark import SparkContext, SparkConf |
Pycharm开发Spark
- 首先删除Python中自带的解释器, 通过远端的解释器来解释本地写的Python文件
- 其次配置远端的解释器(Anaconda中虚拟环境的解释器)
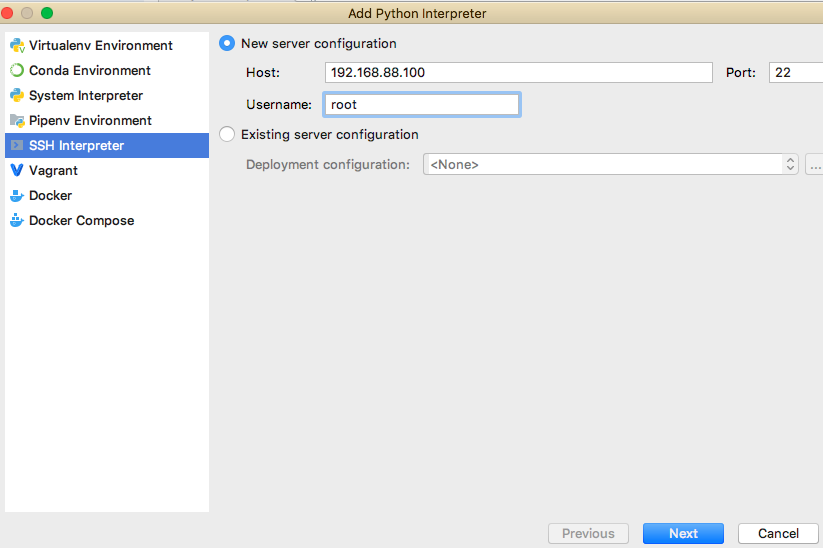
详情信息配置
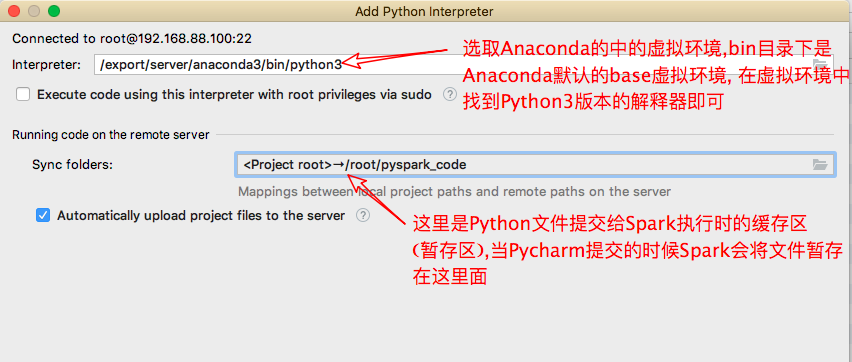
Spark本地模式
就是单机版
外部动态传参
1 | 1、写代码是,可以将输入和输出路径作为参数传入,而不是写死 |
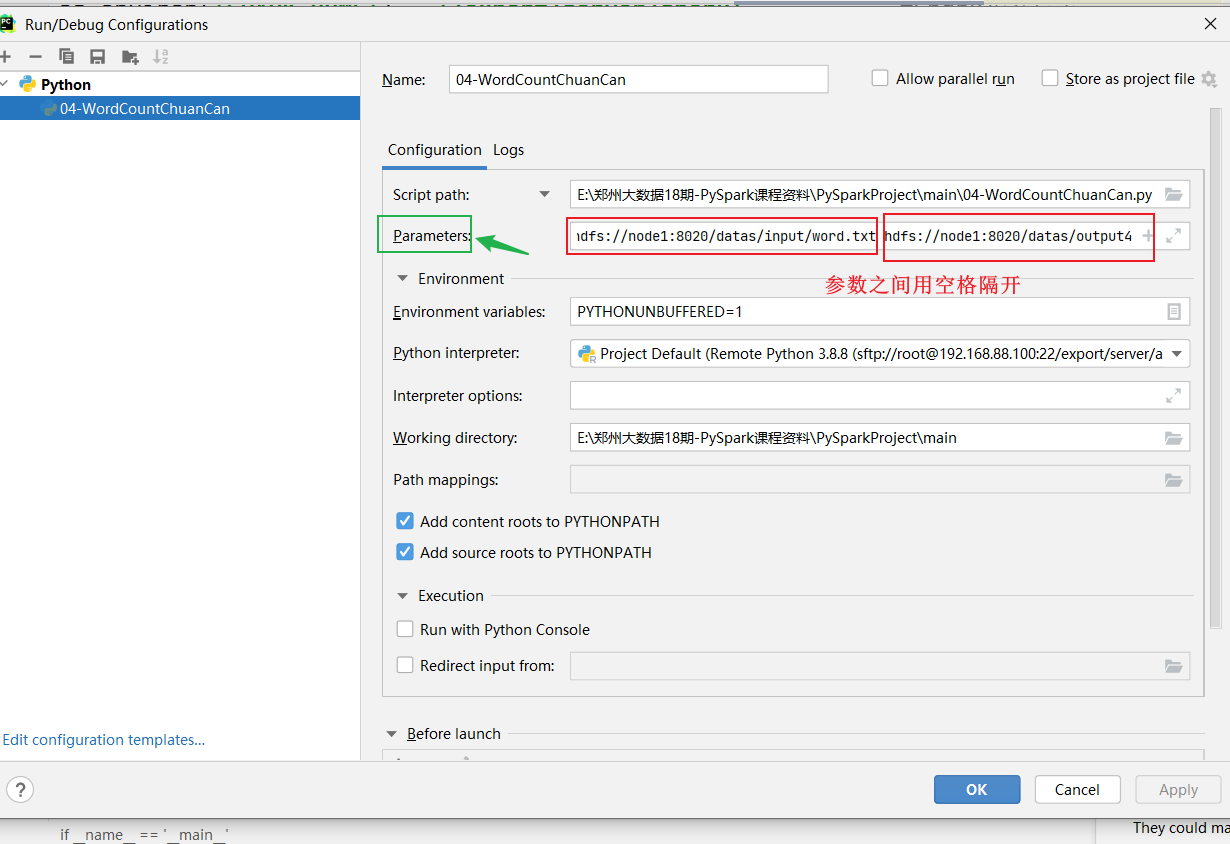
SparkStandAlone模式
介绍
1、StandAlone模式是:Spark引擎 + 自带的资源调度平台(master + work)
2、StandAlone是集群模式,每一台机器都要安装
架构
2
3
4
5
6
主节点:Master =等价于Yarn的ResourceManager
从节点:Worker =等价于Yarn的NodeManager
2、当一个Spark任务在StandAlone模式下执行时,会多出来一些组件
Executor进程 = 等价于Map进程和Reduce进程
Task线程 = 每一个Executor内部是由多个Task线程组成的
Master
1
2
3- 接受客户端请求:所有程序的提交,都是提交给主节点
- 管理从节点: 通过心跳机制检测所有的从节点的健康状态
- 资源管理和任务调度:将所有从节点的资源在逻辑上合并为一个整体,将任务分配给不同的从节点Worker
1
2- 使用自己所在节点的资源运行计算,计算时会启动Executor进程
- 所有Task线程计算任务就运行在Executor进程中
集群启动
在node1一键启动
1
2
3
4
5cd /export/server/spark/sbin
start-all.sh #启动Master和Worder
start-history-server.sh #启动历史服务在node1一键关闭
1
2
3
4
5cd /export/server/spark/sbin
stop-all.sh
stop-history-server.sh
网页验证
1 | http://node1:8080/ = Master的信息查看页面 |
SparkSubmit提交
StandAlone方式提交
2
3
4
5
#2、在linux上执行以下命令
/export/server/spark/bin/spark-submit \
--master spark://node1.itcast.cn:7077 \
/export/data/05-WordCountStandAlone.py本地模式提交
2
3
4
--master local[2] \
/export/server/spark/examples/src/main/python/pi.py \
100
常见的Master参数有:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18本地模式
--master local[2] =手动指定cpu核数为2
--master local[*] =你虚拟机有多少个虚拟核数,就用多少个虚拟核数
StandAlone模式
--单节点
--master spark://node1.itcast.cn:7077
--高可用
--master spark://node1.itcast.cn:7077,node2.itcast.cn:7077
Yarn模式
--master yarn
Mesos模式
--master mesos://node1:5050
K8s模式
--master k8s://node1:7888还有一些重要的参数
1
2
3
4
5
6
7--deploy-mode 任务的在集群运行模式(Client和Cluster)
--name 指定任务的名字
--num-executors 指定Executor个数
--executor-cores 指定Executor的CPU核数
--total-executor-cores 指定总的Executor核数
--executor-memory Executor所占内存大小
--driver-memory Driver所占内存大小WordCount案例
Linux文件版
1 | from pyspark import SparkContext,SparkConf |
HDFS版本
1 | from pyspark import SparkContext, SparkConf |
StandAlone模式下的HDFS版
1 | from pyspark import SparkContext, SparkConf |
SparkStandAlone的高可用
概述
1 | 1、高可用就是有两个master主节点,一个在node1上,一个在node2上 |
操作
关闭原集群
1 | /export/server/spark/sbin/stop-all.sh |
配置高可用
1.修改配置文件
1
2cd /export/server/spark/conf/
vim spark-env.sh1
2
3
4#注释以下内容
#SPARK_MASTER_HOST=node1.itcast.cn
#添加
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"2.分发
1
2
3cd /export/server/spark/conf
scp -r spark-env.sh node2:$PWD
scp -r spark-env.sh node3:$PWD3.启动ZK:三台机器都要启动
1
/export/server/zookeeper/bin/zkServer.sh start
4.启动Master
第一台
1
/export/server/spark/sbin/start-master.sh
第二台
1
/export/server/spark/sbin/start-master.sh
5.启动Worker
1
/export/server/spark/sbin/start-workers.sh
6.测试主备切换
1
2
3
4
5
6
7
8
9#1、查看网页
http://192.168.88.100:8080/ #主
http://192.168.88.101:8080/ #备
#2、测试主备切换
在node1上,kill原来的master
kill -9 master的进程号
查看 http://192.168.88.101:8080/ 页面的Status是否变成 ALIVE (可能需要等几分钟)
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 微信
微信 支付宝
支付宝