
【Spark】初识PySpark
初识Spark
按照知识点的重要性由高到低的顺序来进行归纳
分布式和集群
这个东西一下让你说,你不一定能说的出来,概括一下吧
分布式: 强调的是将一个系统的资源由单机分散到多台机器上,一个字拆
强调多台机器做一样的事情
Spark模块

1、SparkCore:是Spark框架的核心,其他所有组件都基于SparkCore
2、SparkSQL : 使用Spark + SQL语言来对大数据进行离线分析
3、Spark Structed Streaming : Spark的实时部分,需要结合Kafka
4、MLlib:Spark的机器学习库
5:Graph:Spark的图计算
集群部署模式
用的最多的就是Spark On Yarn模式 : Spark计算引擎 + Yarn调度器
1 | #1、本地模式(单机) |
Spark的特点和发展历史
- 特点
1、Spark是基于内存计算的计算引擎
2、Spark既可以用用于离线分析,也可以用于实时分析
3、Spark理论上可以支持PB级别数据量
- 发展历史
1、Spark是一个计算引擎,类似于之前学习的MapReduce和Presto
2、Spark是2009诞生于美国的加州大学伯克利分校
3、2013年Spark被捐献给Apache软件基金会
4、2017年Structured streaming发布,统一化实时与离线分布式计算平台
5、2018年Spark2.4.0发布,
6、2020年6月Spark发布3.0.0正式版工作年限:3年起步,版本使用2.4.2
工作年限:2年起步,版本使用3.1.2
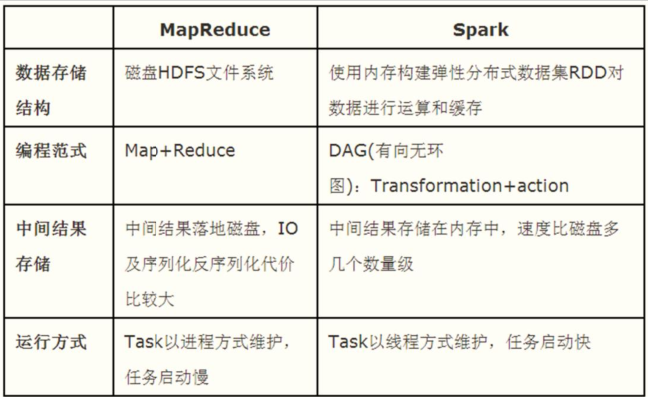
Spark和MapReduce的区别
1 | #进程和线程区别 |
调度: 进程是资源分配的基本单位, 线程是CPU调度的基本单位
并发性: 进程之间可以并发执行,多个线程之间也可以并发执行
拥有资源(地址空间):进程有自己独立的地址空间, 多个线程共享进程的地址空间.
包含关系: 一个线程包含多个进程
系统开销:在创建或撤消进程时的开销明显大于创建或撤消线程时的开销。
Spark环境的代码验证-单机版
1 | #1、定义列表 |
Spark环境的代码验证-分布式
- 使用glom函数可以查看数据的分布情况
- parallelize函数相当于将数据进行分布式存储了,存储到多个机器的内存中
- foreach函数是遍历,括号里面写的是函数lambda x: print(x)
- collect()函数相当于将分布的数据收回,但是收回的顺序可能会出现多种情况,因为数据到达的先后顺序不一样
1 | #1、定义列表 |
WordCount词频统计
数据准备
1 | vim /export/data/word.txt |
当我用五行代码写完就知道这只是个入门案例
- 从Linux本地中读取文件使用file://协议, 后面跟上Linux的路径,使用SparkContext简写
sc.textFile函数- 对文件中的空行进行过滤使用(可以叫rdd算子)
filter函数- 将读取到的数据RDD1进行分割(按照空格分割)使用
flatMap函数- 对两个RDD中的数据中的每个元素加上括号,并写成元组的形式使用
Map函数- 对RDD中的元素进行聚合使用
reduceByKey函数
- reduceByKey函数实际上是分为两步, 第一步得到(‘Hadoop’, [1, 1, 1, 1, 1])
- 然后将后面的1全部按照x+y的方式相加
1 | fileRdd = sc.textFile('file:///export/data/word.txt') |
链式编程
1 | # 读取数据 |
1 | # 另外一种写法 |
ReduceByKey算子的计算流程

WordCount全流程
[ ](https://postimg.cc/SjVtSx14)
](https://postimg.cc/SjVtSx14)
Spark提交Python文件
介绍
1 | 在实际的开发中,我们一般是在Pycharm中编写Spark代码,最后都是以py文件呈现,如果将写好的py文件提交给Spark执行,此时Spark提供一个spark-submit命令 |
使用方式
1 | /export/server/spark/bin/spark-submit \ |
 微信
微信 支付宝
支付宝