本文主要讲了数据抽取分为全量和增量抽取,以及拉链表的具体实现。
拉链表的公式:(旧的拉链表 left join 增量数据) union all 增量数据。
数据流向:业务数据库-> ODS,ODS->DWD
Hive中解决乱码问题 在MySQL中执行如下命令
1 2 3 4 5 6 7 8 9 use hive; show tables;alter table COLUMNS_V2 modify column COMMENT varchar (256 ) character set utf8;alter table TABLE_PARAMS modify column PARAM_VALUE varchar (4000 ) character set utf8;alter table PARTITION_PARAMS modify column PARAM_VALUE varchar (4000 ) character set utf8 ;alter table PARTITION_KEYS modify column PKEY_COMMENT varchar (4000 ) character set utf8;alter table INDEX_PARAMS modify column PARAM_VALUE varchar (4000 ) character set utf8;
ODS搭建 通过Sqoop做数据抽取的工作,尽量保证数据仓库和MySQL同样的数据粒度。
任何增量导入的第一步一定是全量导入。
还有区分ODS和DWD等层,是通过建立不同的数据库实现。
全量导入
注意:
全量覆盖导入 比如地区表,通常一个表的变化非常少,因为地名很少变嘛!(对于这种方式就用全量覆盖,通常一个月或者一个季度做一次)
1 2 3 4 5 6 7 8 /usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \ --connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \ --username root \ --password 123456 \ --query "select * from t_district where 1=1 and \$CONDITIONS" \ --hcatalog-database yp_ods \ --hcatalog-table t_district \ -m 1
Sqoop导入后如何验真?
总量校验:select * from 表名;
条件校验:select * from 表名 where id =1000;
样本校验:select * from 表名 tablesample(bucket 1 out of 2 on rand(gender));按照性别将数据分成两个桶,取第一份数据。rand(gender) 也可以写成 rand(1)— 指定随机数种子
增量导入(2种方式) 增量导入仅新增
在query中,where后面需要写上create_time between ‘2023-05-28 00:00:00’ and ‘2023-05-28 23:59:59’
1 2 3 4 5 6 7 8 9 /usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \ --connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \ --username root \ --password 123456 \ --query "select *, '2023-05-28' as dt from t_store where create_time between '2023-05-28 00:00:00' and '2023-05-28 23:59:59')and \$CONDITIONS" \ --hcatalog-database yp_ods \ --hcatalog-table t_store \ -m 1
增量导入新增+修改
1 2 3 4 5 6 7 8 9 10 11 12 /usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \ --connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \ --username root \ --password 123456 \ --query "select *, '2023-05-28' as dt from t_store where (create_time between '2023-05-28 00:00:00' and '2023-05-28 23:59:59') -- 新增数据 or (update_time between '2023-05-28 00:00:00' and '2023-05-28 23:59:59') -- 修改数据 and \$CONDITIONS" \ --hcatalog-database yp_ods \ --hcatalog-table t_store \ -m 1
Example:login_time between '2023-05-28 00:00:00' and '2023-05-28 23:59:59'
但是实际开发中要在Linux中
定义时间TD_DATE = date -d '1 days ago' + "%Y-%m-%d"
调用时间${TD_DATE}
例如:
1 2 3 4 5 6 7 8 /usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \ --connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \ --username root \ --password 123456 \ --query "select *, '${TD_DATE}' as dt from t_user_login where 1=1 and (login_time between '${TD_DATE} 00:00:00' and '${TD_DATE} 23:59:59') and \$CONDITIONS" \ --hcatalog-database yp_ods \ --hcatalog-table t_user_login \ -m 1
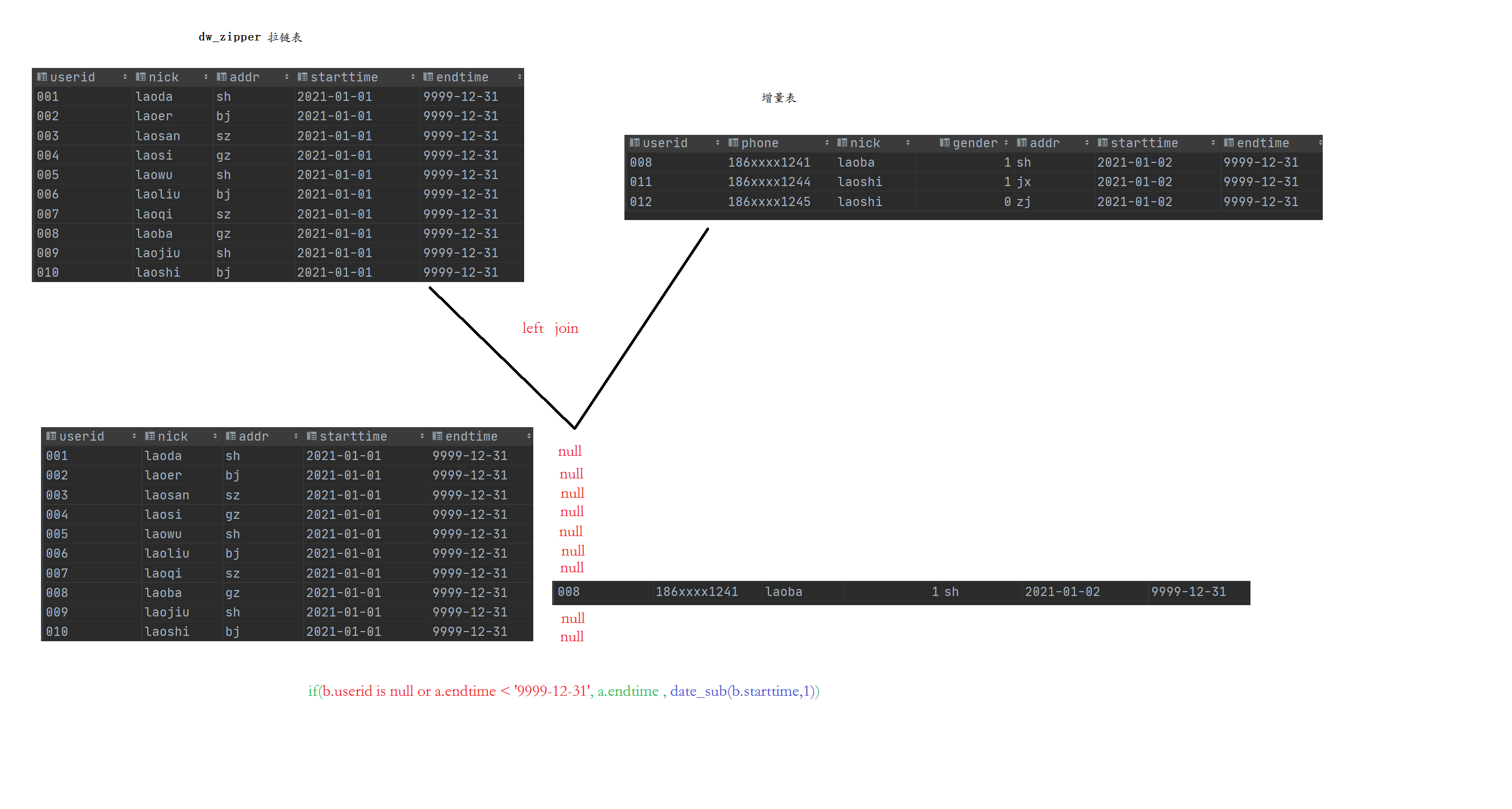
拉链表及实现
拉链表是缓慢渐变维的SCD2,showly changed dimension,是为了维护历史数据而产生的。
什么是维护历史数据,用户的居住地从杭州到北京,这段在杭州的时间就需要记录。(个人理解)
拉链表的公式:(旧的拉链表 left join 增量数据)union on 增量数据
解析:if (ozu.userid=null or d.endtime<’9999-12-31’,d.endtime,date_sub(ozu.starttime,1))
[是在left join中实现的]
以左表为基准进行join,
userid=nul说明增量表中没有这条数据,即这条数据没有被修改过
d.endtime < ‘9999-12-31’ 什么情况下会出现这种情况,我想一定是该拉链表中的endtime 已经被修改了,不是’9999-12-31’了,而是一个确定的时间,如(start_time - end_time)为2023-05-28 - 2023-05-29
最后一句,如果前面的or事件都没有发生,则是原表的endtime 否则是增量表的starttime - 1即通过date_sub函数实现
增量数据如何获取? 获取仅新增 1 2 3 select * from t_store where create_time between '2023-05-28 00:00:00' and '2023-05-28 23:59:59' )
获取新增和更新 1 2 3 4 select * from t_store where (create_time between '2023-05-28 00:00:00' and '2023-05-28 23:59:59' ) or (update_time between '2023-05-28 00:00:00' and '2023-05-28 23:59:59' )
这里模拟拉链表的实现 创建拉链表 1 2 3 4 5 6 7 8 9 10 create table dw_zipper( userid string, phone string, nick string, gender int , addr string, starttime string, endtime string ) row format delimited fields terminated by '\t' ;
创建增量表 1 2 3 4 5 6 7 8 9 10 create table ods_zipper_update( userid string, phone string, nick string, gender int , addr string, starttime string, endtime string ) row format delimited fields terminated by '\t' ;
获取最新的拉链表 1 2 3 4 5 6 7 8 9 10 11 12 select userid, phone, nick, gender, addr, starttime, if (ozu.userid= null or d.endtime< '9999-12-31' ,d.endtime,date_sub(ozu.starttime,1 )) as endtime from dw_zipper d left join ods_zipper_update ozu on d.userid = ozu.userid union all select * from ods_zipper_update;
将获取的新拉链表覆盖旧的 1 2 3 4 5 6 7 8 9 10 11 12 13 insert overwrite table zipperselect d.userid, d.phone, d.nick, d.gender, d.addr, d.starttime, if (ozu.userid= null or d.endtime< '9999-12-31' ,d.endtime,date_sub(ozu.starttime,1 )) as endtime from dw_zipper d left join ods_zipper_update ozu on d.userid = ozu.userid union all select * from ods_zipper_update;
DWD
DWD 层数据的三种导入方式:
方式一:拉链导入
适合场景:增量及更新同步表
表设计要求:start_date开始时间、end_date结束时间
start_date 表示数据有效的开始时间 可以作为表的分区字段来使用
end_date 表示数据失效的时间,默认数据都是9999-99-99 表示一直有效 。当有更新的时候,通过拉链表操作修改end_date。
典型代表:fact_shop_order 订单表、fact_order_settle订单结算表等
方式二:全量覆盖导入
适合场景:不考虑历史数据是否存在,每次导入直接覆盖表设计要求:没啥要求,也不用分区,也不用拉链。
典型代表:dim_district区域字典表、dim_date时间维度表
方式三:增量导入
适合场景:仅考虑每次的增量数据同步表设计要求:
分区表partitioned by (dt string),分区字段往往是时间日期。
一个日期一个分区,一次增量导入。
典型代表:fact_goods_evaluation订单评价表、fact_user_login登录记录表。
向分区表中添加字段,如果报错 1 2 3 4 5 SET hive.exec.dynamic.partition= true ;SET hive.exec.dynamic.partition.mode= nonstrict;set hive.exec.max.dynamic.partitions.pernode= 10000 ;set hive.exec.max.dynamic.partitions= 100000 ;set hive.exec.max.created.files= 150000 ;
增量导入(拉链导入)
因为DWD层的事实表是拉链表,且是一个动态分区表,将ODS层的数据导入DWD也就是导入到拉链表及动态分区表的一个过程。
建表SQL(拉链表)-订单事实表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 DROP TABLE if EXISTS yp_dwd.fact_shop_order;CREATE TABLE yp_dwd.fact_shop_order( id string COMMENT '根据一定规则生成的订单编号' , order_num string COMMENT '订单序号' , buyer_id string COMMENT '买家的userId' , store_id string COMMENT '店铺的id' , order_from string COMMENT '此字段可以转换 1.安卓\; 2.ios\; 3.小程序H5 \; 4.PC' , order_state int COMMENT '订单状态:1.已下单\; 2.已付款, 3. 已确认 \;4.配送\; 5.已完成\; 6.退款\;7.已取消' , create_date string COMMENT '下单时间' , finnshed_time timestamp COMMENT '订单完成时间,当配送员点击确认送达时,进行更新订单完成时间,后期需要根据订单完成时间,进行自动收货以及自动评价' , is_settlement tinyint COMMENT '是否结算\;0.待结算订单\; 1.已结算订单\;' , is_delete tinyint COMMENT '订单评价的状态:0.未删除\; 1.已删除\;(默认0)' , evaluation_state tinyint COMMENT '订单评价的状态:0.未评价\; 1.已评价\;(默认0)' , way string COMMENT '取货方式:SELF自提\;SHOP店铺负责配送' , is_stock_up int COMMENT '是否需要备货 0:不需要 1:需要 2:平台确认备货 3:已完成备货 4平台已经将货物送至店铺 ' , create_user string, create_time string, update_user string, update_time string, is_valid tinyint COMMENT '是否有效 0: false\; 1: true\; 订单是否有效的标志' , end_date string COMMENT '拉链结束日期' ) COMMENT '订单表' partitioned by (start_date string) row format delimited fields terminated by '\t' stored as orc tblproperties ('orc.compress' = 'SNAPPY' );
首次全量导入 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 SET hive.exec.dynamic.partition= true ;SET hive.exec.dynamic.partition.mode= nonstrict;set hive.exec.max.dynamic.partitions.pernode= 10000 ;set hive.exec.max.dynamic.partitions= 100000 ;set hive.exec.max.created.files= 150000 ;set hive.exec.compress.intermediate= true ;set hive.exec.compress.output= true ;set hive.exec.orc.compression.strategy= COMPRESSION;INSERT overwrite TABLE yp_dwd.fact_shop_order PARTITION (start_date)SELECT id, order_num, buyer_id, store_id, case order_from when 1 then 'android' when 2 then 'ios' when 3 then 'miniapp' when 4 then 'pcweb' else 'other' end as order_from, order_state, create_date, finnshed_time, is_settlement, is_delete, evaluation_state, way, is_stock_up, create_user, create_time, update_user, update_time, is_valid, '9999-99-99' end_date, dt as start_date FROM yp_ods.t_shop_order;
ODS层抽取新增、更新数据(Sqoop抽取) 1 2 3 4 select * from t_shop_order where create_time between '2023-05-29 00:00:00' and '2023-05-29 23:59:59' or update_time between '2023-05-29 00:00:00' and '2023-05-29 23:59:59' ;
1 2 3 4 5 6 7 8 /usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \ --connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \ --username root \ --password 123456 \ --query "select *, '2021-11-30' as dt from t_shop_order where 1=1 and (create_time between '2021-11-30 00:00:00' and '2021-11-30 23:59:59') or (update_time between '2021-11-30 00:00:00' and '2021-11-30 23:59:59') and \$CONDITIONS" \ --hcatalog-database yp_ods \ --hcatalog-table t_shop_order \ -m 1
创建中间临时表,用于保存拉链结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 DROP TABLE if EXISTS yp_dwd.fact_shop_order_tmp;CREATE TABLE yp_dwd.fact_shop_order_tmp( id string COMMENT '根据一定规则生成的订单编号' , order_num string COMMENT '订单序号' , buyer_id string COMMENT '买家的userId' , store_id string COMMENT '店铺的id' , order_from string COMMENT '此字段可以转换 1.安卓\; 2.ios\; 3.小程序H5 \; 4.PC' , order_state int COMMENT '订单状态:1.已下单\; 2.已付款, 3. 已确认 \;4.配送\; 5.已完成\; 6.退款\;7.已取消' , create_date string COMMENT '下单时间' , finnshed_time timestamp COMMENT '订单完成时间,当配送员点击确认送达时,进行更新订单完成时间,后期需要根据订单完成时间,进行自动收货以及自动评价' , is_settlement tinyint COMMENT '是否结算\;0.待结算订单\; 1.已结算订单\;' , is_delete tinyint COMMENT '订单评价的状态:0.未删除\; 1.已删除\;(默认0)' , evaluation_state tinyint COMMENT '订单评价的状态:0.未评价\; 1.已评价\;(默认0)' , way string COMMENT '取货方式:SELF自提\;SHOP店铺负责配送' , is_stock_up int COMMENT '是否需要备货 0:不需要 1:需要 2:平台确认备货 3:已完成备货 4平台已经将货物送至店铺 ' , create_user string, create_time string, update_user string, update_time string, is_valid tinyint COMMENT '是否有效 0: false\; 1: true\; 订单是否有效的标志' , end_date string COMMENT '拉链结束日期' ) COMMENT '订单表' partitioned by (start_date string) row format delimited fields terminated by '\t' stored as orc tblproperties ('orc.compress' = 'SNAPPY' )
拉链操作,将结果写入临时表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 insert overwrite table yp_dwd.fact_shop_order_tmp partition (start_date)select * from ( select id, order_num, buyer_id, store_id, case order_from when 1 then 'android' when 2 then 'ios' when 3 then 'miniapp' when 4 then 'pcweb' else 'other' end as order_from, order_state, create_date, finnshed_time, is_settlement, is_delete, evaluation_state, way, is_stock_up, create_user, create_time, update_user, update_time, is_valid, '9999-99-99' end_date, '2021-11-30' as start_date from yp_ods.t_shop_order where dt= '2021-11-30' union all select fso.id, fso.order_num, fso.buyer_id, fso.store_id, fso.order_from, fso.order_state, fso.create_date, fso.finnshed_time, fso.is_settlement, fso.is_delete, fso.evaluation_state, fso.way, fso.is_stock_up, fso.create_user, fso.create_time, fso.update_user, fso.update_time, fso.is_valid, if (tso.id is null or fso.end_date< '9999-99-99' , fso.end_date, date_add(tso.dt, -1 )) end_time, fso.start_date from yp_dwd.fact_shop_order fso left join (select * from yp_ods.t_shop_order where dt= '2021-11-30' ) tso on fso.id= tso.id ) his order by his.id, start_date;
查询临时表验证,并将结果覆盖拉链表 1 2 3 4 5 6 7 8 9 select * from yp_dwd.fact_shop_order_tmp where id= 'dd1910223851672f32' ; INSERT OVERWRITE TABLE yp_dwd.fact_shop_order partition (start_date) SELECT * from yp_dwd.fact_shop_order_tmp;
增量同步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 INSERT overwrite TABLE yp_dwd.fact_goods_evaluation PARTITION (dt)select id, user_id, store_id, order_id, geval_scores, geval_scores_speed, geval_scores_service, geval_isanony, create_user, create_time, update_user, update_time, is_valid, substr(create_time, 1 , 10 ) as dt from yp_ods.t_goods_evaluation;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 INSERT overwrite TABLE yp_dwd.fact_goods_evaluation PARTITION (dt)select id, user_id, store_id, order_id, geval_scores, geval_scores_speed, geval_scores_service, geval_isanony, create_user, create_time, update_user, update_time, is_valid, substr(create_time, 1 , 10 ) as dt from yp_ods.t_goods_evaluationwhere dt= 'xxxx-xx-xx' ;
全量覆盖
建表操作
1 2 3 4 5 6 7 8 9 10 11 DROP TABLE if EXISTS yp_dwd.dim_district;CREATE TABLE yp_dwd.dim_district( id string COMMENT '主键ID' , code string COMMENT '区域编码' , name string COMMENT '区域名称' , pid string COMMENT '父级ID' , alias string COMMENT '别名' ) COMMENT '区域字典表' row format delimited fields terminated by '\t' stored as orc tblproperties ('orc.compress' = 'SNAPPY' );
全量覆盖操作
1 2 3 INSERT overwrite TABLE yp_dwd.dim_districtselect * from yp_ods.t_districtWHERE code IS NOT NULL AND name IS NOT NULL ;

 微信
微信 支付宝
支付宝