
【Interview】ZooKeeper原理
以我一己之见,全篇将Zookeeper最重要的东西就是:
Watch监听机制(如何实现主备切换,即热备知道老大宕机了)。
Leader选举机制(过半原则:Paxos算法)。
SSH免密登陆原理(非对称加密-公钥加密,私钥解密)
Zookeeper简介及用途
ZooKeeper,它是一个开放源码的分布式协调服务,它是一个集群的管理者,它将简单易用的接口提供给用户。
可以基于Zookeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
Zookeeper的用途:命名服务、配置管理、集群管理、分布式锁、队列管理
概述
ZooKeeper概念: Zookeeper是一个分布式协调服务的开源框架。本质上是一个分布式的小文件存储系统
ZooKeeper作用: 主要用来解决分布式集群中应用系统的一致性问题。
ZooKeeper结构: 采用树形层次结构,ZooKeeper树中的每个节点被称为—Znode。且树中的每个节点可以拥有子节点
特性
全局数据一致:集群中每个服务器保存一份相同的数据副本,client无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征;可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受。
顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态;
实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
ZooKeeper角色及作用
主节点的作用: Leader
1.负责管理整个集群,即保证数据的全局一致性
2.负责数据事务(增删改)相关的操作.
3.转发数据非事务操作给从节点.
从节点的作用: Follower
1.实时从主节点拉取数据,保持数据的一致性.
2.负责数据非事务(读)相关的操作.
3.转发数据事务操作给主节点.
Observer的作用:
除了没有选举权,其他和Follower-样
ZooKeeper命令
启动zookeeper服务
启动服务 zkServer.sh start
查看状态zkServer.sh status
如果想关闭可以使用stopzkServer.sh stop
查看所有shell命令:help
常见命令解释:
ls path [watch] : 查看节点信息
get path [watch]: 获取数据
ls2 path [watch]: 查看节点详情信息
create [-s] [-e] path data acl: 创建数据节点
delete path [version]: 删除节点
rmr path: 删多层除节点
set path data [version] :设置/修改节点数据
history: 查看操作历史
quit: 退出
ZNode节点类型
Znode兼具文件和目录两种特点是非常吊的好吧!
Znode兼具文件和目录两种特点: Znode没有文件和目录之分,Znode既有向文件一样存储数据,也能像目录一样作为路径标识的一部分
Znode具有原子性操作: 读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据
Znode存储数据大小有限制: 每个Znode的数据大小至多1M,当时常规使用中应该远小于此值
Znode通过路径引用: 路径必须是绝对的,因此他们必须由斜杠字符来开头。除此以外,他们必须是唯一的,也就是说每一个路径只有一个表示,因此这些路径不能改变。 默认有/zookeeper节点用以保存关键的管理信息。
按照存活时间分类
按照存活时间分,Znode有两种,分别为 永久节点 和 临时节点(Ephemeral) 。节点的类型在创建时即被确定,并且不能改变。
永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
- 注意: 永久节点可以拥有子节点
创建永久节点: create /节点名 节点值
临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话结束,临时节点将被自动删除,也可手动删除。
- 注意: 临时节点不允许拥有子节点。
创建临时节点: create -e /节点名 节点值
按照有无序列号分类
分为有序(Sequential)节点和无序节点
序列化节点: Znode还有一个序列化的特性,就是如果创建的时候加 -s 指定的话,该Znode的名字后面会自动追加一个不断增加的序列号。
创建永久序列化节点: create -s /节点名 节点值
创建临时序列化节点: create -e -s /节点名 节点值
ZNode节点属性
每个znode都包含了一系列的属性,通过命令**get /节点名**,可以获得节点的属性
事务ID介绍
对于zk来说,每次的变化都会产生一个唯一的事务id,zxid(ZooKeeper Transaction Id)。通过zxid,可以确定更新操作的先后顺序。例如,如果zxid1小于zxid2,说明zxid1操作先于zxid2发生,zxid对于整个zk都是唯一的,即使操作的是不同的znode。
MyID介绍
一般是由机器自己创建的文件中存放MyId值
路径在Zookeeper安装路径下/export/server/zookeeper/zkdatas/myid 文件中
其他信息(了解)
cZxid :Znode创建的事务id。
ctime :Znode创建时的时间戳.
mZxid :Znode被修改的事务id,即每次对当前znode的修改都会更新mZxid。
mtime :Znode最新一次更新发生时的时间戳.
pZxid :Znode的子节点列表变更的事务ID,添加子节点或删除子节点就会影响子节点列表
cversion :子节点进行变更的版本号。添加子节点或删除子节点就会影响子节点版本号
dataVersion:数据版本号,每次对节点进行set操作,dataVersion的值都会增加1(即使设置的是相同的数据),可有效避免了数据更新时出现的先后顺序问题。
aclVersion : 权限变化列表版本 access control list Version
ephemeralOwner : 字面翻译临时节点拥有者,持久节点值为0,非持久节点不为0(会话ID)
dataLength : Znode数据长度
numChildren: 当前Znode子节点数量(不包括子子节点)
监听机制
Watch监听机制格式: get /节点名 watch
Watch监听机制特点:
先注册再触发: Zookeeper中的watch机制,必须客户端先去服务端注册监听,这样事件发送才会触发监听,通知给客户端
一次性触发: 事件发生触发监听,一个watcher event就会被发送到设置监听的客户端,这种效果是一次性的,后续再次发生同样的事件,不会再次触发。
异步发送: watcher的通知事件从服务端发送到客户端是异步的。
通知内容: 通知状态(keeperState),事件类型(EventType)和节点路径(path)
应用场景
数据发布/订阅系统,就是发布者将数据发布到ZooKeeper的一个节点上,提供订阅者进行数据订阅,从而实现动态更新数据的目的,实现配置信息的集中式管理和数据的动态更新。
Leader选举
选举要求: 过半原则,所以搭建集群一般奇数,只要某个node节点票数过半立刻成为leader
集群第一次启动(新集群)
启动follower每次投票后,他们会相互同步投票情况,如果票数相同,谁的myid大,谁就当选leader
一旦确定了leader,后面来的默认就是follower,即使它的myid大,leader也不会改变(除非leader宕机了)
leader宕机后启动(旧集群)
每一个leader当老大的时候,都会产生新纪元epoch,且每次操作完节点数据都会更新事务id(高32位_低32位) ,当leader宕机后,剩下的follower就会综合考虑几个因素选出最新的leader
先比较最后一次更新数据事务id(高32位_低32位),谁的事务id最大,谁就当选leader
如果更新数据的事务id都相同的情况下,就需要再次考虑myid,谁的myid大,谁就当选leader
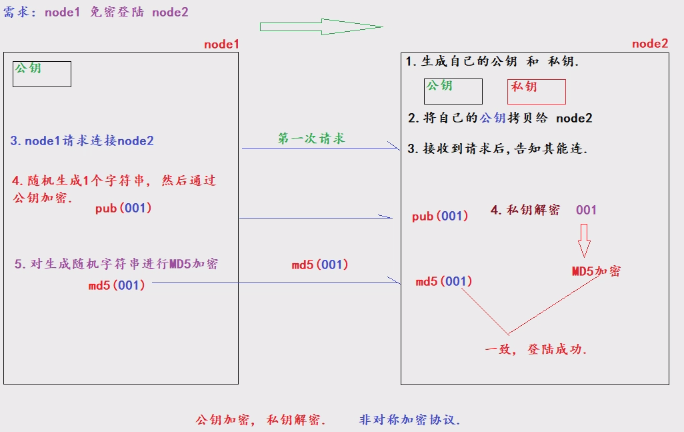
SSH免密登陆
假设两台服务器,node1和node2
node2有自己的公钥和私钥(是一对),node1要给node2发送消息必须知道node2的公钥。
node1将发送的消息(nihao)通过公钥加密,并将数据发送个node2
node2用自己的私钥进行解密得到数据(nihao)
node1将刚发送的字符串(nihao)通过md5-不可逆加密,并发送给node2
node2将自己得到的数据也进行md5加密,然后和node1发送的MD5比对,一致则数据没问题
 微信
微信 支付宝
支付宝



