
HDFS及上手Hive
HDFS的常见shell命令
Summary(总结)
第一点:书写HDFS的shell命令大致就是在shell的基础上在开头添加Hadoop fs 或者hdfs dfs这种,并且在命令起始添加 - 。
第二点:基础命令中只有put,get命令,还有appendToFile命令是Linux路径和HDFS路径进行交互的。
1 | HDFS的Shell命令指的是, 在CRT 或者 Tabby等工具中, 写Shell命令, 操作HDFS文件系统. |
HDFS的三个机制:
心跳机制 负载均衡机制 副本机制
心跳机制:心跳机制是DataNode会每隔3秒向Namenode定时发送一个自定义的结构体(心跳包),让对方知道自己还活着,以确保连接的有效性的机制。但是Namenode不必回应,当Namenode连续30秒(10次)没有收到心跳包,会初步判断DataNode可能宕机,此时Namenode会每隔5分钟向DataNode发送确认消息,连续两次(10分钟)没有收到DataNode回应就会认为DataNode宕机了
负载均衡机制:Namenode为了保证每个DataNode上所存储的块的信息大体一样,分配存储任务时,会优先分配DataNode余量比较大的DataNode上。
副本机制:为了保证数据的安全和效率,block块会有多个副本(一般是2-5个),第一副本优先存储在客户端所在服务器,否则就近随机,第二副本保存在与第一副本相邻且不同机架的服务器上,第三副本保存在跟第二副本相同机架的不同服务器上。作用是提升数据的可靠性,保证数据不丢失,但是会导致占用更多的磁盘空间,冗余较大
Hive是什么?
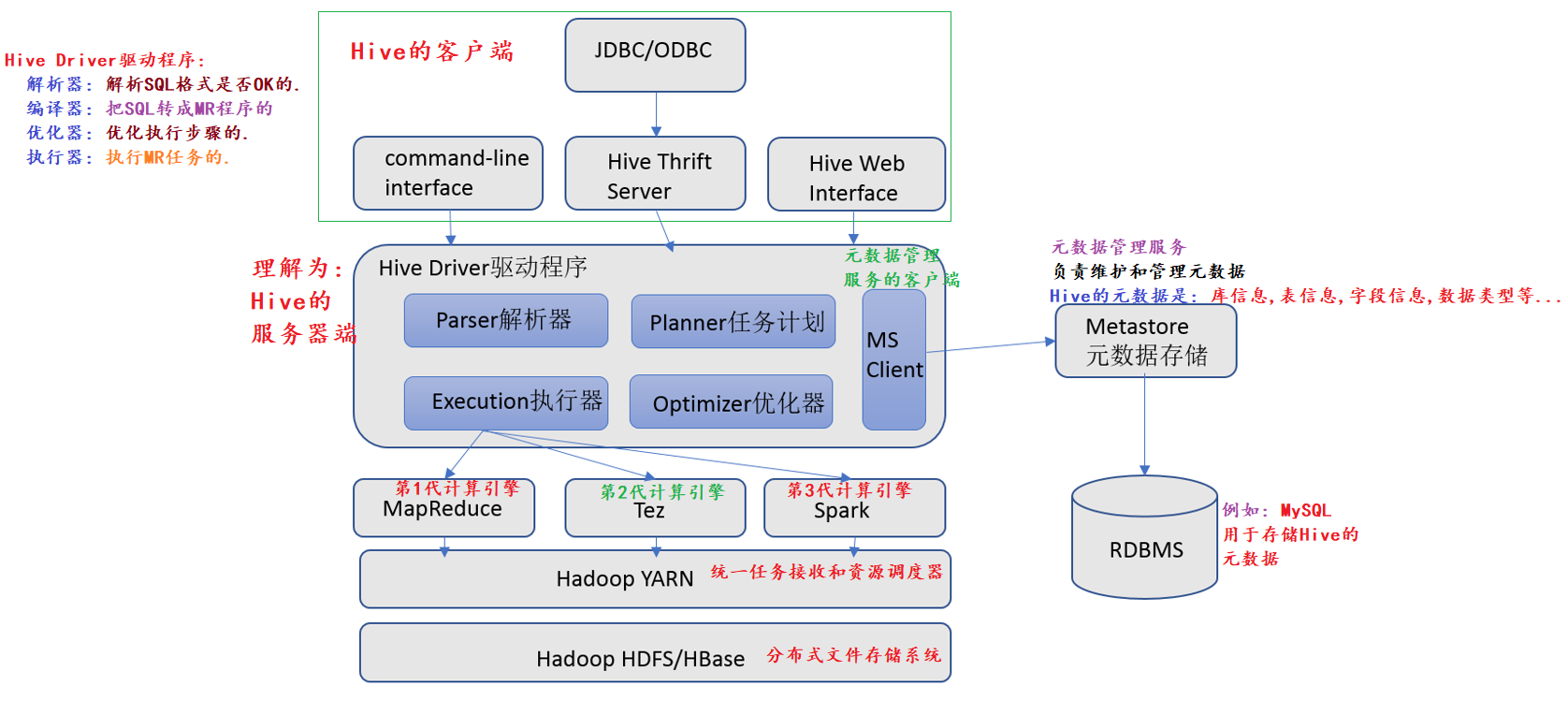
HiveDriver驱动程序:解析器:解析SQL格式是否OK的。
编译器:把SQL转成MR程序的优化器:优化执行步骤的。
执行器:执行MR任务的。
hive执行步骤
用户通过client 提交SQL
hive driver 驱动器
SQL解析器,将SQL转换成抽象语法树,读取mysql中的元数据进行解析
元数据:数据的位置,数据的分隔符,权限信息,文件大小,创建时间等。
编译器,将抽象语法树转换成逻辑执行计划
优化器,将逻辑执行计划转换成优化的逻辑执行计划
执行器,将逻辑执行计划转换成要执行mapreduce或者spark执行job
提交给mapreduce分布式计算
mapreduce会读取分布式文件系统中的数据
最终结果会返回给 client
为什么使用 hive?
MR程序的两个弊端是什么
开发难度相对较大. # 通过Hive解决, 写SQL => 底层自动转MR程序.执行速度相对较慢. # 换计算引擎, 例如: Presto, Spark, Flink…
直接使用hadoop所面临的问题
1、人员学习成本太高
2、项目周期要求太短
3、MapReduce实现复杂查询逻辑开发难度太大
为什么要使用Hive
1、操作接口采用类SQL语法,提供快速开发的能力
2、避免了去写MapReduce,减少开发人员的学习成本
3、功能扩展很方便
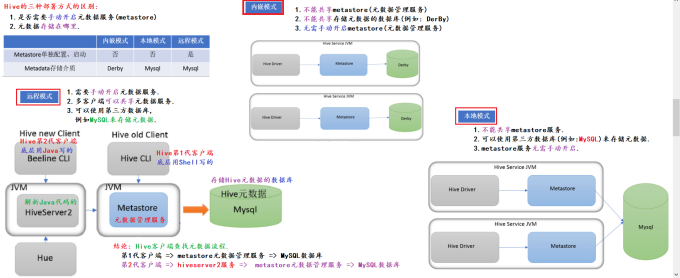
Hive部署方式
部署方式有三种, 分别是: 内嵌模式, 本地模式, 远程模式
内嵌(不需要了解) 本地(会配置) 远程(生产环境)
三种部署方式的区别:
内嵌模式:
1.不能共享metastore(元数据管理服务)
2.不能共享存储元数据的数据库(例如:DerBy)
3.无需手动开netastore(元收据管理服务)
本地模式:
1.不能共享metastore服务
2.可以使用第三方数据库(例如:MySQL)来存储元数据,
3.metastore服务无需手动开启
远程模式:※
1.需要手动开启元数据服务。
2.多客户端可以其享元数据服务,
3.可以使用第三方数据库,例如MySQL来存储元数据,
上手Hive
Hive第一代(shell编写)
访问第一代Hive的方式是通过开启metastore元数据管理服务直接访问MySQL数据库。
配置Hive的path环境变量
1 | Linux环境变量配置文件 |
细节: Hive强依赖与Hadoop, 所以启动hive之前先启动Hadoop, 即: start-all.sh
启动Hive
两种启动方式:前后台启动
1 | 前台启动 |
Hive第2代客户端
确保你已经成功的开启了Hadoop集群 和 metastore服务
1 | start-all.sh |
DataGrip连接Hive
1 | DataGrip连接Hive底层其实是 beeline的方式, 所以你必须确保集群开启了 |
数据仓库概述
数据仓库介绍
全称叫Data WareHouse, 简称叫 DW, DWH, 就是用来存储数据的, 以便于做分析用.数仓的数据可以是: 业务数据, 日志数据, 第三方数据, 爬虫数据等.
数据仓库的目的
数据仓库的目的是把各种数据源整合到一起, 方便做数据分析用, 即: 从海量的数据中提取出有价值的信息, 实现数据的商业化, 价值化, 给企业决策者或者运营人员提供数据支持 或者 分析型报告.
OLTP (Online Transaction Processing)
联机事务处理一般指的是数据库
面向业务的, 主要是做数据采集用, 按照业务采集数据, 一般处理的是 在线(实时)数据. 数据量相对较小, 对数据的时效性要求较高, 且大多数操作都是 增删改查
OLAP(Online Analytical Processing)
联机分析处理 -> 一般指的是数仓
面向主题的, 主要是做数据分析用的, 一般处理的是 历史(离线)数据. 数据量相对较大, 对数据的时效性要求相对较低, 且大多数操作主要是 查询.
数仓的特点是什么?
面向主题. # 数仓都是面向主题开展分析的, 不然无意义.集成性.# 数仓可以集多种数据源(业务数据, 日志数据, 第三方数据, 爬虫数据等)于一体非易失性.# 数仓分析的主要是离线数据, 离线数据 = 不可修改的数据.时变性.# 随着业务的增加和调整,数据源也会发生变化, 数仓也要相应的做出调整.
经典的数仓分层
ODS(源数据层, 贴源层), DW(数仓层), DA(数据应用层)
ETL 和 ELT的区别是什么?
ETL: 旧式数仓架构, 即: 先抽取(Extact), 再转换(Transform), 再存储(Load)方式. 弊端: 可能会把后续要用的数据给清理掉.ELT: 新式数仓架构, 先抽取(Extract), 然后直接存储数仓中(Load), 最后在用什么就转换什么.
HQL
DDL语句–操作数据库
1 | -- Hive SQL(以下简称HQL) 跟 MySQL语句一样, 也是划分为四种, 分别是: |
 微信
微信 支付宝
支付宝

