
Mysql分表操作+Case_When+PyMysql
分表操作
为什么要分表,一个表不好吗?
这要从范式说起。
数据库系统概论里面是这样说的:
- 第一范式(1NF):字段不可分;
- 第二范式(2NF):有主键,非主键字段依赖主键;
- 第三范式(3NF):非主键字段不能相互依赖。
可能是我太菜了,看不懂,那就自己总结一下。
1NF(原子性)==> 所有字段不可再分比如:
姓名 个人信息 张三 12岁,5年级,二班,男 这种就是不符合第一范式的,起码要将年级,班级,年龄,性别分为几个不同的字段。
2NF(唯一性)==> 一个表只能说明一个事物比如:
学号 姓名 年龄 课程名称 成绩 学分 这个表就不符合第二范式,因为这个表明显说明了两个事务:学生信息, 课程信息。
- 这个不符合第二范式的表会导致如下问题:
- 数据冗余:每条记录都含有相同信息,比如课程名称相同,需要占用很多存储空间
- 删除异常:删除所有学生成绩,就把课程信息全删除了,这种就很难受
- 插入异常:学生未选课,数据库中的数据不完整会导致插入不进去
- 更新异常:调整课程学分,所有行都调整
3NF ==> 每列都与主键有直接关系,不存在传递依赖
学号 姓名 年龄 所在学院 学院联系电话 不符合第三范式,因为学院联系电话依赖于所在学院,而所在学院又依赖于学号
而其中关键字为单一关键字”学号”。存在依赖传递::(学号) → (所在学院) → (学院联系电话)
会导致如下问题
- 数据冗余:每条记录都含有相同信息
- 删除异常:删除所有学生信息,就把院校信息删除了
什么是分表?
假设有这样一个表(goods-商品表):
| id | name | category_name | brand_name |
|---|---|---|---|
| 1 | x3250 m4机架式服务器 | 服务器/工作站 | ibm |
| 2 | x550cc 15.6英寸笔记本 | 笔记本 | 华硕 |
| 3 | r510vc 15.6英寸笔记本 | 笔记本 | 华硕 |
可以看到category_name和brand_name中有冗余的数据。
可不可以用数字id表示category_name和brand_name呢,答案是肯定的。
数据准备:goods表
1 | create table goods( |
分表之创建商品种类表 goods_cates
四步走:
- 第一步 创建 “商品品牌表” 表(两个字段id,name)
- 第二步 插入数据 brand_name到商品种类表 goods_cates中
- 第三步 同步 商品表 数据 通过 goods_cates 数据表来更新 goods 表
- 第四步 修改 goods 表结构
1 | # 第一步 创建表 (商品种类表 goods_cates) |
分表之创建商品品牌表 goods_brands
1 | # 创建 商品品牌表 goods_brands |
Python操作数据库
首先要下载pymyql依赖包,然后import pymysql导包
使用Python操作数据库要分几步
1,创建连接 conn = pymysql.connect(主机,端口,用户,密码,数据库,字符集)
2,创建游标 cur = conn.cursor()
3,书写sql 直接写
4,执行SQL cur.execute(sql)**
1 | import pymysql |
SQL之CASE_WHEN_ELSE_END
数据准备的SQL文件可以去我的博客园下载,下载链接
直接解压将sql文件拖动到DataGrip中,然后生成如下几张表,其中的关系如下: 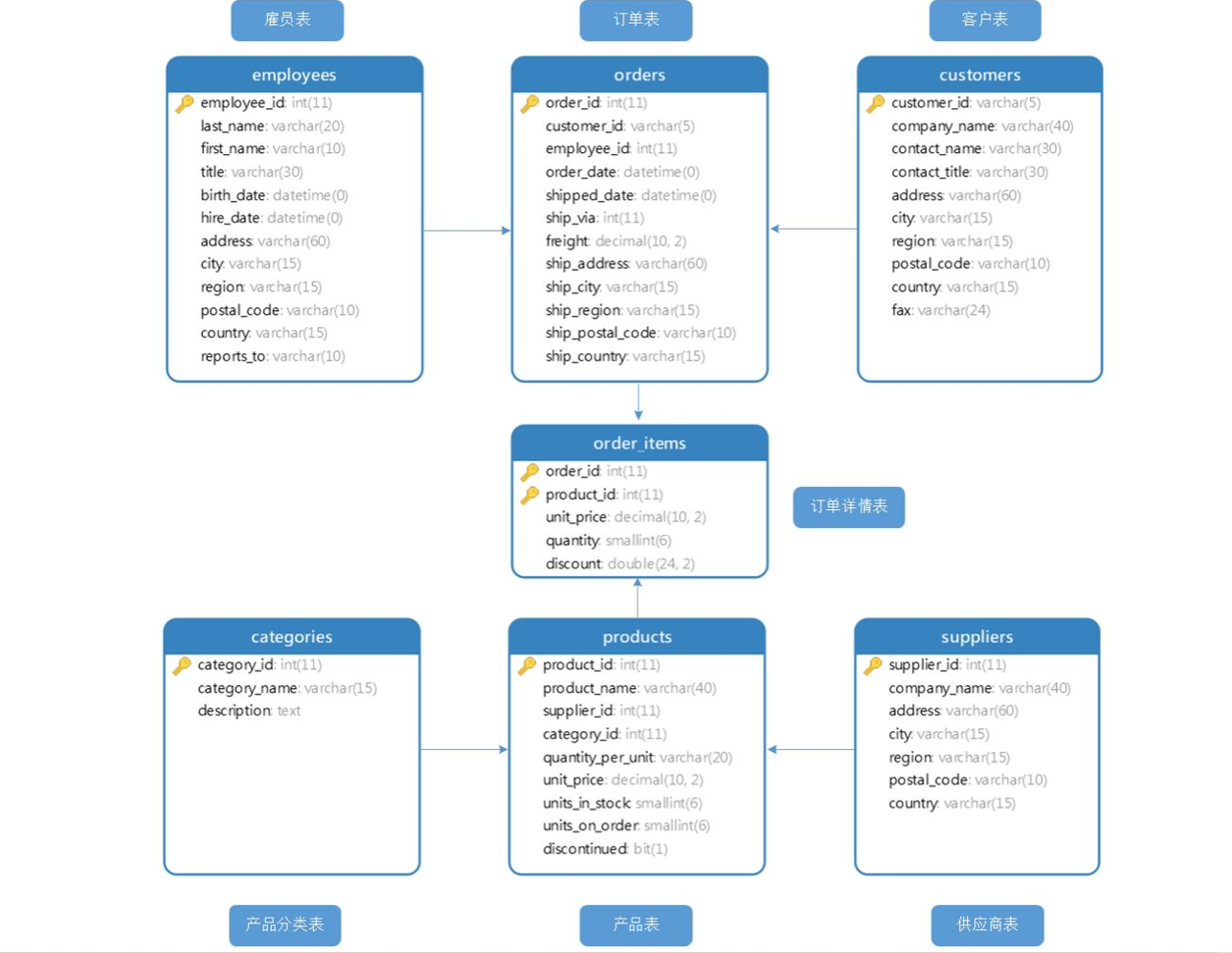
各个表的含义如下
employees员工表 记录了Northwind所有员工信息.customers客户表,记录了客户相关信息.products记录了商品信息.categories记录了商品类别信息.suppliers记录了商品供应商信息.orders记录了Northwind的顾客下的订单.order_items记录了订单中的每一件商品明细.
题目摘要
练习5(多表关联提取订单编号为10250的订单详情)
练习8(时间的用法)统计2013年入职的员工数量,统计字段起别名 number_of_employees
练习15(CASE-WHEN-THEN-END 的使用)需求: 创建一个报表,统计员工的经验水平
练习25(CASE-WHEN-THEN-ELSE-END 的使用)需求:创建报表将所有产品划分为素食和非素食两类
1 | # 练习5(多表关联提取订单编号为10250的订单详情) |
 微信
微信 支付宝
支付宝